 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIITH-BUT system for IWSLT 2025 low-resource Bhojpuri to Hindi speech translation
Jun 05, 2025



This paper presents the submission of IIITH-BUT to the IWSLT 2025 shared task on speech translation for the low-resource Bhojpuri-Hindi language pair. We explored the impact of hyperparameter optimisation and data augmentation techniques on the performance of the SeamlessM4T model fine-tuned for this specific task. We systematically investigated a range of hyperparameters including learning rate schedules, number of update steps, warm-up steps, label smoothing, and batch sizes; and report their effect on translation quality. To address data scarcity, we applied speed perturbation and SpecAugment and studied their effect on translation quality. We also examined the use of cross-lingual signal through joint training with Marathi and Bhojpuri speech data. Our experiments reveal that careful selection of hyperparameters and the application of simple yet effective augmentation techniques significantly improve performance in low-resource settings. We also analysed the translation hypotheses to understand various kinds of errors that impacted the translation quality in terms of BLEU.
Hippocampus-Inspired Cognitive Architecture (HICA) for Operant Conditioning
Dec 16, 2022The neural implementation of operant conditioning with few trials is unclear. We propose a Hippocampus-Inspired Cognitive Architecture (HICA) as a neural mechanism for operant conditioning. HICA explains a learning mechanism in which agents can learn a new behavior policy in a few trials, as mammals do in operant conditioning experiments. HICA is composed of two different types of modules. One is a universal learning module type that represents a cortical column in the neocortex gray matter. The working principle is modeled as Modulated Heterarchical Prediction Memory (mHPM). In mHPM, each module learns to predict a succeeding input vector given the sequence of the input vectors from lower layers and the context vectors from higher layers. The prediction is fed into the lower layers as a context signal (top-down feedback signaling), and into the higher layers as an input signal (bottom-up feedforward signaling). Rewards modulate the learning rate in those modules to memorize meaningful sequences effectively. In mHPM, each module updates in a local and distributed way compared to conventional end-to-end learning with backpropagation of the single objective loss. This local structure enables the heterarchical network of modules. The second type is an innate, special-purpose module representing various organs of the brain's subcortical system. Modules modeling organs such as the amygdala, hippocampus, and reward center are pre-programmed to enable instinctive behaviors. The hippocampus plays the role of the simulator. It is an autoregressive prediction model of the top-most level signal with a loop structure of memory, while cortical columns are lower layers that provide detailed information to the simulation. The simulation becomes the basis for learning with few trials and the deliberate planning required for operant conditioning.
Modeling Social Interaction for Baby in Simulated Environment for Developmental Robotics
Dec 29, 2020

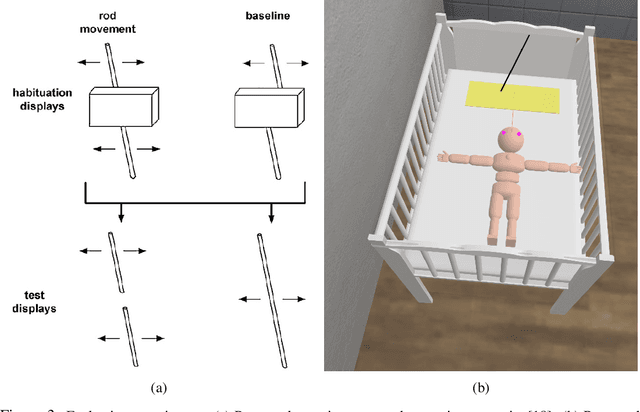
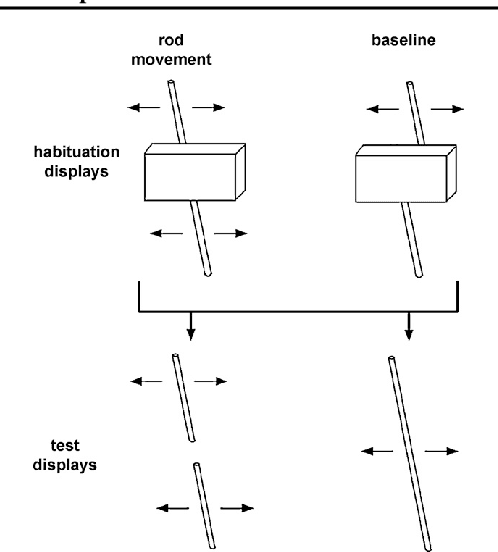
Task-specific AI agents are showing remarkable performance across different domains. But modeling generalized AI agents like human intelligence will require more than current datasets or only reward-based environments that don't include experiences that an infant gathers throughout its initial stages. In this paper, we present Simulated Environment for Developmental Robotics (SEDRo). It simulates the environments for a baby agent that a human baby experiences throughout the pre-born fetus stage to post-birth 12 months. SEDRo also includes a mother character to provide social interaction with the agent. To evaluate different developmental milestones of the agent, SEDRo incorporates some experiments from developmental psychology.
SEDRo: A Simulated Environment for Developmental Robotics
Sep 03, 2020Even with impressive advances in application-specific models, we still lack knowledge about how to build a model that can learn in a human-like way and do multiple tasks. To learn in a human-like way, we need to provide a diverse experience that is comparable to humans. In this paper, we introduce our ongoing effort to build a simulated environment for developmental robotics (SEDRo). SEDRo provides diverse human experiences ranging from those of a fetus to a 12th-month-old. A series of simulated tests based on developmental psychology will be used to evaluate the progress of a learning model. We anticipate SEDRo to lower the cost of entry and facilitate research in the developmental robotics community.
An Open-World Simulated Environment for Developmental Robotics
Jul 18, 2020
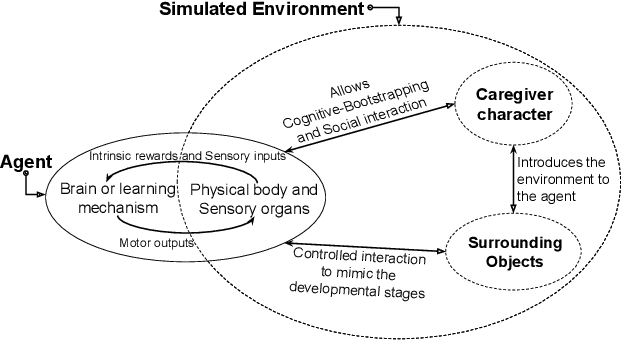
As the current trend of artificial intelligence is shifting towards self-supervised learning, conventional norms such as highly curated domain-specific data, application-specific learning models, extrinsic reward based learning policies etc. might not provide with the suitable ground for such developments. In this paper, we introduce SEDRo, a Simulated Environment for Developmental Robotics which allows a learning agent to have similar experiences that a human infant goes through from the fetus stage up to 12 months. A series of simulated tests based on developmental psychology will be used to evaluate the progress of a learning model.