 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDEGAN: Gaussian Dynamic Equivariant Graph Attention Network for Ligand Binding Site Prediction
Mar 20, 2026Accurate prediction of binding sites of a given protein, to which ligands can bind, is a critical step in structure-based computational drug discovery. Recently, Equivariant Graph Neural Networks (GNNs) have emerged as a powerful paradigm for binding site identification methods due to the large-scale availability of 3D structures of proteins via protein databases and AlphaFold predictions. The state-of-the-art equivariant GNN methods implement dot product attention, disregarding the variation in the chemical and geometric properties of the neighboring residues. To capture this variation, we propose GDEGAN (Gaussian Dynamic Equivariant Graph Attention Network), which replaces dot-product attention with adaptive kernels that recognize binding sites. The proposed attention mechanism captures variation in neighboring residues using statistics of their characteristic local feature distributions. Our mechanism dynamically computes neighborhood statistics at each layer, using local variance as an adaptive bandwidth parameter with learnable per-head temperatures, enabling each protein region to determine its own context-specific importance. GDEGAN outperforms existing methods with relative improvements of 37-66% in DCC and 7-19% DCA success rates across COACH420, HOLO4k, and PDBBind2020 datasets. These advances have direct application in accelerating protein-ligand docking by identifying potential binding sites for therapeutic target identification.
Reading Industrial Inspection Sheets by Inferring Visual Relations
Dec 11, 2018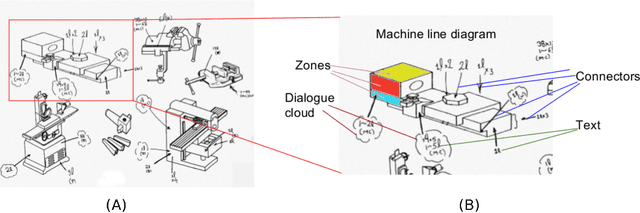
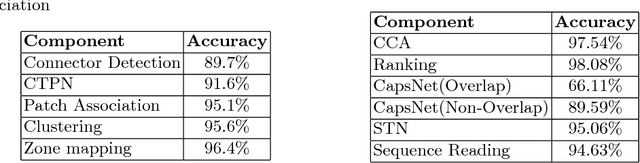
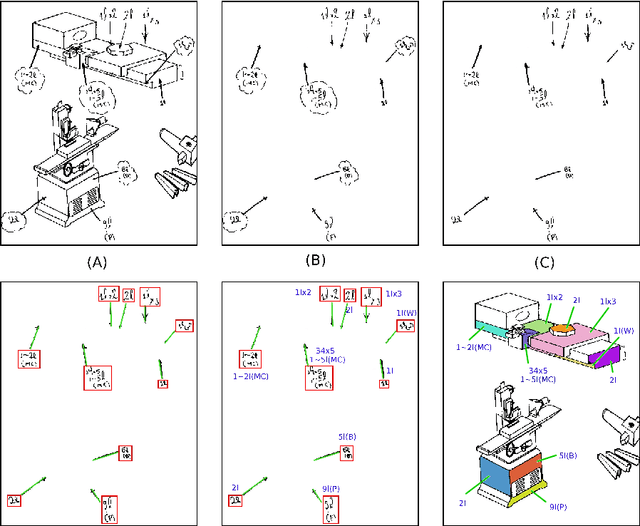

The traditional mode of recording faults in heavy factory equipment has been via hand marked inspection sheets, wherein a machine engineer manually marks the faulty machine regions on a paper outline of the machine. Over the years, millions of such inspection sheets have been recorded and the data within these sheets has remained inaccessible. However, with industries going digital and waking up to the potential value of fault data for machine health monitoring, there is an increased impetus towards digitization of these hand marked inspection records. To target this digitization, we propose a novel visual pipeline combining state of the art deep learning models, with domain knowledge and low level vision techniques, followed by inference of visual relationships. Our framework is robust to the presence of both static and non-static background in the document, variability in the machine template diagrams, unstructured shape of graphical objects to be identified and variability in the strokes of handwritten text. The proposed pipeline incorporates a capsule and spatial transformer network based classifier for accurate text reading, and a customized CTPN network for text detection in addition to hybrid techniques for arrow detection and dialogue cloud removal. We have tested our approach on a real world dataset of 50 inspection sheets for large containers and boilers. The results are visually appealing and the pipeline achieved an accuracy of 87.1% for text detection and 94.6% for text reading.