 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSponsored is the New Organic: Implications of Sponsored Results on Quality of Search Results in the Amazon Marketplace
Jul 26, 2024



Interleaving sponsored results (advertisements) amongst organic results on search engine result pages (SERP) has become a common practice across multiple digital platforms. Advertisements have catered to consumer satisfaction and fostered competition in digital public spaces; making them an appealing gateway for businesses to reach their consumers. However, especially in the context of digital marketplaces, due to the competitive nature of the sponsored results with the organic ones, multiple unwanted repercussions have surfaced affecting different stakeholders. From the consumers' perspective the sponsored ads/results may cause degradation of search quality and nudge consumers to potentially irrelevant and costlier products. The sponsored ads may also affect the level playing field of the competition in the marketplaces among sellers. To understand and unravel these potential concerns, we analyse the Amazon digital marketplace in four different countries by simulating 4,800 search operations. Our analyses over SERPs consisting 2M organic and 638K sponsored results show items with poor organic ranks (beyond 100th position) appear as sponsored results even before the top organic results on the first page of Amazon SERP. Moreover, we also observe that in majority of the cases, these top sponsored results are costlier and are of poorer quality than the top organic results. We believe these observations can motivate researchers for further deliberation to bring in more transparency and guard rails in the advertising practices followed in digital marketplaces.
Auditing the Grid-Based Placement of Private Label Products on E-commerce Search Result Pages
Jul 19, 2024



E-commerce platforms support the needs and livelihoods of their two most important stakeholders -- customers and producers/sellers. Multiple algorithmic systems, like ``search'' systems mediate the interactions between these stakeholders by connecting customers to producers with relevant items. Search results include (i) private label (PL) products that are manufactured/sold by the platform itself, as well as (ii) third-party products on advertised / sponsored and organic positions. In this paper, we systematically quantify the extent of PL product promotion on e-commerce search results for the two largest e-commerce platforms operating in India -- Amazon.in and Flipkart. By analyzing snapshots of search results across the two platforms, we discover high PL promotion on the initial result pages (~ 15% PLs are advertised on the first SERP of Amazon). Both platforms use different strategies to promote their PL products, such as placing more PLs on the advertised positions -- while Amazon places them on the first, middle, and last rows of the search results, Flipkart places them on the first two positions and the (entire) last column of the search results. We discover that these product placement strategies of both platforms conform with existing user attention strategies proposed in the literature. Finally, to supplement the findings from the collected data, we conduct a survey among 68 participants on Amazon Mechanical Turk. The click pattern from our survey shows that users strongly prefer to click on products placed at positions that correspond to the PL products on the search results of Amazon, but not so strongly on Flipkart. The click-through rate follows previously proposed theoretically grounded user attention distribution patterns in a two-dimensional layout.
Investigating Nudges toward Related Sellers on E-commerce Marketplaces: A Case Study on Amazon
Jul 01, 2024



E-commerce marketplaces provide business opportunities to millions of sellers worldwide. Some of these sellers have special relationships with the marketplace by virtue of using their subsidiary services (e.g., fulfillment and/or shipping services provided by the marketplace) -- we refer to such sellers collectively as Related Sellers. When multiple sellers offer to sell the same product, the marketplace helps a customer in selecting an offer (by a seller) through (a) a default offer selection algorithm, (b) showing features about each of the offers and the corresponding sellers (price, seller performance metrics, seller's number of ratings etc.), and (c) finally evaluating the sellers along these features. In this paper, we perform an end-to-end investigation into how the above apparatus can nudge customers toward the Related Sellers on Amazon's four different marketplaces in India, USA, Germany and France. We find that given explicit choices, customers' preferred offers and algorithmically selected offers can be significantly different. We highlight that Amazon is adopting different performance metric evaluation policies for different sellers, potentially benefiting Related Sellers. For instance, such policies result in notable discrepancy between the actual performance metric and the presented performance metric of Related Sellers. We further observe that among the seller-centric features visible to customers, sellers' number of ratings influences their decisions the most, yet it may not reflect the true quality of service by the seller, rather reflecting the scale at which the seller operates, thereby implicitly steering customers toward larger Related Sellers. Moreover, when customers are shown the rectified metrics for the different sellers, their preference toward Related Sellers is almost halved.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
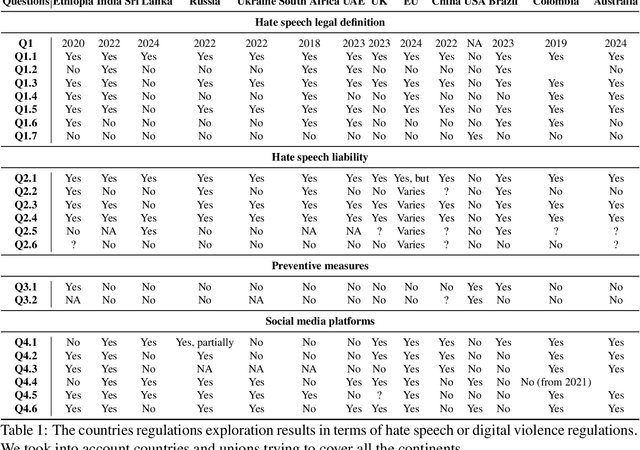
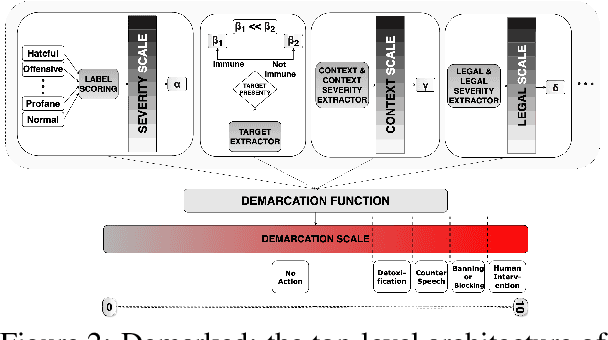

