 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Hierarchical Algorithm for Extreme Clustering
Apr 06, 2017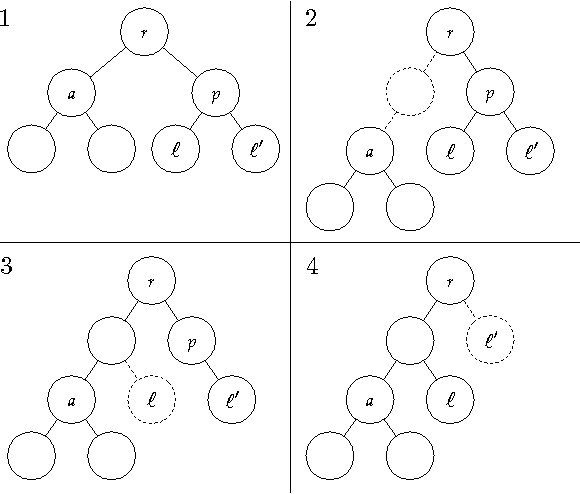
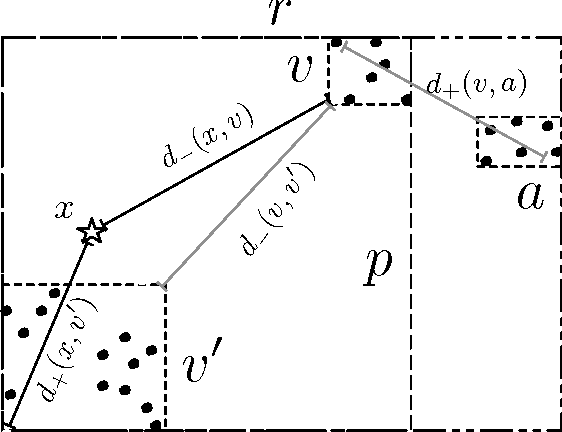

Many modern clustering methods scale well to a large number of data items, N, but not to a large number of clusters, K. This paper introduces PERCH, a new non-greedy algorithm for online hierarchical clustering that scales to both massive N and K--a problem setting we term extreme clustering. Our algorithm efficiently routes new data points to the leaves of an incrementally-built tree. Motivated by the desire for both accuracy and speed, our approach performs tree rotations for the sake of enhancing subtree purity and encouraging balancedness. We prove that, under a natural separability assumption, our non-greedy algorithm will produce trees with perfect dendrogram purity regardless of online data arrival order. Our experiments demonstrate that PERCH constructs more accurate trees than other tree-building clustering algorithms and scales well with both N and K, achieving a higher quality clustering than the strongest flat clustering competitor in nearly half the time.
Learning a Natural Language Interface with Neural Programmer
Mar 02, 2017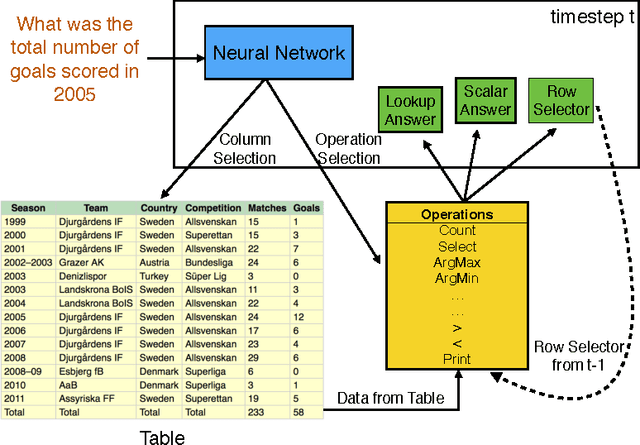
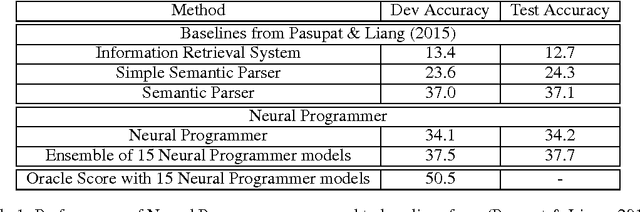

Learning a natural language interface for database tables is a challenging task that involves deep language understanding and multi-step reasoning. The task is often approached by mapping natural language queries to logical forms or programs that provide the desired response when executed on the database. To our knowledge, this paper presents the first weakly supervised, end-to-end neural network model to induce such programs on a real-world dataset. We enhance the objective function of Neural Programmer, a neural network with built-in discrete operations, and apply it on WikiTableQuestions, a natural language question-answering dataset. The model is trained end-to-end with weak supervision of question-answer pairs, and does not require domain-specific grammars, rules, or annotations that are key elements in previous