 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Feedback Loss in Speech Chain Framework via Straight-Through Estimator
Oct 31, 2018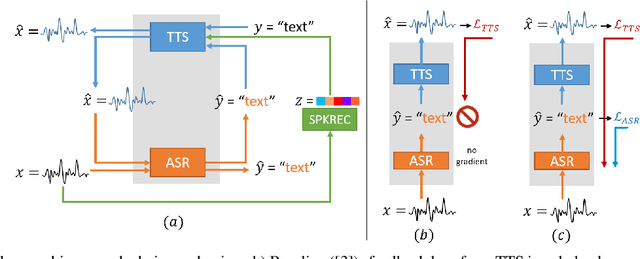
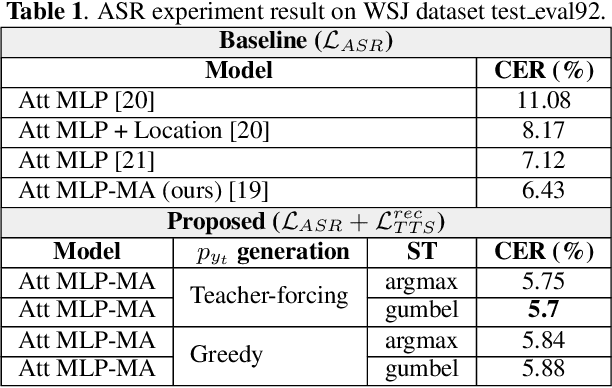
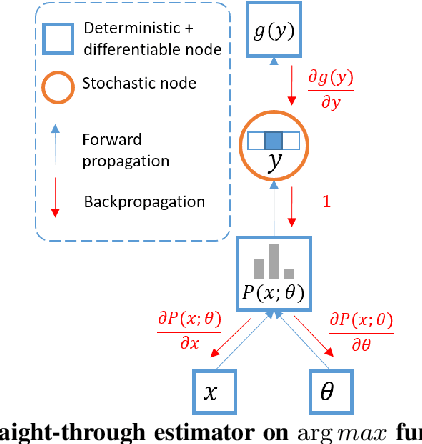
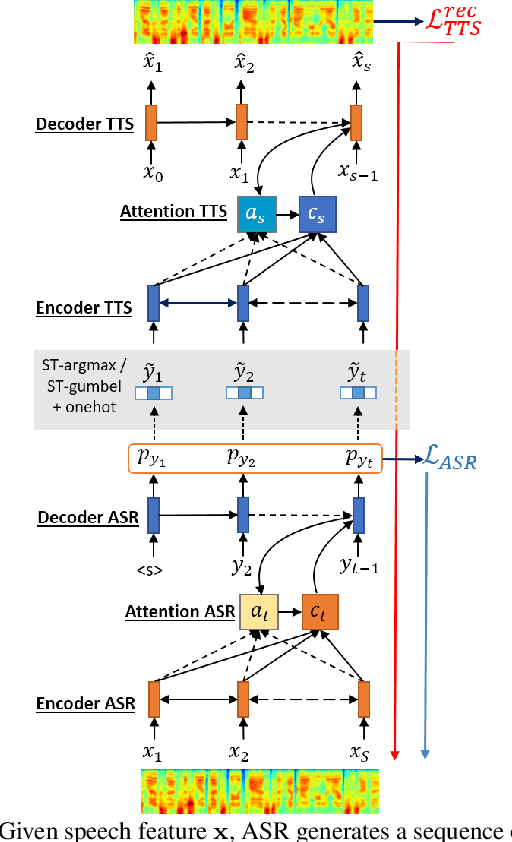
The speech chain mechanism integrates automatic speech recognition (ASR) and text-to-speech synthesis (TTS) modules into a single cycle during training. In our previous work, we applied a speech chain mechanism as a semi-supervised learning. It provides the ability for ASR and TTS to assist each other when they receive unpaired data and let them infer the missing pair and optimize the model with reconstruction loss. If we only have speech without transcription, ASR generates the most likely transcription from the speech data, and then TTS uses the generated transcription to reconstruct the original speech features. However, in previous papers, we just limited our back-propagation to the closest module, which is the TTS part. One reason is that back-propagating the error through the ASR is challenging due to the output of the ASR are discrete tokens, creating non-differentiability between the TTS and ASR. In this paper, we address this problem and describe how to thoroughly train a speech chain end-to-end for reconstruction loss using a straight-through estimator (ST). Experimental results revealed that, with sampling from ST-Gumbel-Softmax, we were able to update ASR parameters and improve the ASR performances by 11\% relative CER reduction compared to the baseline.
