 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Deep Transformer-Based Models for Long-Term Prediction of Transient Production of Oil Wells
Oct 12, 2021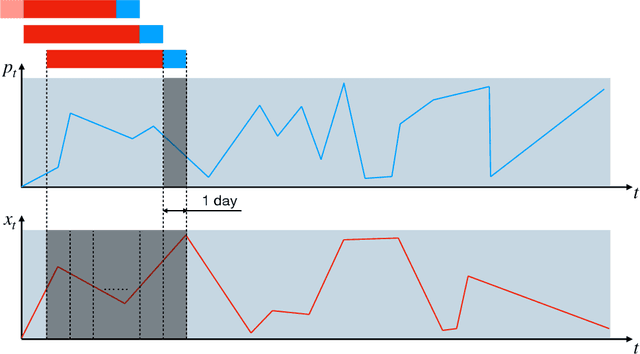

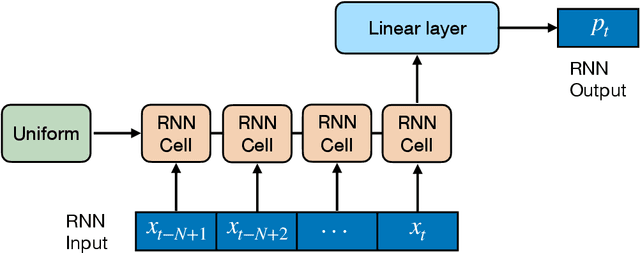

We propose a novel approach to data-driven modeling of a transient production of oil wells. We apply the transformer-based neural networks trained on the multivariate time series composed of various parameters of oil wells measured during their exploitation. By tuning the machine learning models for a single well (ignoring the effect of neighboring wells) on the open-source field datasets, we demonstrate that transformer outperforms recurrent neural networks with LSTM/GRU cells in the forecasting of the bottomhole pressure dynamics. We apply the transfer learning procedure to the transformer-based surrogate model, which includes the initial training on the dataset from a certain well and additional tuning of the model's weights on the dataset from a target well. Transfer learning approach helps to improve the prediction capability of the model. Next, we generalize the single-well model based on the transformer architecture for multiple wells to simulate complex transient oilfield-level patterns. In other words, we create the global model which deals with the dataset, comprised of the production history from multiple wells, and allows for capturing the well interference resulting in more accurate prediction of the bottomhole pressure or flow rate evolutions for each well under consideration. The developed instruments for a single-well and oilfield-scale modelling can be used to optimize the production process by selecting the operating regime and submersible equipment to increase the hydrocarbon recovery. In addition, the models can be helpful to perform well-testing avoiding costly shut-in operations.
Data-driven model for hydraulic fracturing design optimization. Part II: Inverse problem
Aug 02, 2021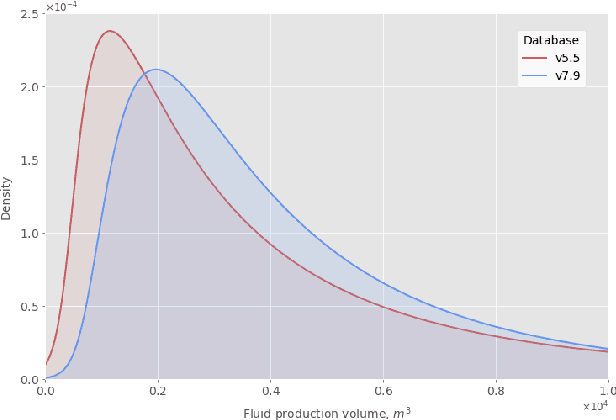
