 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Learning to Generate Semantically Correct Hindi Captions
Feb 13, 2026Automated image captioning using the content from the image is very appealing when done by harnessing the capability of computer vision and natural language processing. Extensive research has been done in the field with a major focus on the English language which gives the scope for further developments in the same with consideration of popular foreign languages. This research utilizes distinct models for translating the image caption into Hindi, the fourth most popular language across the world. Exploring the multi-modal architectures this research comprises local visual features, global visual features, attention mechanisms, and pre-trained models. Using google cloud translator on the image dataset from Flickr8k, Hindi image descriptions have been generated. Pre-trained CNNs like VGG16, ResNet50, and Inception V3 helped in retrieving image characteristics, while the uni-directional and bi-directional techniques of text encoding are used for the text encoding process. An additional Attention layer helps to generate a weight vector and, by multiplying it, combine image characteristics from each time step into a sentence-level feature vector. Bilingual evaluation understudy scores are used to compare the research outcome. Many experiments that serve as a baseline are done for the comparative analysis of the research. An image with a score of BLEU-1 is considered sufficient, whereas one with a score of BLEU-4 is considered to have fluid image captioning. For both BLEU scores, the attention-based bidirectional LSTM with VGG16 produced the best results of 0.59 and 0.19 respectively. The experiments conclude that researchs ability to produce relevant, semantically accurate image captions in Hindi. The research accomplishes the goals and future research can be guided by this research model.
Efficient ASR for Low-Resource Languages: Leveraging Cross-Lingual Unlabeled Data
Dec 08, 2025Automatic speech recognition for low-resource languages remains fundamentally constrained by the scarcity of labeled data and computational resources required by state-of-the-art models. We present a systematic investigation into cross-lingual continuous pretraining for low-resource languages, using Perso-Arabic languages (Persian, Arabic, and Urdu) as our primary case study. Our approach demonstrates that strategic utilization of unlabeled speech data can effectively bridge the resource gap without sacrificing recognition accuracy. We construct a 3,000-hour multilingual corpus through a scalable unlabeled data collection pipeline and employ targeted continual pretraining combined with morphologically-aware tokenization to develop a 300M parameter model that achieves performance comparable to systems 5 times larger. Our model outperforms Whisper Large v3 (1.5B parameters) on Persian and achieves competitive results on Arabic and Urdu despite using significantly fewer parameters and substantially less labeled data. These findings challenge the prevailing assumption that ASR quality scales primarily with model size, revealing instead that data relevance and strategic pretraining are more critical factors for low-resource scenarios. This work provides a practical pathway toward inclusive speech technology, enabling effective ASR for underrepresented languages without dependence on massive computational infrastructure or proprietary datasets.
TeluguST-46: A Benchmark Corpus and Comprehensive Evaluation for Telugu-English Speech Translation
Dec 08, 2025


Despite Telugu being spoken by over 80 million people, speech translation research for this morphologically rich language remains severely underexplored. We address this gap by developing a high-quality Telugu--English speech translation benchmark from 46 hours of manually verified CSTD corpus data (30h/8h/8h train/dev/test split). Our systematic comparison of cascaded versus end-to-end architectures shows that while IndicWhisper + IndicMT achieves the highest performance due to extensive Telugu-specific training data, finetuned SeamlessM4T models demonstrate remarkable competitiveness despite using significantly less Telugu-specific training data. This finding suggests that with careful hyperparameter tuning and sufficient parallel data (potentially less than 100 hours), end-to-end systems can achieve performance comparable to cascaded approaches in low-resource settings. Our metric reliability study evaluating BLEU, METEOR, ChrF++, ROUGE-L, TER, and BERTScore against human judgments reveals that traditional metrics provide better quality discrimination than BERTScore for Telugu--English translation. The work delivers three key contributions: a reproducible Telugu--English benchmark, empirical evidence of competitive end-to-end performance potential in low-resource scenarios, and practical guidance for automatic evaluation in morphologically complex language pairs.
Fairness in Dysarthric Speech Synthesis: Understanding Intrinsic Bias in Dysarthric Speech Cloning using F5-TTS
Aug 07, 2025Dysarthric speech poses significant challenges in developing assistive technologies, primarily due to the limited availability of data. Recent advances in neural speech synthesis, especially zero-shot voice cloning, facilitate synthetic speech generation for data augmentation; however, they may introduce biases towards dysarthric speech. In this paper, we investigate the effectiveness of state-of-the-art F5-TTS in cloning dysarthric speech using TORGO dataset, focusing on intelligibility, speaker similarity, and prosody preservation. We also analyze potential biases using fairness metrics like Disparate Impact and Parity Difference to assess disparities across dysarthric severity levels. Results show that F5-TTS exhibits a strong bias toward speech intelligibility over speaker and prosody preservation in dysarthric speech synthesis. Insights from this study can help integrate fairness-aware dysarthric speech synthesis, fostering the advancement of more inclusive speech technologies.