Multi-scale Alignment and Contextual History for Attention Mechanism in Sequence-to-sequence Model
Jul 22, 2018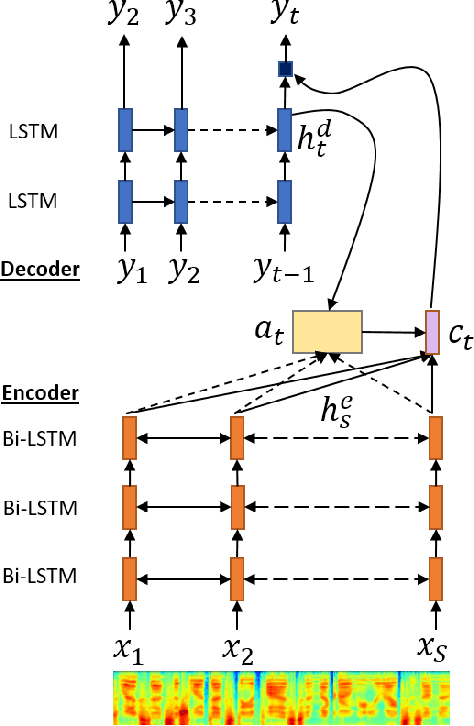
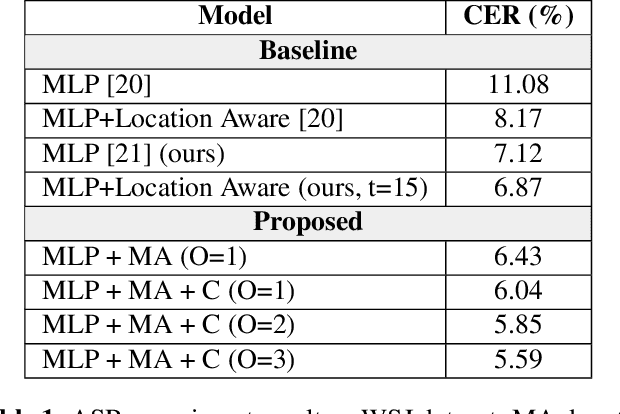
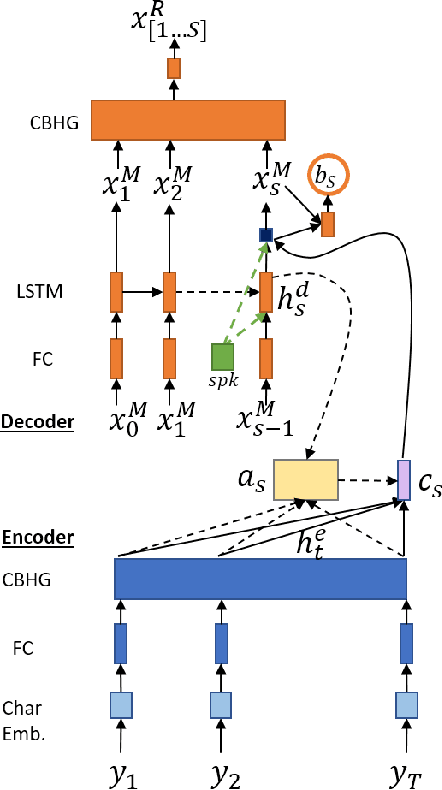
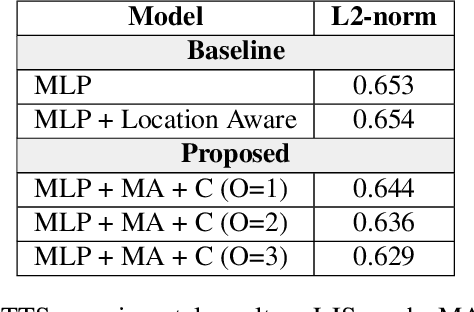
A sequence-to-sequence model is a neural network module for mapping two sequences of different lengths. The sequence-to-sequence model has three core modules: encoder, decoder, and attention. Attention is the bridge that connects the encoder and decoder modules and improves model performance in many tasks. In this paper, we propose two ideas to improve sequence-to-sequence model performance by enhancing the attention module. First, we maintain the history of the location and the expected context from several previous time-steps. Second, we apply multiscale convolution from several previous attention vectors to the current decoder state. We utilized our proposed framework for sequence-to-sequence speech recognition and text-to-speech systems. The results reveal that our proposed extension could improve performance significantly compared to a standard attention baseline.
Tensor Decomposition for Compressing Recurrent Neural Network
May 08, 2018
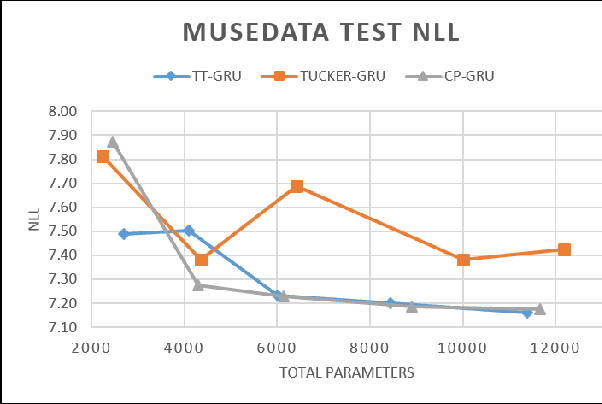
In the machine learning fields, Recurrent Neural Network (RNN) has become a popular architecture for sequential data modeling. However, behind the impressive performance, RNNs require a large number of parameters for both training and inference. In this paper, we are trying to reduce the number of parameters and maintain the expressive power from RNN simultaneously. We utilize several tensor decompositions method including CANDECOMP/PARAFAC (CP), Tucker decomposition and Tensor Train (TT) to re-parameterize the Gated Recurrent Unit (GRU) RNN. We evaluate all tensor-based RNNs performance on sequence modeling tasks with a various number of parameters. Based on our experiment results, TT-GRU achieved the best results in a various number of parameters compared to other decomposition methods.