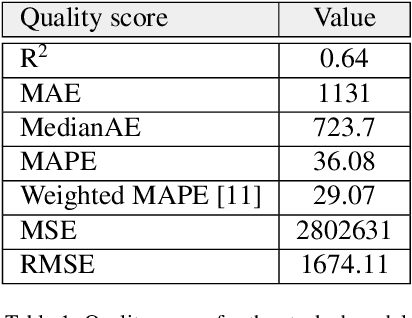
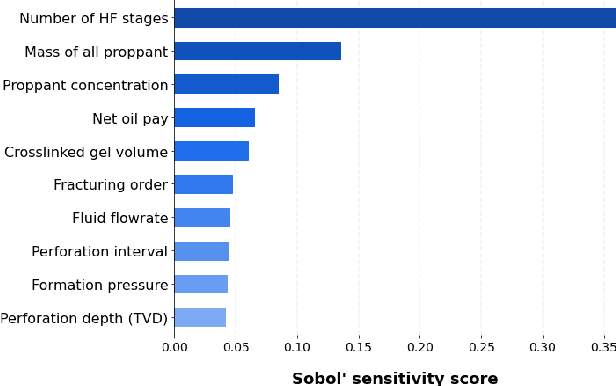
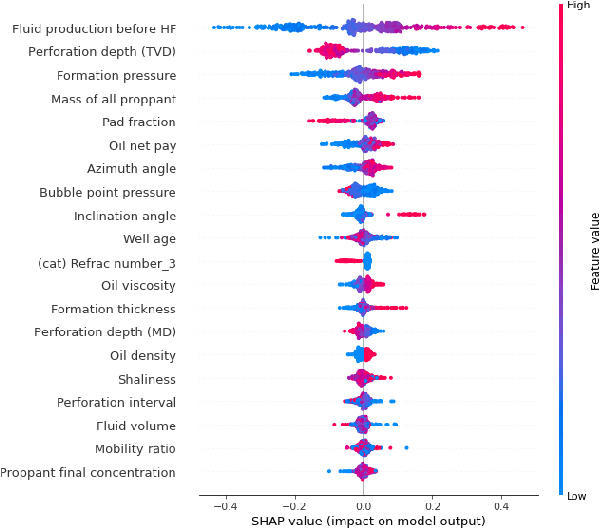
We describe a stacked model for predicting the cumulative fluid production for an oil well with a multistage-fracture completion based on a combination of Ridge Regression and CatBoost algorithms. The model is developed based on an extended digital field data base of reservoir, well and fracturing design parameters. The database now includes more than 5000 wells from 23 oilfields of Western Siberia (Russia), with 6687 fracturing operations in total. Starting with 387 parameters characterizing each well, including construction, reservoir properties, fracturing design features and production, we end up with 38 key parameters used as input features for each well in the model training process. The model demonstrates physically explainable dependencies plots of the target on the design parameters (number of stages, proppant mass, average and final proppant concentrations and fluid rate). We developed a set of methods including those based on the use of Euclidean distance and clustering techniques to perform similar (offset) wells search, which is useful for a field engineer to analyze earlier fracturing treatments on similar wells. These approaches are also adapted for obtaining the optimization parameters boundaries for the particular pilot well, as part of the field testing campaign of the methodology. An inverse problem (selecting an optimum set of fracturing design parameters to maximize production) is formulated as optimizing a high dimensional black box approximation function constrained by boundaries and solved with four different optimization methods: surrogate-based optimization, sequential least squares programming, particle swarm optimization and differential evolution. A recommendation system containing all the above methods is designed to advise a production stimulation engineer on an optimized fracturing design.
