 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards automation of data quality system for CERN CMS experiment
Sep 25, 2017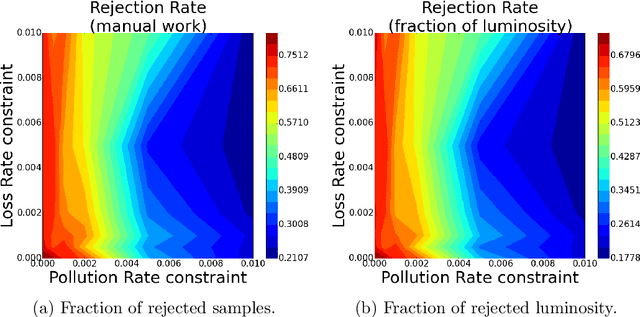
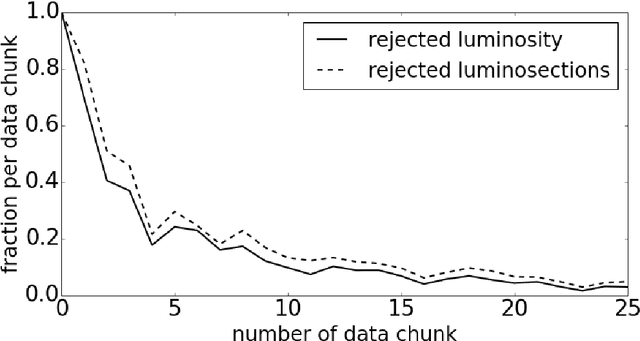
Daily operation of a large-scale experiment is a challenging task, particularly from perspectives of routine monitoring of quality for data being taken. We describe an approach that uses Machine Learning for the automated system to monitor data quality, which is based on partial use of data qualified manually by detector experts. The system automatically classifies marginal cases: both of good an bad data, and use human expert decision to classify remaining "grey area" cases. This study uses collision data collected by the CMS experiment at LHC in 2010. We demonstrate that proposed workflow is able to automatically process at least 20\% of samples without noticeable degradation of the result.
Muon Trigger for Mobile Phones
Sep 25, 2017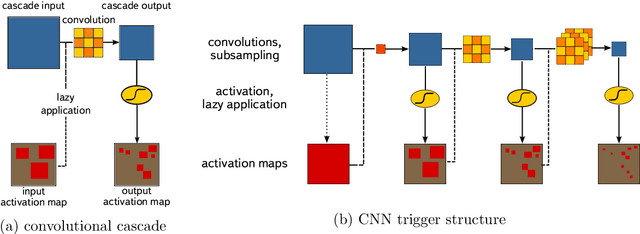

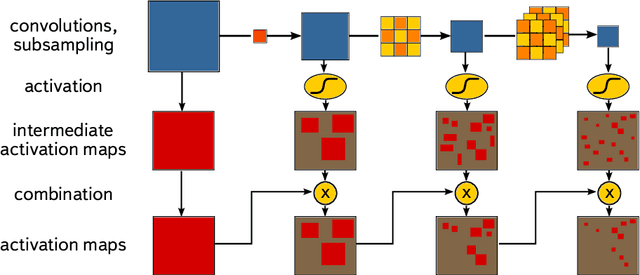

The CRAYFIS experiment proposes to use privately owned mobile phones as a ground detector array for Ultra High Energy Cosmic Rays. Upon interacting with Earth's atmosphere, these events produce extensive particle showers which can be detected by cameras on mobile phones. A typical shower contains minimally-ionizing particles such as muons. As these particles interact with CMOS image sensors, they may leave tracks of faintly-activated pixels that are sometimes hard to distinguish from random detector noise. Triggers that rely on the presence of very bright pixels within an image frame are not efficient in this case. We present a trigger algorithm based on Convolutional Neural Networks which selects images containing such tracks and are evaluated in a lazy manner: the response of each successive layer is computed only if activation of the current layer satisfies a continuation criterion. Usage of neural networks increases the sensitivity considerably comparable with image thresholding, while the lazy evaluation allows for execution of the trigger under the limited computational power of mobile phones.
Disk storage management for LHCb based on Data Popularity estimator
Oct 01, 2015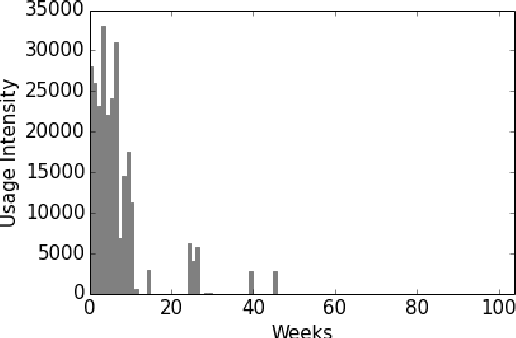



