 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Machines for Deep RL in Noisy and Uncertain Environments
May 31, 2024



Reward Machines provide an automata-inspired structure for specifying instructions, safety constraints, and other temporally extended reward-worthy behaviour. By exposing complex reward function structure, they enable counterfactual learning updates that have resulted in impressive sample efficiency gains. While Reward Machines have been employed in both tabular and deep RL settings, they have typically relied on a ground-truth interpretation of the domain-specific vocabulary that form the building blocks of the reward function. Such ground-truth interpretations can be elusive in many real-world settings, due in part to partial observability or noisy sensing. In this paper, we explore the use of Reward Machines for Deep RL in noisy and uncertain environments. We characterize this problem as a POMDP and propose a suite of RL algorithms that leverage task structure under uncertain interpretation of domain-specific vocabulary. Theoretical analysis exposes pitfalls in naive approaches to this problem, while experimental results show that our algorithms successfully leverage task structure to improve performance under noisy interpretations of the vocabulary. Our results provide a general framework for exploiting Reward Machines in partially observable environments.
Learning Symbolic Representations for Reinforcement Learning of Non-Markovian Behavior
Jan 08, 2023

Many real-world reinforcement learning (RL) problems necessitate learning complex, temporally extended behavior that may only receive reward signal when the behavior is completed. If the reward-worthy behavior is known, it can be specified in terms of a non-Markovian reward function - a function that depends on aspects of the state-action history, rather than just the current state and action. Such reward functions yield sparse rewards, necessitating an inordinate number of experiences to find a policy that captures the reward-worthy pattern of behavior. Recent work has leveraged Knowledge Representation (KR) to provide a symbolic abstraction of aspects of the state that summarize reward-relevant properties of the state-action history and support learning a Markovian decomposition of the problem in terms of an automaton over the KR. Providing such a decomposition has been shown to vastly improve learning rates, especially when coupled with algorithms that exploit automaton structure. Nevertheless, such techniques rely on a priori knowledge of the KR. In this work, we explore how to automatically discover useful state abstractions that support learning automata over the state-action history. The result is an end-to-end algorithm that can learn optimal policies with significantly fewer environment samples than state-of-the-art RL on simple non-Markovian domains.
Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines
Nov 23, 2022



Natural and formal languages provide an effective mechanism for humans to specify instructions and reward functions. We investigate how to generate policies via RL when reward functions are specified in a symbolic language captured by Reward Machines, an increasingly popular automaton-inspired structure. We are interested in the case where the mapping of environment state to a symbolic (here, Reward Machine) vocabulary -- commonly known as the labelling function -- is uncertain from the perspective of the agent. We formulate the problem of policy learning in Reward Machines with noisy symbolic abstractions as a special class of POMDP optimization problem, and investigate several methods to address the problem, building on existing and new techniques, the latter focused on predicting Reward Machine state, rather than on grounding of individual symbols. We analyze these methods and evaluate them experimentally under varying degrees of uncertainty in the correct interpretation of the symbolic vocabulary. We verify the strength of our approach and the limitation of existing methods via an empirical investigation on both illustrative, toy domains and partially observable, deep RL domains.
Learning to Follow Instructions in Text-Based Games
Nov 08, 2022