Machine Speech Chain with One-shot Speaker Adaptation
Mar 28, 2018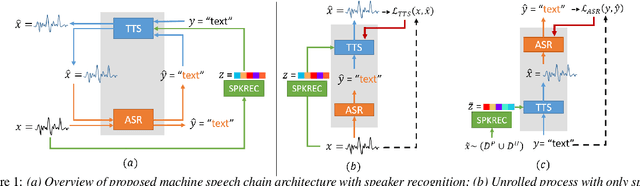
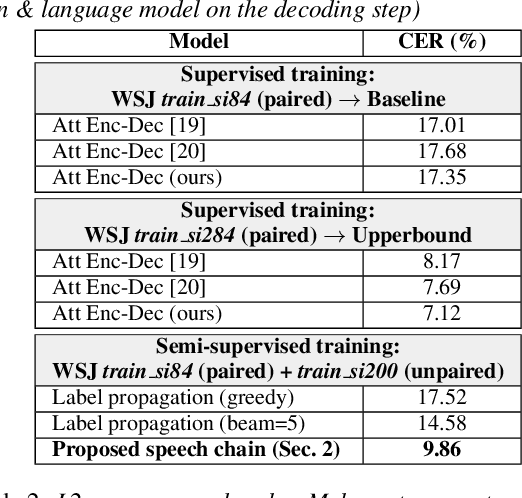
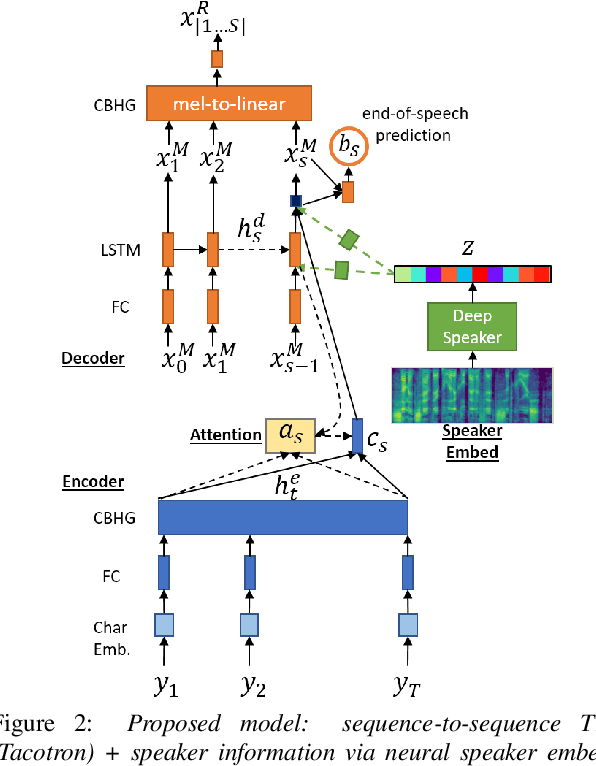
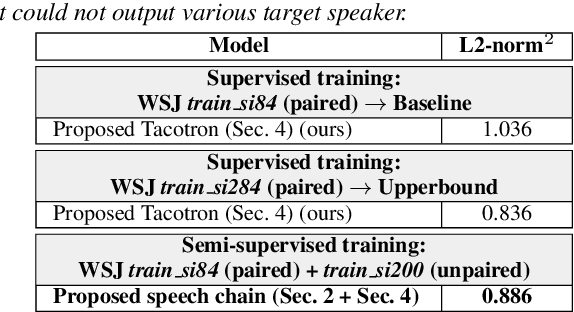
In previous work, we developed a closed-loop speech chain model based on deep learning, in which the architecture enabled the automatic speech recognition (ASR) and text-to-speech synthesis (TTS) components to mutually improve their performance. This was accomplished by the two parts teaching each other using both labeled and unlabeled data. This approach could significantly improve model performance within a single-speaker speech dataset, but only a slight increase could be gained in multi-speaker tasks. Furthermore, the model is still unable to handle unseen speakers. In this paper, we present a new speech chain mechanism by integrating a speaker recognition model inside the loop. We also propose extending the capability of TTS to handle unseen speakers by implementing one-shot speaker adaptation. This enables TTS to mimic voice characteristics from one speaker to another with only a one-shot speaker sample, even from a text without any speaker information. In the speech chain loop mechanism, ASR also benefits from the ability to further learn an arbitrary speaker's characteristics from the generated speech waveform, resulting in a significant improvement in the recognition rate.