approaches to program induction. The main experimental result in this paper is that a single Neural Programmer model achieves 34.2% accuracy using only 10,000 examples with weak supervision. An ensemble of 15 models, with a trivial combination technique, achieves 37.7% accuracy, which is competitive to the current state-of-the-art accuracy of 37.1% obtained by a traditional natural language semantic parser.
Generalizing to Unseen Entities and Entity Pairs with Row-less Universal Schema
Jan 09, 2017

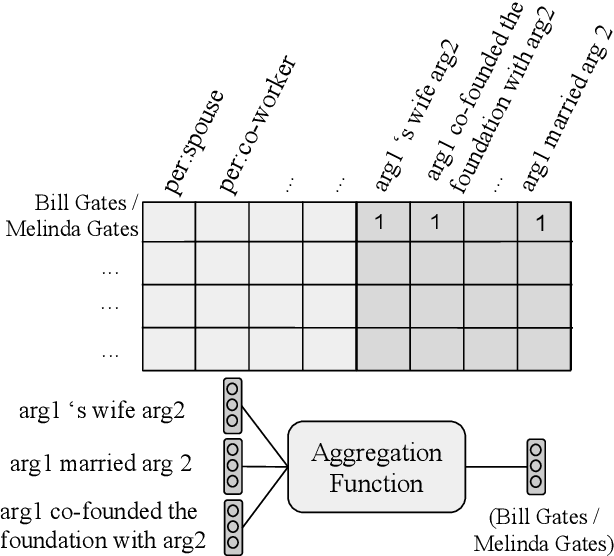
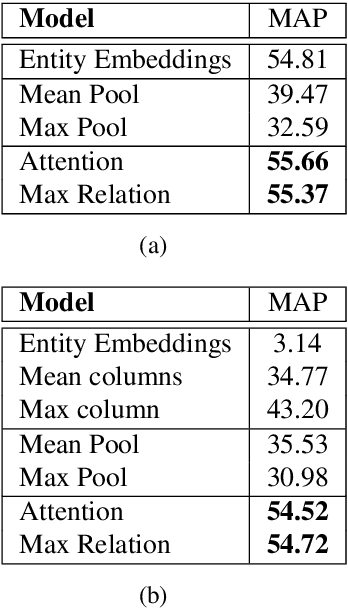
Universal schema predicts the types of entities and relations in a knowledge base (KB) by jointly embedding the union of all available schema types---not only types from multiple structured databases (such as Freebase or Wikipedia infoboxes), but also types expressed as textual patterns from raw text. This prediction is typically modeled as a matrix completion problem, with one type per column, and either one or two entities per row (in the case of entity types or binary relation types, respectively). Factorizing this sparsely observed matrix yields a learned vector embedding for each row and each column. In this paper we explore the problem of making predictions for entities or entity-pairs unseen at training time (and hence without a pre-learned row embedding). We propose an approach having no per-row parameters at all; rather we produce a row vector on the fly using a learned aggregation function of the vectors of the observed columns for that row. We experiment with various aggregation functions, including neural network attention models. Our approach can be understood as a natural language database, in that questions about KB entities are answered by attending to textual or database evidence. In experiments predicting both relations and entity types, we demonstrate that despite having an order of magnitude fewer parameters than traditional universal schema, we can match the accuracy of the traditional model, and more importantly, we can now make predictions about unseen rows with nearly the same accuracy as rows available at training time.