IIITH-BUT system for IWSLT 2025 low-resource Bhojpuri to Hindi speech translation
Jun 05, 2025



This paper presents the submission of IIITH-BUT to the IWSLT 2025 shared task on speech translation for the low-resource Bhojpuri-Hindi language pair. We explored the impact of hyperparameter optimisation and data augmentation techniques on the performance of the SeamlessM4T model fine-tuned for this specific task. We systematically investigated a range of hyperparameters including learning rate schedules, number of update steps, warm-up steps, label smoothing, and batch sizes; and report their effect on translation quality. To address data scarcity, we applied speed perturbation and SpecAugment and studied their effect on translation quality. We also examined the use of cross-lingual signal through joint training with Marathi and Bhojpuri speech data. Our experiments reveal that careful selection of hyperparameters and the application of simple yet effective augmentation techniques significantly improve performance in low-resource settings. We also analysed the translation hypotheses to understand various kinds of errors that impacted the translation quality in terms of BLEU.
A Multi-modal Approach to Dysarthria Detection and Severity Assessment Using Speech and Text Information
Dec 22, 2024



Automatic detection and severity assessment of dysarthria are crucial for delivering targeted therapeutic interventions to patients. While most existing research focuses primarily on speech modality, this study introduces a novel approach that leverages both speech and text modalities. By employing cross-attention mechanism, our method learns the acoustic and linguistic similarities between speech and text representations. This approach assesses specifically the pronunciation deviations across different severity levels, thereby enhancing the accuracy of dysarthric detection and severity assessment. All the experiments have been performed using UA-Speech dysarthric database. Improved accuracies of 99.53% and 93.20% in detection, and 98.12% and 51.97% for severity assessment have been achieved when speaker-dependent and speaker-independent, unseen and seen words settings are used. These findings suggest that by integrating text information, which provides a reference linguistic knowledge, a more robust framework has been developed for dysarthric detection and assessment, thereby potentially leading to more effective diagnoses.
A Preliminary Analysis of Automatic Word and Syllable Prominence Detection in Non-Native Speech With Text-to-Speech Prosody Embeddings
Dec 11, 2024Automatic detection of prominence at the word and syllable-levels is critical for building computer-assisted language learning systems. It has been shown that prosody embeddings learned by the current state-of-the-art (SOTA) text-to-speech (TTS) systems could generate word- and syllable-level prominence in the synthesized speech as natural as in native speech. To understand the effectiveness of prosody embeddings from TTS for prominence detection under nonnative context, a comparative analysis is conducted on the embeddings extracted from native and non-native speech considering the prominence-related embeddings: duration, energy, and pitch from a SOTA TTS named FastSpeech2. These embeddings are extracted under two conditions considering: 1) only text, 2) both speech and text. For the first condition, the embeddings are extracted directly from the TTS inference mode, whereas for the second condition, we propose to extract from the TTS under training mode. Experiments are conducted on native speech corpus: Tatoeba, and non-native speech corpus: ISLE. For experimentation, word-level prominence locations are manually annotated for both corpora. The highest relative improvement on word \& syllable-level prominence detection accuracies with the TTS embeddings are found to be 13.7% & 5.9% and 16.2% & 6.9% compared to those with the heuristic-based features and self-supervised Wav2Vec-2.0 representations, respectively.
End-to-End User-Defined Keyword Spotting using Shifted Delta Coefficients
May 23, 2024Identifying user-defined keywords is crucial for personalizing interactions with smart devices. Previous approaches of user-defined keyword spotting (UDKWS) have relied on short-term spectral features such as mel frequency cepstral coefficients (MFCC) to detect the spoken keyword. However, these features may face challenges in accurately identifying closely related pronunciation of audio-text pairs, due to their limited capability in capturing the temporal dynamics of the speech signal. To address this challenge, we propose to use shifted delta coefficients (SDC) which help in capturing pronunciation variability (transition between connecting phonemes) by incorporating long-term temporal information. The performance of the SDC feature is compared with various baseline features across four different datasets using a cross-attention based end-to-end system. Additionally, various configurations of SDC are explored to find the suitable temporal context for the UDKWS task. The experimental results reveal that the SDC feature outperforms the MFCC baseline feature, exhibiting an improvement of 8.32% in area under the curve (AUC) and 8.69% in terms of equal error rate (EER) on the challenging Libriphrase-hard dataset. Moreover, the proposed approach demonstrated superior performance when compared to state-of-the-art UDKWS techniques.
