 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaches to the classification of complex systems: Words, texts, and more
May 09, 2022



The Chapter starts with introductory information about quantitative linguistics notions, like rank--frequency dependence, Zipf's law, frequency spectra, etc. Similarities in distributions of words in texts with level occupation in quantum ensembles hint at a superficial analogy with statistical physics. This enables one to define various parameters for texts based on this physical analogy, including "temperature", "chemical potential", entropy, and some others. Such parameters provide a set of variables to classify texts serving as an example of complex systems. Moreover, texts are perhaps the easiest complex systems to collect and analyze. Similar approaches can be developed to study, for instance, genomes due to well-known linguistic analogies. We consider a couple of approaches to define nucleotide sequences in mitochondrial DNAs and viral RNAs and demonstrate their possible application as an auxiliary tool for comparative analysis of genomes. Finally, we discuss entropy as one of the parameters, which can be easily computed from rank--frequency dependences. Being a discriminating parameter in some problems of classification of complex systems, entropy can be given a proper interpretation only in a limited class of problems. Its overall role and significance remain an open issue so far.
Application of a Quantum Ensemble Model to Linguistic Analysis
Nov 23, 2010



A new set of parameters to describe the word frequency behavior of texts is proposed. The analogy between the word frequency distribution and the Bose-distribution is suggested and the notion of "temperature" is introduced for this case. The calculations are made for English, Ukrainian, and the Guinean Maninka languages. The correlation between in-deep language structure (the level of analyticity) and the defined parameters is shown to exist.
* 13 pages; 4 figures; 1 table
Distribution of complexities in the Vai script
Oct 01, 2008



In the paper, we analyze the distribution of complexities in the Vai script, an indigenous syllabic writing system from Liberia. It is found that the uniformity hypothesis for complexities fails for this script. The models using Poisson distribution for the number of components and hyper-Poisson distribution for connections provide good fits in the case of the Vai script.
* 13 pages
Some properties of the Ukrainian writing system
Feb 28, 2008



We investigate the grapheme-phoneme relation in Ukrainian and some properties of the Ukrainian version of the Cyrillic alphabet.
* 17 pages
Online-concordance "Perekhresni stezhky" ("The Cross-Paths"), a novel by Ivan Franko
Jan 21, 2008In the article, theoretical principles and practical realization for the compilation of the concordance to "Perekhresni stezhky" ("The Cross-Paths"), a novel by Ivan Franko, are described. Two forms for the context presentation are proposed. The electronic version of this lexicographic work is available online.
* in Ukrainian
Menzerath-Altmann Law for Syntactic Structures in Ukrainian
Jan 30, 2007
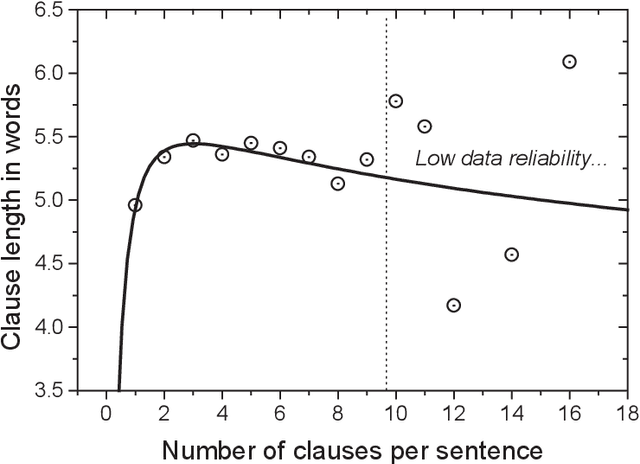


In the paper, the definition of clause suitable for an automated processing of a Ukrainian text is proposed. The Menzerath-Altmann law is verified on the sentence level and the parameters for the dependences of the clause length counted in words and syllables on the sentence length counted in clauses are calculated for "Perekhresni Stezhky" ("The Cross-Paths"), a novel by Ivan Franko.
* 8 pages; submitted to the Proceedings of the International scientific conference on Modern Methods in Linguistics held in honour of the anniversary of Prof. Gabriel L. Altmann (October 23rd and 24th, 2006, Budmerice Castle, Slovakia)
Statistical Parameters of the Novel "Perekhresni stezhky" ("The Cross-Paths") by Ivan Franko
Dec 28, 2005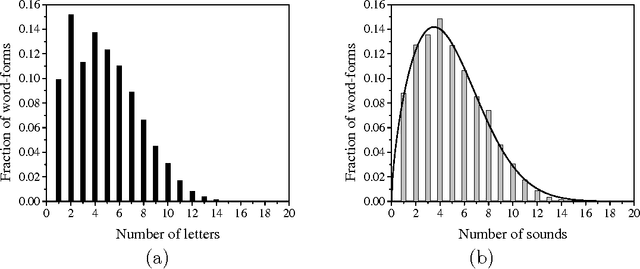



In the paper, a complex statistical characteristics of a Ukrainian novel is given for the first time. The distribution of word-forms with respect to their size is studied. The linguistic laws by Zipf-Mandelbrot and Altmann-Menzerath are analyzed.
* 11 pages