Bethe Projections for Non-Local Inference
Nov 28, 2016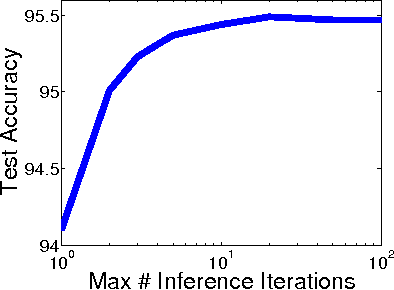

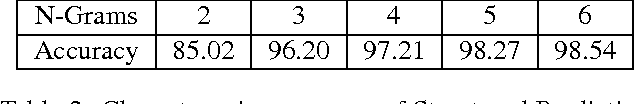
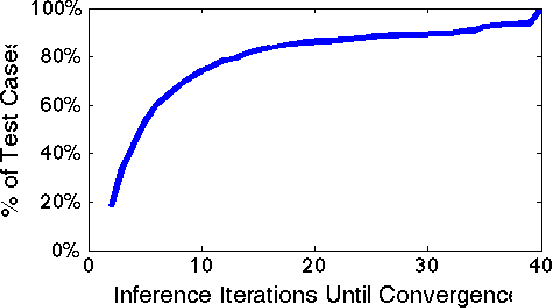
Many inference problems in structured prediction are naturally solved by augmenting a tractable dependency structure with complex, non-local auxiliary objectives. This includes the mean field family of variational inference algorithms, soft- or hard-constrained inference using Lagrangian relaxation or linear programming, collective graphical models, and forms of semi-supervised learning such as posterior regularization. We present a method to discriminatively learn broad families of inference objectives, capturing powerful non-local statistics of the latent variables, while maintaining tractable and provably fast inference using non-Euclidean projected gradient descent with a distance-generating function given by the Bethe entropy. We demonstrate the performance and flexibility of our method by (1) extracting structured citations from research papers by learning soft global constraints, (2) achieving state-of-the-art results on a widely-used handwriting recognition task using a novel learned non-convex inference procedure, and (3) providing a fast and highly scalable algorithm for the challenging problem of inference in a collective graphical model applied to bird migration.
Ask the GRU: Multi-Task Learning for Deep Text Recommendations
Sep 09, 2016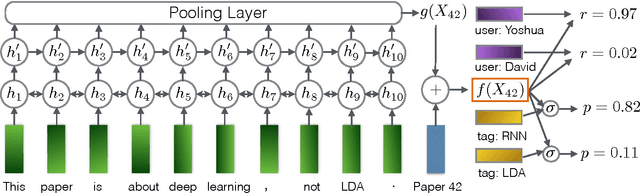
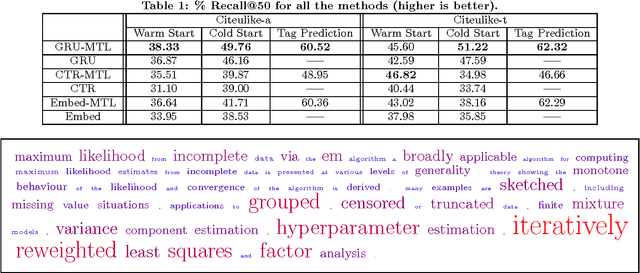

In a variety of application domains the content to be recommended to users is associated with text. This includes research papers, movies with associated plot summaries, news articles, blog posts, etc. Recommendation approaches based on latent factor models can be extended naturally to leverage text by employing an explicit mapping from text to factors. This enables recommendations for new, unseen content, and may generalize better, since the factors for all items are produced by a compactly-parametrized model. Previous work has used topic models or averages of word embeddings for this mapping. In this paper we present a method leveraging deep recurrent neural networks to encode the text sequence into a latent vector, specifically gated recurrent units (GRUs) trained end-to-end on the collaborative filtering task. For the task of scientific paper recommendation, this yields models with significantly higher accuracy. In cold-start scenarios, we beat the previous state-of-the-art, all of which ignore word order. Performance is further improved by multi-task learning, where the text encoder network is trained for a combination of content recommendation and item metadata prediction. This regularizes the collaborative filtering model, ameliorating the problem of sparsity of the observed rating matrix.