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
SafeInfer: Context Adaptive Decoding Time Safety Alignment for Large Language Models
Jun 18, 2024



Safety-aligned language models often exhibit fragile and imbalanced safety mechanisms, increasing the likelihood of generating unsafe content. In addition, incorporating new knowledge through editing techniques to language models can further compromise safety. To address these issues, we propose SafeInfer, a context-adaptive, decoding-time safety alignment strategy for generating safe responses to user queries. SafeInfer comprises two phases: the safety amplification phase, which employs safe demonstration examples to adjust the model's hidden states and increase the likelihood of safer outputs, and the safety-guided decoding phase, which influences token selection based on safety-optimized distributions, ensuring the generated content complies with ethical guidelines. Further, we present HarmEval, a novel benchmark for extensive safety evaluations, designed to address potential misuse scenarios in accordance with the policies of leading AI tech giants.
Breaking Boundaries: Investigating the Effects of Model Editing on Cross-linguistic Performance
Jun 17, 2024The integration of pretrained language models (PLMs) like BERT and GPT has revolutionized NLP, particularly for English, but it has also created linguistic imbalances. This paper strategically identifies the need for linguistic equity by examining several knowledge editing techniques in multilingual contexts. We evaluate the performance of models such as Mistral, TowerInstruct, OpenHathi, Tamil-Llama, and Kan-Llama across languages including English, German, French, Italian, Spanish, Hindi, Tamil, and Kannada. Our research identifies significant discrepancies in normal and merged models concerning cross-lingual consistency. We employ strategies like 'each language for itself' (ELFI) and 'each language for others' (ELFO) to stress-test these models. Our findings demonstrate the potential for LLMs to overcome linguistic barriers, laying the groundwork for future research in achieving linguistic inclusivity in AI technologies.
Antitrust, Amazon, and Algorithmic Auditing
Mar 27, 2024



In digital markets, antitrust law and special regulations aim to ensure that markets remain competitive despite the dominating role that digital platforms play today in everyone's life. Unlike traditional markets, market participant behavior is easily observable in these markets. We present a series of empirical investigations into the extent to which Amazon engages in practices that are typically described as self-preferencing. We discuss how the computer science tools used in this paper can be used in a regulatory environment that is based on algorithmic auditing and requires regulating digital markets at scale.
On Zero-Shot Counterspeech Generation by LLMs
Mar 22, 2024With the emergence of numerous Large Language Models (LLM), the usage of such models in various Natural Language Processing (NLP) applications is increasing extensively. Counterspeech generation is one such key task where efforts are made to develop generative models by fine-tuning LLMs with hatespeech - counterspeech pairs, but none of these attempts explores the intrinsic properties of large language models in zero-shot settings. In this work, we present a comprehensive analysis of the performances of four LLMs namely GPT-2, DialoGPT, ChatGPT and FlanT5 in zero-shot settings for counterspeech generation, which is the first of its kind. For GPT-2 and DialoGPT, we further investigate the deviation in performance with respect to the sizes (small, medium, large) of the models. On the other hand, we propose three different prompting strategies for generating different types of counterspeech and analyse the impact of such strategies on the performance of the models. Our analysis shows that there is an improvement in generation quality for two datasets (17%), however the toxicity increase (25%) with increase in model size. Considering type of model, GPT-2 and FlanT5 models are significantly better in terms of counterspeech quality but also have high toxicity as compared to DialoGPT. ChatGPT are much better at generating counter speech than other models across all metrics. In terms of prompting, we find that our proposed strategies help in improving counter speech generation across all the models.
DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Mar 11, 2024



With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
InfFeed: Influence Functions as a Feedback to Improve the Performance of Subjective Tasks
Mar 09, 2024Recently, influence functions present an apparatus for achieving explainability for deep neural models by quantifying the perturbation of individual train instances that might impact a test prediction. Our objectives in this paper are twofold. First we incorporate influence functions as a feedback into the model to improve its performance. Second, in a dataset extension exercise, using influence functions to automatically identify data points that have been initially `silver' annotated by some existing method and need to be cross-checked (and corrected) by annotators to improve the model performance. To meet these objectives, in this paper, we introduce InfFeed, which uses influence functions to compute the influential instances for a target instance. Toward the first objective, we adjust the label of the target instance based on its influencer(s) label. In doing this, InfFeed outperforms the state-of-the-art baselines (including LLMs) by a maximum macro F1-score margin of almost 4% for hate speech classification, 3.5% for stance classification, and 3% for irony and 2% for sarcasm detection. Toward the second objective we show that manually re-annotating only those silver annotated data points in the extension set that have a negative influence can immensely improve the model performance bringing it very close to the scenario where all the data points in the extension set have gold labels. This allows for huge reduction of the number of data points that need to be manually annotated since out of the silver annotated extension dataset, the influence function scheme picks up ~1/1000 points that need manual correction.