Sequence-to-Sequence ASR Optimization via Reinforcement Learning
Feb 28, 2018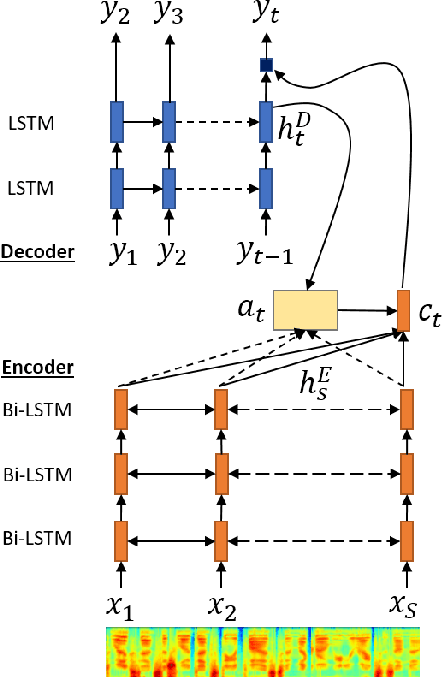
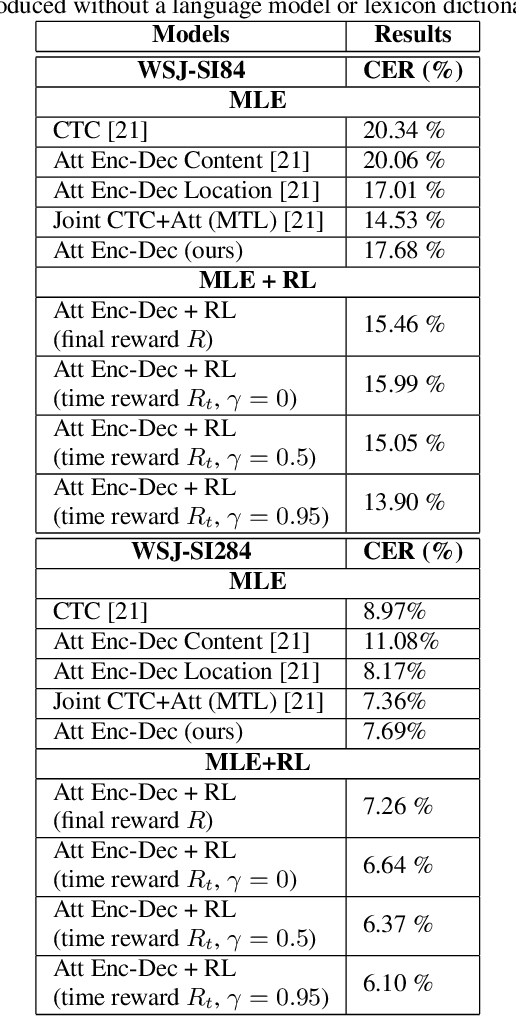
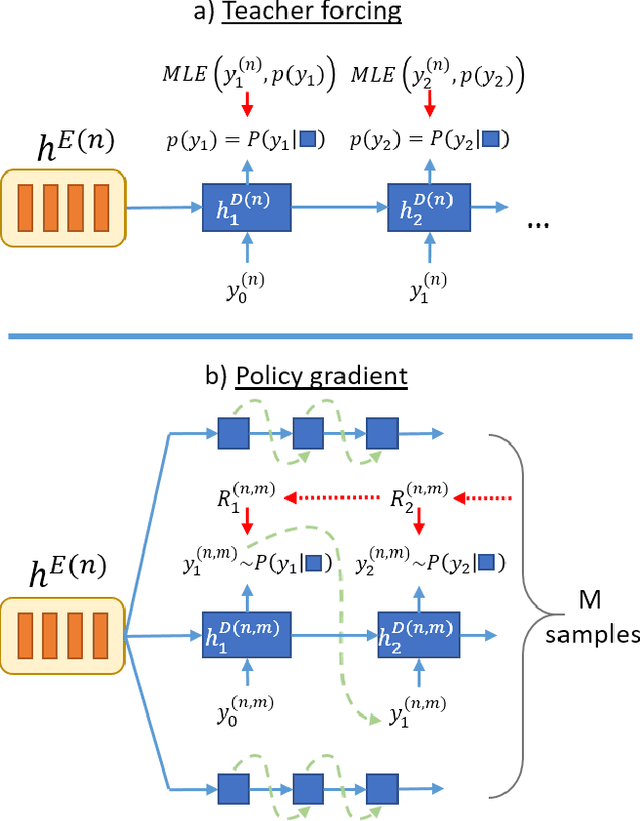
Despite the success of sequence-to-sequence approaches in automatic speech recognition (ASR) systems, the models still suffer from several problems, mainly due to the mismatch between the training and inference conditions. In the sequence-to-sequence architecture, the model is trained to predict the grapheme of the current time-step given the input of speech signal and the ground-truth grapheme history of the previous time-steps. However, it remains unclear how well the model approximates real-world speech during inference. Thus, generating the whole transcription from scratch based on previous predictions is complicated and errors can propagate over time. Furthermore, the model is optimized to maximize the likelihood of training data instead of error rate evaluation metrics that actually quantify recognition quality. This paper presents an alternative strategy for training sequence-to-sequence ASR models by adopting the idea of reinforcement learning (RL). Unlike the standard training scheme with maximum likelihood estimation, our proposed approach utilizes the policy gradient algorithm. We can (1) sample the whole transcription based on the model's prediction in the training process and (2) directly optimize the model with negative Levenshtein distance as the reward. Experimental results demonstrate that we significantly improved the performance compared to a model trained only with maximum likelihood estimation.