Text-based games present a unique class of sequential decision making problem in which agents interact with a partially observable, simulated environment via actions and observations conveyed through natural language. Such observations typically include instructions that, in a reinforcement learning (RL) setting, can directly or indirectly guide a player towards completing reward-worthy tasks. In this work, we study the ability of RL agents to follow such instructions. We conduct experiments that show that the performance of state-of-the-art text-based game agents is largely unaffected by the presence or absence of such instructions, and that these agents are typically unable to execute tasks to completion. To further study and address the task of instruction following, we equip RL agents with an internal structured representation of natural language instructions in the form of Linear Temporal Logic (LTL), a formal language that is increasingly used for temporally extended reward specification in RL. Our framework both supports and highlights the benefit of understanding the temporal semantics of instructions and in measuring progress towards achievement of such a temporally extended behaviour. Experiments with 500+ games in TextWorld demonstrate the superior performance of our approach.
Challenges to Solving Combinatorially Hard Long-Horizon Deep RL Tasks
Jun 03, 2022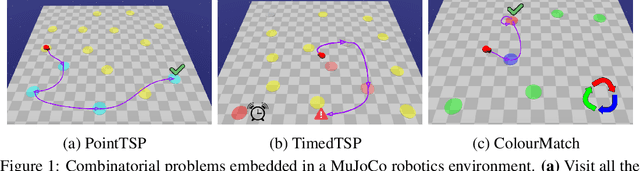
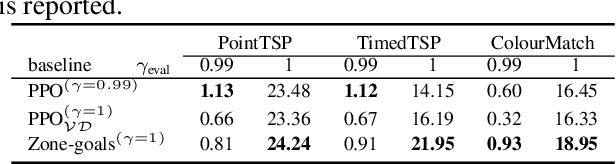
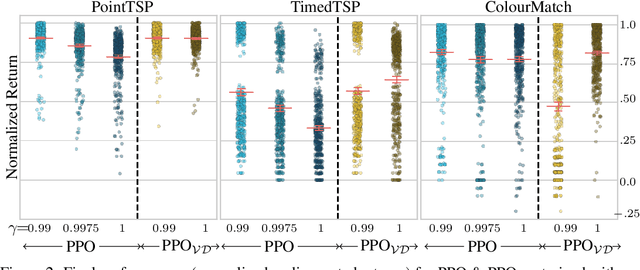
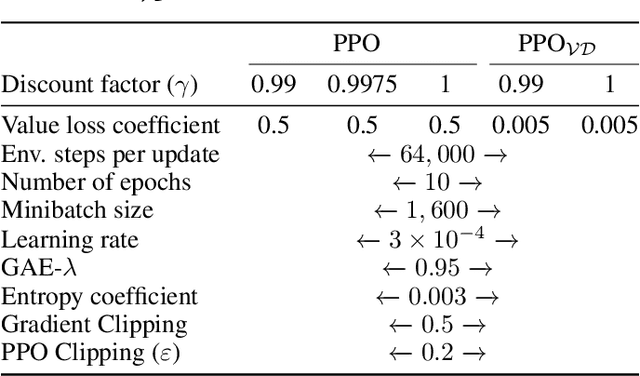
Deep reinforcement learning has shown promise in discrete domains requiring complex reasoning, including games such as Chess, Go, and Hanabi. However, this type of reasoning is less often observed in long-horizon, continuous domains with high-dimensional observations, where instead RL research has predominantly focused on problems with simple high-level structure (e.g. opening a drawer or moving a robot as fast as possible). Inspired by combinatorially hard optimization problems, we propose a set of robotics tasks which admit many distinct solutions at the high-level, but require reasoning about states and rewards thousands of steps into the future for the best performance. Critically, while RL has traditionally suffered on complex, long-horizon tasks due to sparse rewards, our tasks are carefully designed to be solvable without specialized exploration. Nevertheless, our investigation finds that standard RL methods often neglect long-term effects due to discounting, while general-purpose hierarchical RL approaches struggle unless additional abstract domain knowledge can be exploited.
Interpretable Sequence Classification via Discrete Optimization
Oct 06, 2020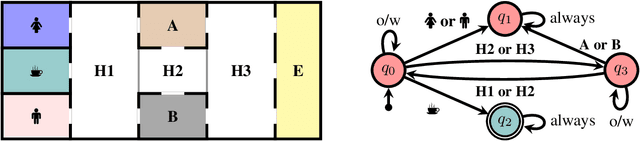
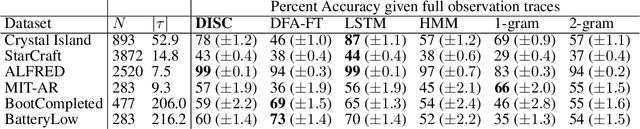
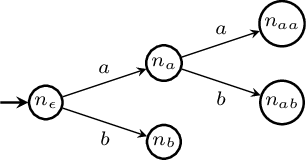
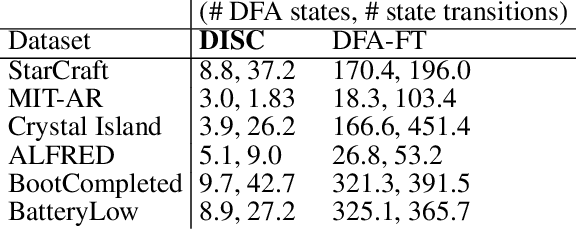
Sequence classification is the task of predicting a class label given a sequence of observations. In many applications such as healthcare monitoring or intrusion detection, early classification is crucial to prompt intervention. In this work, we learn sequence classifiers that favour early classification from an evolving observation trace. While many state-of-the-art sequence classifiers are neural networks, and in particular LSTMs, our classifiers take the form of finite state automata and are learned via discrete optimization. Our automata-based classifiers are interpretable---supporting explanation, counterfactual reasoning, and human-in-the-loop modification---and have strong empirical performance. Experiments over a suite of goal recognition and behaviour classification datasets show our learned automata-based classifiers to have comparable test performance to LSTM-based classifiers, with the added advantage of being interpretable.