Structured Prediction Energy Networks
Jun 23, 2016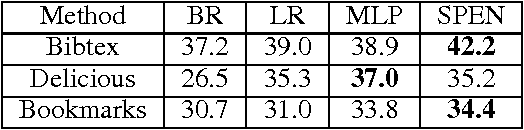
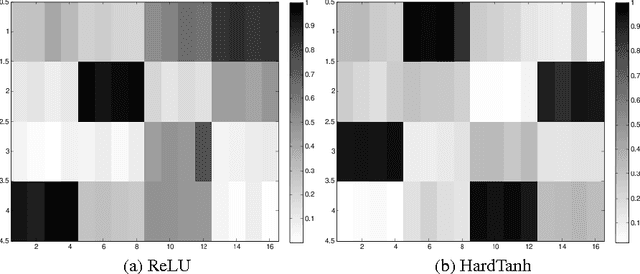

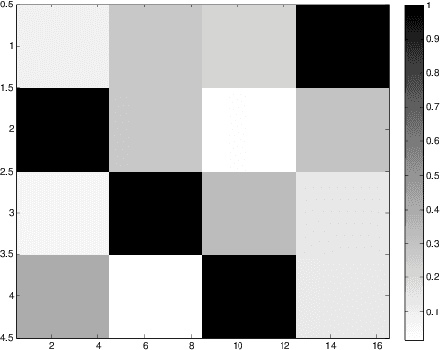
We introduce structured prediction energy networks (SPENs), a flexible framework for structured prediction. A deep architecture is used to define an energy function of candidate labels, and then predictions are produced by using back-propagation to iteratively optimize the energy with respect to the labels. This deep architecture captures dependencies between labels that would lead to intractable graphical models, and performs structure learning by automatically learning discriminative features of the structured output. One natural application of our technique is multi-label classification, which traditionally has required strict prior assumptions about the interactions between labels to ensure tractable learning and prediction. We are able to apply SPENs to multi-label problems with substantially larger label sets than previous applications of structured prediction, while modeling high-order interactions using minimal structural assumptions. Overall, deep learning provides remarkable tools for learning features of the inputs to a prediction problem, and this work extends these techniques to learning features of structured outputs. Our experiments provide impressive performance on a variety of benchmark multi-label classification tasks, demonstrate that our technique can be used to provide interpretable structure learning, and illuminate fundamental trade-offs between feed-forward and iterative structured prediction.