Local Monotonic Attention Mechanism for End-to-End Speech and Language Processing
Nov 03, 2017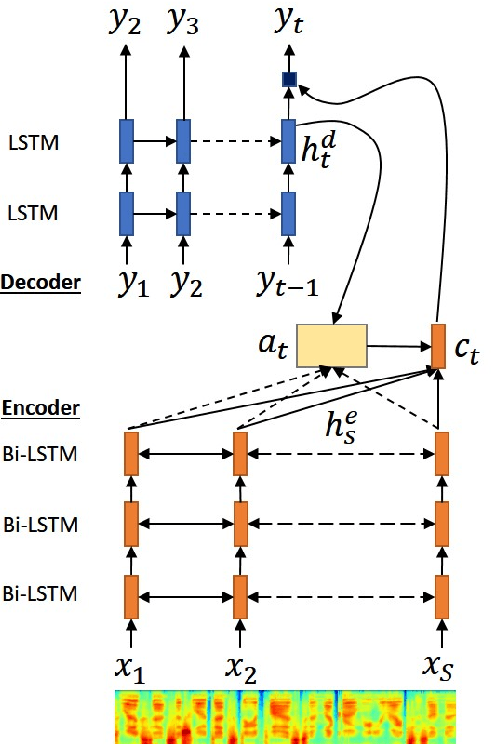
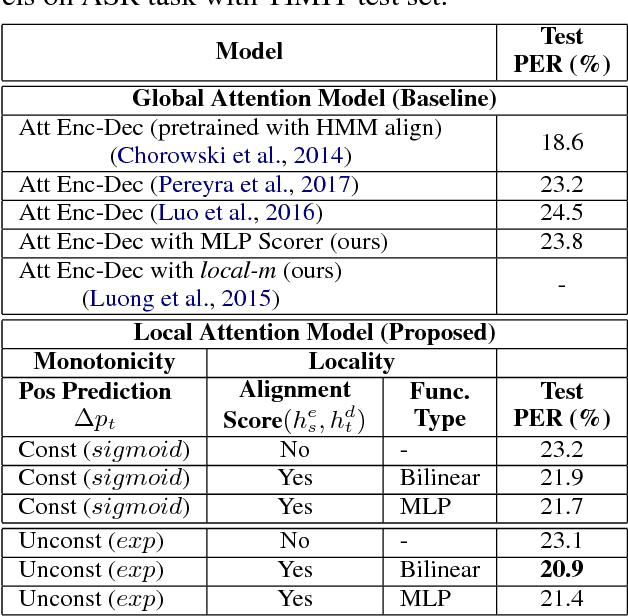
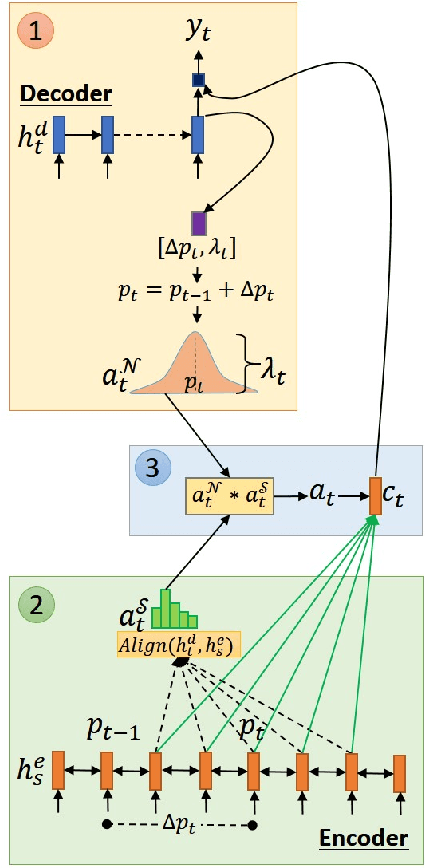
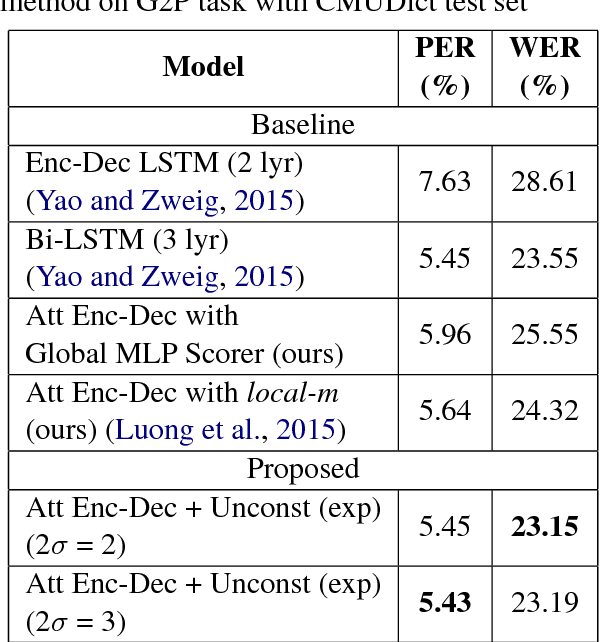
Recently, encoder-decoder neural networks have shown impressive performance on many sequence-related tasks. The architecture commonly uses an attentional mechanism which allows the model to learn alignments between the source and the target sequence. Most attentional mechanisms used today is based on a global attention property which requires a computation of a weighted summarization of the whole input sequence generated by encoder states. However, it is computationally expensive and often produces misalignment on the longer input sequence. Furthermore, it does not fit with monotonous or left-to-right nature in several tasks, such as automatic speech recognition (ASR), grapheme-to-phoneme (G2P), etc. In this paper, we propose a novel attention mechanism that has local and monotonic properties. Various ways to control those properties are also explored. Experimental results on ASR, G2P and machine translation between two languages with similar sentence structures, demonstrate that the proposed encoder-decoder model with local monotonic attention could achieve significant performance improvements and reduce the computational complexity in comparison with the one that used the standard global attention architecture.