Open vocabulary keyword spotting through transfer learning from speech synthesis
Apr 05, 2024Identifying keywords in an open-vocabulary context is crucial for personalizing interactions with smart devices. Previous approaches to open vocabulary keyword spotting dependon a shared embedding space created by audio and text encoders. However, these approaches suffer from heterogeneous modality representations (i.e., audio-text mismatch). To address this issue, our proposed framework leverages knowledge acquired from a pre-trained text-to-speech (TTS) system. This knowledge transfer allows for the incorporation of awareness of audio projections into the text representations derived from the text encoder. The performance of the proposed approach is compared with various baseline methods across four different datasets. The robustness of our proposed model is evaluated by assessing its performance across different word lengths and in an Out-of-Vocabulary (OOV) scenario. Additionally, the effectiveness of transfer learning from the TTS system is investigated by analyzing its different intermediate representations. The experimental results indicate that, in the challenging LibriPhrase Hard dataset, the proposed approach outperformed the cross-modality correspondence detector (CMCD) method by a significant improvement of 8.22% in area under the curve (AUC) and 12.56% in equal error rate (EER).
A language model based approach towards large scale and lightweight language identification systems
Oct 13, 2015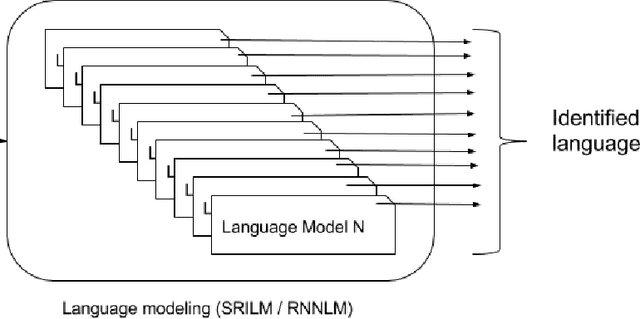
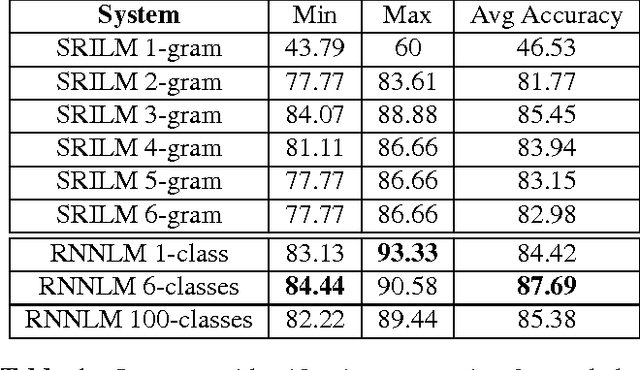
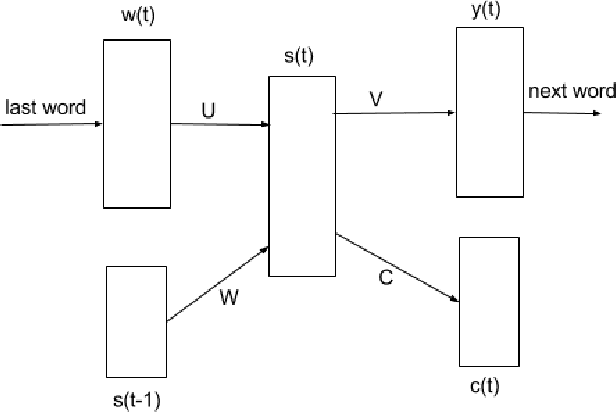
Multilingual spoken dialogue systems have gained prominence in the recent past necessitating the requirement for a front-end Language Identification (LID) system. Most of the existing LID systems rely on modeling the language discriminative information from low-level acoustic features. Due to the variabilities of speech (speaker and emotional variabilities, etc.), large-scale LID systems developed using low-level acoustic features suffer from a degradation in the performance. In this approach, we have attempted to model the higher level language discriminative phonotactic information for developing an LID system. In this paper, the input speech signal is tokenized to phone sequences by using a language independent phone recognizer. The language discriminative phonotactic information in the obtained phone sequences are modeled using statistical and recurrent neural network based language modeling approaches. As this approach, relies on higher level phonotactical information it is more robust to variabilities of speech. Proposed approach is computationally light weight, highly scalable and it can be used in complement with the existing LID systems.