This paper presents an algorithm providing recommendations for optimizing the LHCb data storage. The LHCb data storage system is a hybrid system. All datasets are kept as archives on magnetic tapes. The most popular datasets are kept on disks. The algorithm takes the dataset usage history and metadata (size, type, configuration etc.) to generate a recommendation report. This article presents how we use machine learning algorithms to predict future data popularity. Using these predictions it is possible to estimate which datasets should be removed from disk. We use regression algorithms and time series analysis to find the optimal number of replicas for datasets that are kept on disk. Based on the data popularity and the number of replicas optimization, the algorithm minimizes a loss function to find the optimal data distribution. The loss function represents all requirements for data distribution in the data storage system. We demonstrate how our algorithm helps to save disk space and to reduce waiting times for jobs using this data.
A genetic algorithm for autonomous navigation in partially observable domain
Jul 27, 2015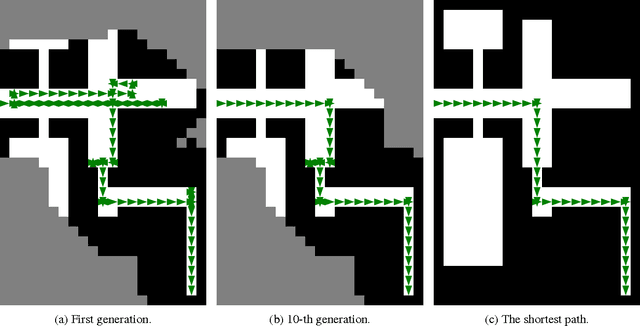

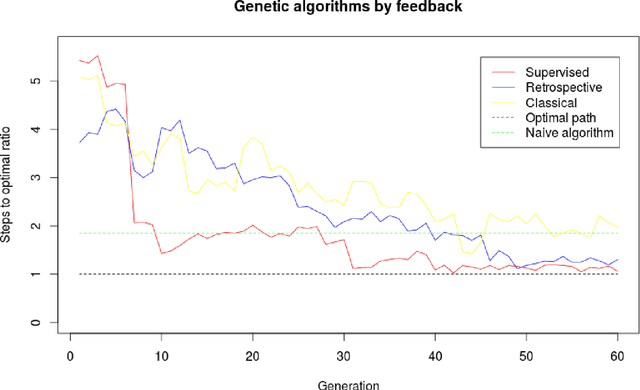
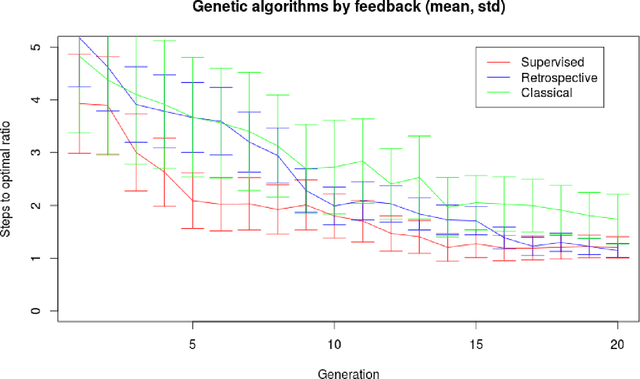
The problem of autonomous navigation is one of the basic problems for robotics. Although, in general, it may be challenging when an autonomous vehicle is placed into partially observable domain. In this paper we consider simplistic environment model and introduce a navigation algorithm based on Learning Classifier System.