Row-less Universal Schema
Apr 21, 2016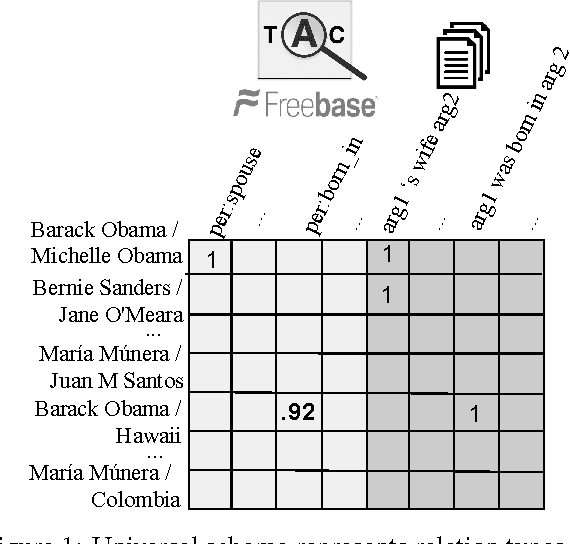
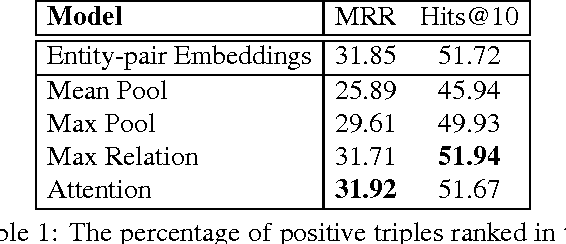
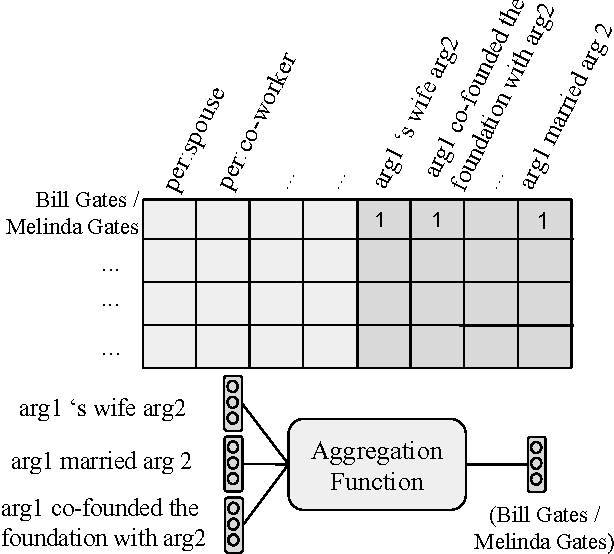
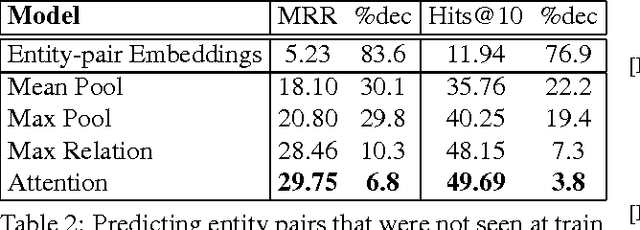
Universal schema jointly embeds knowledge bases and textual patterns to reason about entities and relations for automatic knowledge base construction and information extraction. In the past, entity pairs and relations were represented as learned vectors with compatibility determined by a scoring function, limiting generalization to unseen text patterns and entities. Recently, 'column-less' versions of Universal Schema have used compositional pattern encoders to generalize to all text patterns. In this work we take the next step and propose a 'row-less' model of universal schema, removing explicit entity pair representations. Instead of learning vector representations for each entity pair in our training set, we treat an entity pair as a function of its relation types. In experimental results on the FB15k-237 benchmark we demonstrate that we can match the performance of a comparable model with explicit entity pair representations using a model of attention over relation types. We further demonstrate that the model per- forms with nearly the same accuracy on entity pairs never seen during training.