Attention-based Wav2Text with Feature Transfer Learning
Sep 22, 2017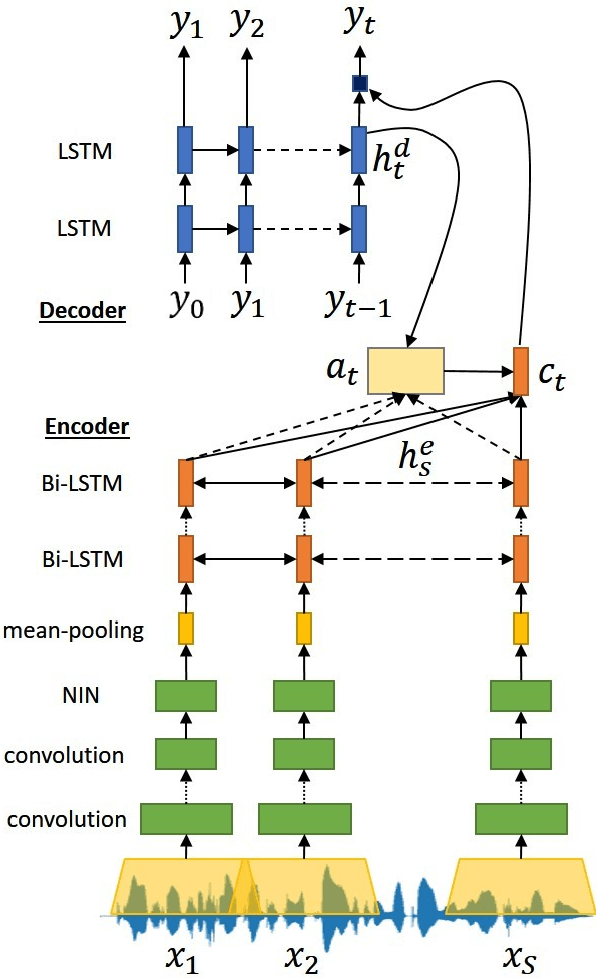
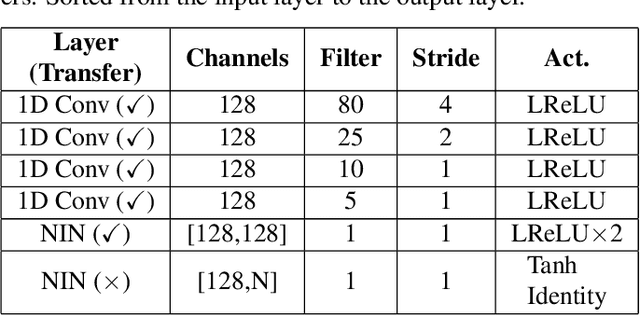
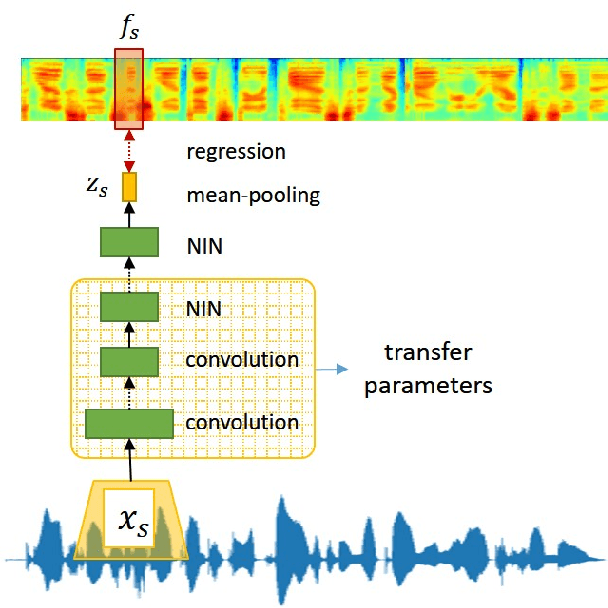
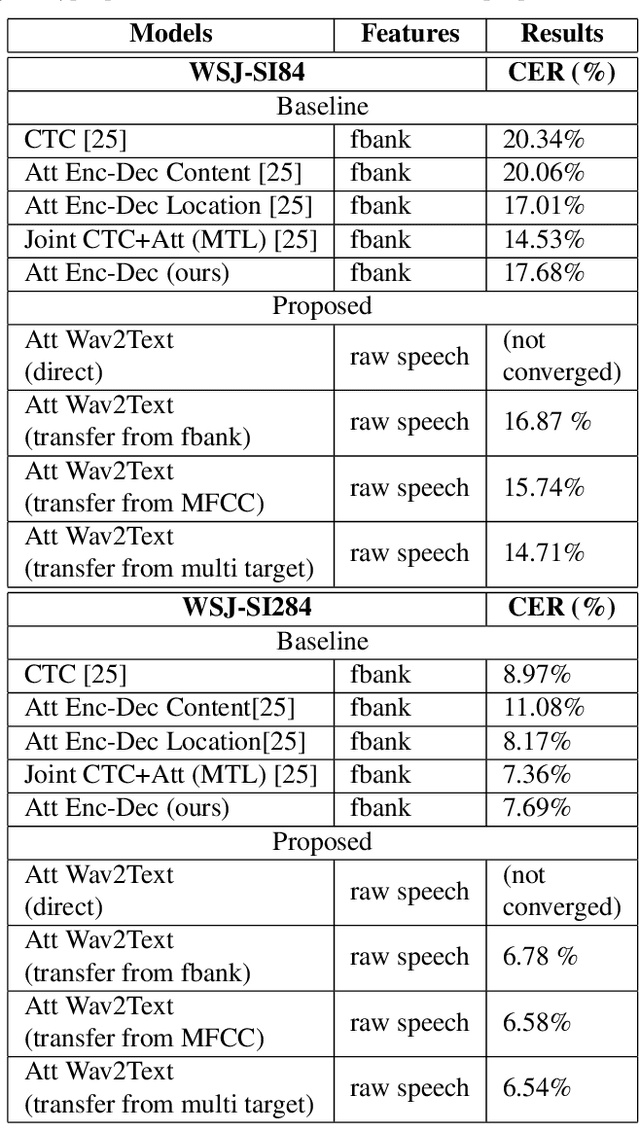
Conventional automatic speech recognition (ASR) typically performs multi-level pattern recognition tasks that map the acoustic speech waveform into a hierarchy of speech units. But, it is widely known that information loss in the earlier stage can propagate through the later stages. After the resurgence of deep learning, interest has emerged in the possibility of developing a purely end-to-end ASR system from the raw waveform to the transcription without any predefined alignments and hand-engineered models. However, the successful attempts in end-to-end architecture still used spectral-based features, while the successful attempts in using raw waveform were still based on the hybrid deep neural network - Hidden Markov model (DNN-HMM) framework. In this paper, we construct the first end-to-end attention-based encoder-decoder model to process directly from raw speech waveform to the text transcription. We called the model as "Attention-based Wav2Text". To assist the training process of the end-to-end model, we propose to utilize a feature transfer learning. Experimental results also reveal that the proposed Attention-based Wav2Text model directly with raw waveform could achieve a better result in comparison with the attentional encoder-decoder model trained on standard front-end filterbank features.