Multilingual Relation Extraction using Compositional Universal Schema
Mar 03, 2016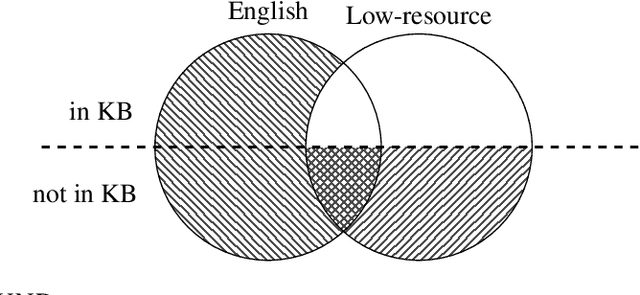

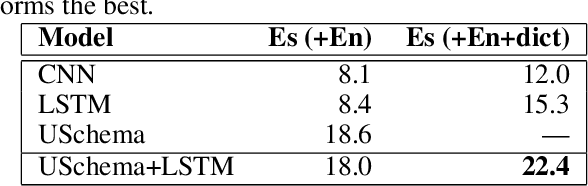

Universal schema builds a knowledge base (KB) of entities and relations by jointly embedding all relation types from input KBs as well as textual patterns expressing relations from raw text. In most previous applications of universal schema, each textual pattern is represented as a single embedding, preventing generalization to unseen patterns. Recent work employs a neural network to capture patterns' compositional semantics, providing generalization to all possible input text. In response, this paper introduces significant further improvements to the coverage and flexibility of universal schema relation extraction: predictions for entities unseen in training and multilingual transfer learning to domains with no annotation. We evaluate our model through extensive experiments on the English and Spanish TAC KBP benchmark, outperforming the top system from TAC 2013 slot-filling using no handwritten patterns or additional annotation. We also consider a multilingual setting in which English training data entities overlap with the seed KB, but Spanish text does not. Despite having no annotation for Spanish data, we train an accurate predictor, with additional improvements obtained by tying word embeddings across languages. Furthermore, we find that multilingual training improves English relation extraction accuracy. Our approach is thus suited to broad-coverage automated knowledge base construction in a variety of languages and domains.
Compositional Vector Space Models for Knowledge Base Completion
May 27, 2015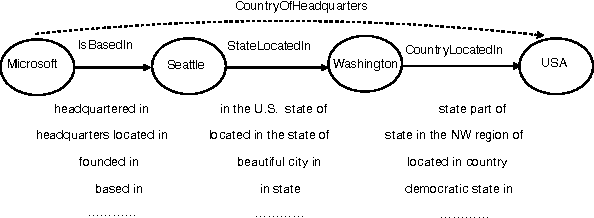

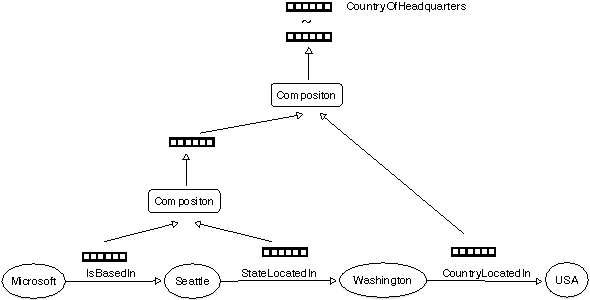

Knowledge base (KB) completion adds new facts to a KB by making inferences from existing facts, for example by inferring with high likelihood nationality(X,Y) from bornIn(X,Y). Most previous methods infer simple one-hop relational synonyms like this, or use as evidence a multi-hop relational path treated as an atomic feature, like bornIn(X,Z) -> containedIn(Z,Y). This paper presents an approach that reasons about conjunctions of multi-hop relations non-atomically, composing the implications of a path using a recursive neural network (RNN) that takes as inputs vector embeddings of the binary relation in the path. Not only does this allow us to generalize to paths unseen at training time, but also, with a single high-capacity RNN, to predict new relation types not seen when the compositional model was trained (zero-shot learning). We assemble a new dataset of over 52M relational triples, and show that our method improves over a traditional classifier by 11%, and a method leveraging pre-trained embeddings by 7%.
Learning Dynamic Feature Selection for Fast Sequential Prediction
May 22, 2015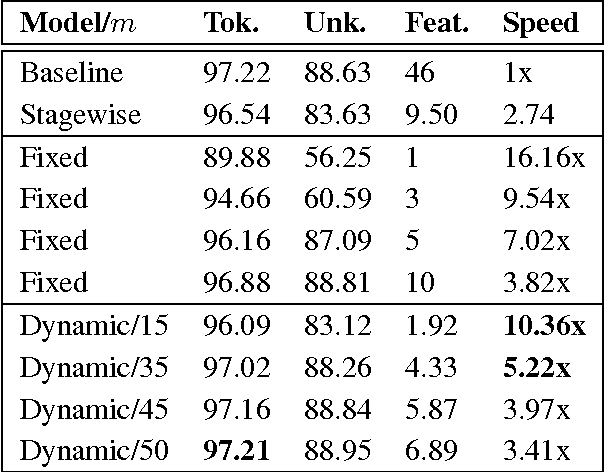
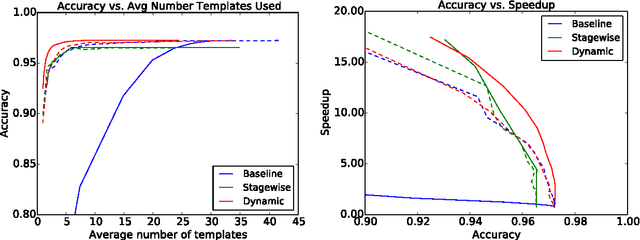
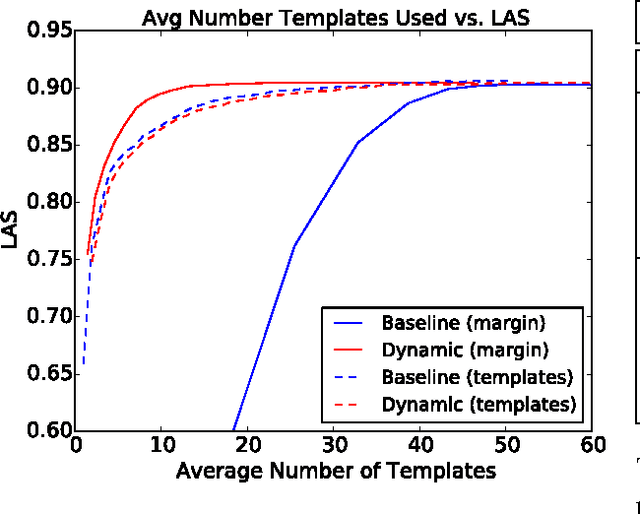
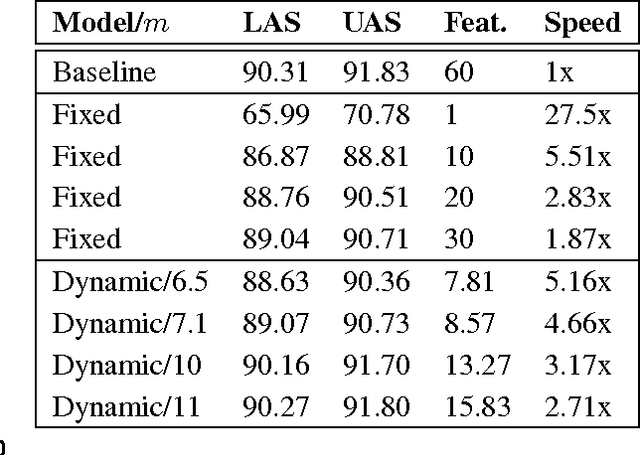
We present paired learning and inference algorithms for significantly reducing computation and increasing speed of the vector dot products in the classifiers that are at the heart of many NLP components. This is accomplished by partitioning the features into a sequence of templates which are ordered such that high confidence can often be reached using only a small fraction of all features. Parameter estimation is arranged to maximize accuracy and early confidence in this sequence. Our approach is simpler and better suited to NLP than other related cascade methods. We present experiments in left-to-right part-of-speech tagging, named entity recognition, and transition-based dependency parsing. On the typical benchmarking datasets we can preserve POS tagging accuracy above 97% and parsing LAS above 88.5% both with over a five-fold reduction in run-time, and NER F1 above 88 with more than 2x increase in speed.