Listening while Speaking: Speech Chain by Deep Learning
Jul 16, 2017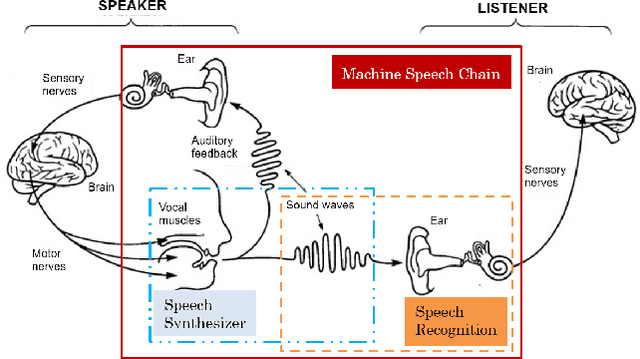
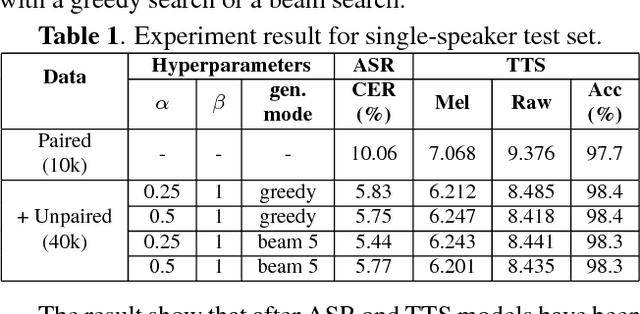
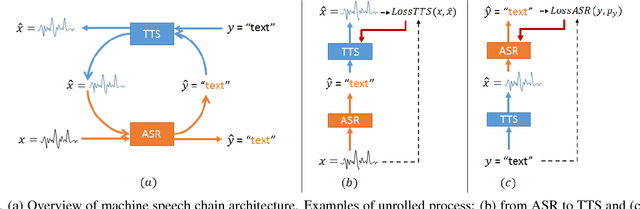
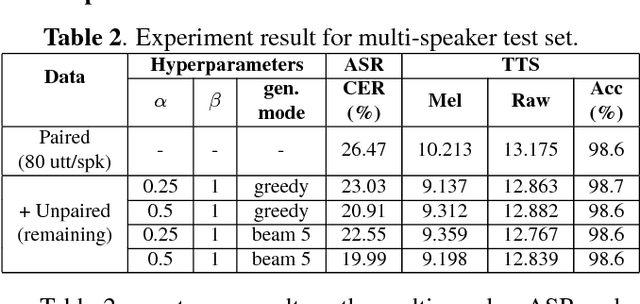
Despite the close relationship between speech perception and production, research in automatic speech recognition (ASR) and text-to-speech synthesis (TTS) has progressed more or less independently without exerting much mutual influence on each other. In human communication, on the other hand, a closed-loop speech chain mechanism with auditory feedback from the speaker's mouth to her ear is crucial. In this paper, we take a step further and develop a closed-loop speech chain model based on deep learning. The sequence-to-sequence model in close-loop architecture allows us to train our model on the concatenation of both labeled and unlabeled data. While ASR transcribes the unlabeled speech features, TTS attempts to reconstruct the original speech waveform based on the text from ASR. In the opposite direction, ASR also attempts to reconstruct the original text transcription given the synthesized speech. To the best of our knowledge, this is the first deep learning model that integrates human speech perception and production behaviors. Our experimental results show that the proposed approach significantly improved the performance more than separate systems that were only trained with labeled data.
Gated Recurrent Neural Tensor Network
Jun 07, 2017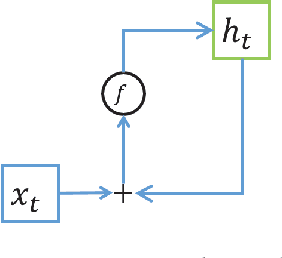
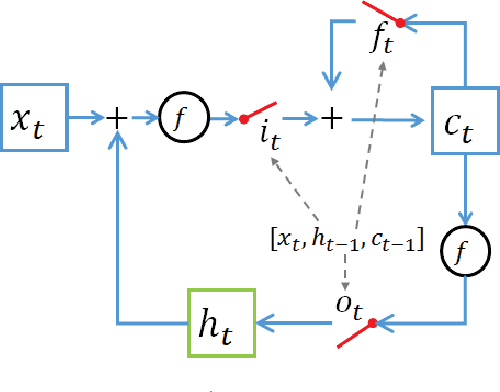
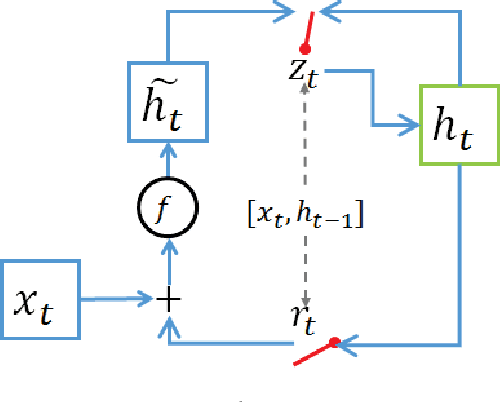
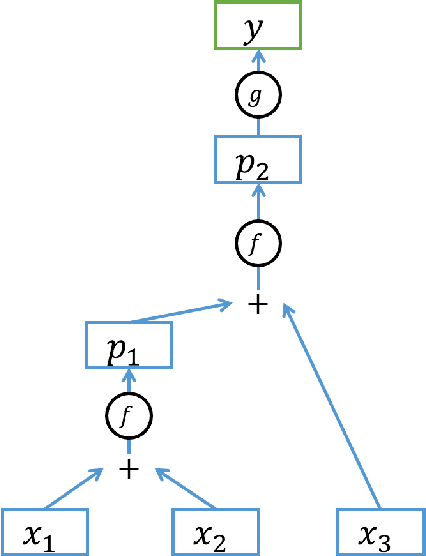
Recurrent Neural Networks (RNNs), which are a powerful scheme for modeling temporal and sequential data need to capture long-term dependencies on datasets and represent them in hidden layers with a powerful model to capture more information from inputs. For modeling long-term dependencies in a dataset, the gating mechanism concept can help RNNs remember and forget previous information. Representing the hidden layers of an RNN with more expressive operations (i.e., tensor products) helps it learn a more complex relationship between the current input and the previous hidden layer information. These ideas can generally improve RNN performances. In this paper, we proposed a novel RNN architecture that combine the concepts of gating mechanism and the tensor product into a single model. By combining these two concepts into a single RNN, our proposed models learn long-term dependencies by modeling with gating units and obtain more expressive and direct interaction between input and hidden layers using a tensor product on 3-dimensional array (tensor) weight parameters. We use Long Short Term Memory (LSTM) RNN and Gated Recurrent Unit (GRU) RNN and combine them with a tensor product inside their formulations. Our proposed RNNs, which are called a Long-Short Term Memory Recurrent Neural Tensor Network (LSTMRNTN) and Gated Recurrent Unit Recurrent Neural Tensor Network (GRURNTN), are made by combining the LSTM and GRU RNN models with the tensor product. We conducted experiments with our proposed models on word-level and character-level language modeling tasks and revealed that our proposed models significantly improved their performance compared to our baseline models.
Compressing Recurrent Neural Network with Tensor Train
May 23, 2017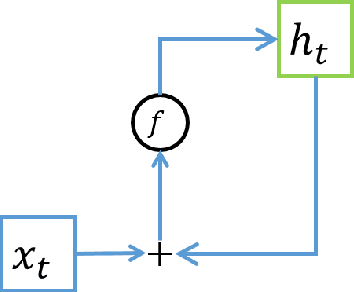
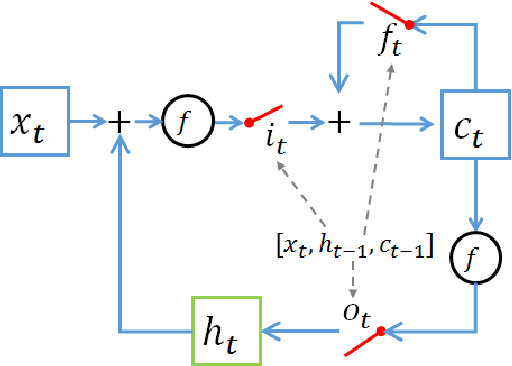
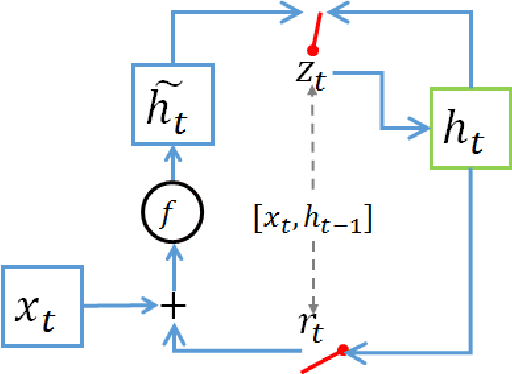
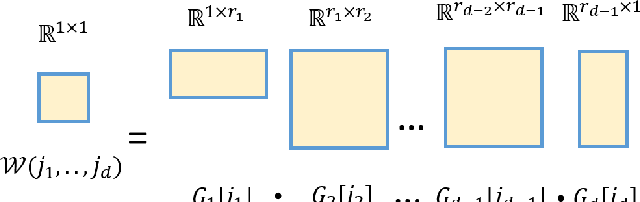
Recurrent Neural Network (RNN) are a popular choice for modeling temporal and sequential tasks and achieve many state-of-the-art performance on various complex problems. However, most of the state-of-the-art RNNs have millions of parameters and require many computational resources for training and predicting new data. This paper proposes an alternative RNN model to reduce the number of parameters significantly by representing the weight parameters based on Tensor Train (TT) format. In this paper, we implement the TT-format representation for several RNN architectures such as simple RNN and Gated Recurrent Unit (GRU). We compare and evaluate our proposed RNN model with uncompressed RNN model on sequence classification and sequence prediction tasks. Our proposed RNNs with TT-format are able to preserve the performance while reducing the number of RNN parameters significantly up to 40 times smaller.