A Predictive Model for Steady-State Multiphase Pipe Flow: Machine Learning on Lab Data
May 23, 2019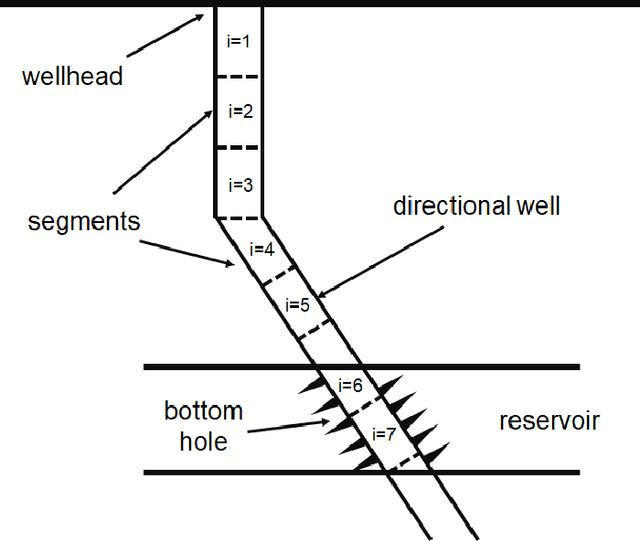
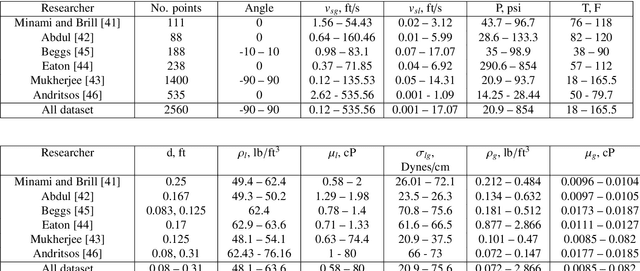
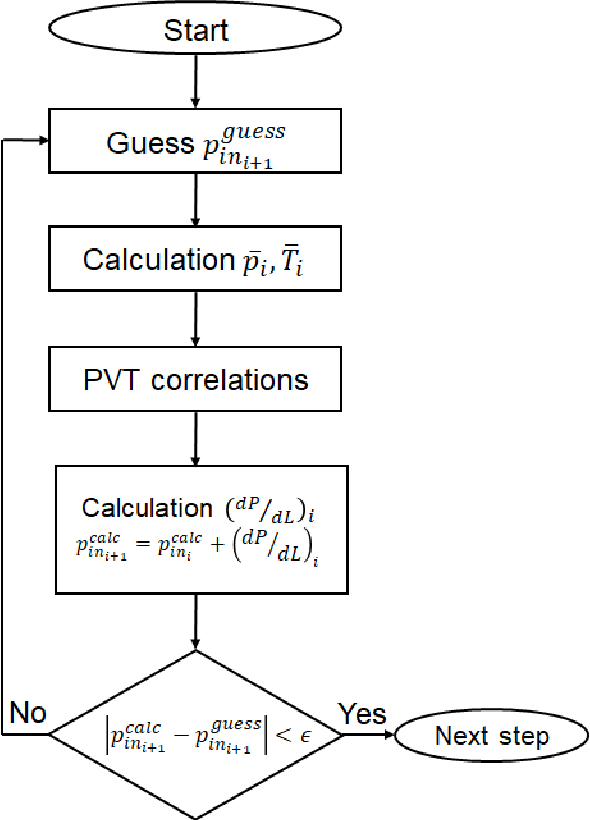
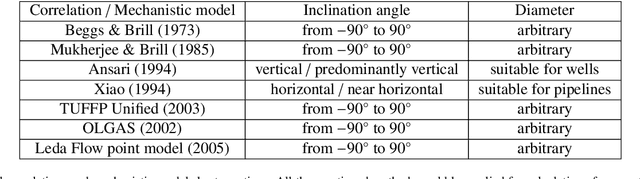
Engineering simulators used for steady-state multiphase pipe flows are commonly utilized to predict pressure drop. Such simulators are typically based on either empirical correlations or first-principles mechanistic models. The simulators allow evaluating the pressure drop in multiphase pipe flow with acceptable accuracy. However, the only shortcoming of these correlations and mechanistic models is their applicability. In order to extend the applicability and the accuracy of the existing accessible methods, a method of pressure drop calculation in the pipeline is proposed. The method is based on well segmentation and calculation of the pressure gradient in each segment using three surrogate models based on Machine Learning algorithms trained on a representative lab data set from the open literature. The first model predicts the value of a liquid holdup in the segment, the second one determines the flow pattern, and the third one is used to estimate the pressure gradient. To build these models, several ML algorithms are trained such as Random Forest, Gradient Boosting Decision Trees, Support Vector Machine, and Artificial Neural Network, and their predictive abilities are cross-compared. The proposed method for pressure gradient calculation yields $R^2 = 0.95$ by using the Gradient Boosting algorithm as compared with $R^2 = 0.92$ in case of Mukherjee and Brill correlation and $R^2 = 0.91$ when a combination of Ansari and Xiao mechanistic models is utilized. The method for pressure drop prediction is also validated on three real field cases. Validation indicates that the proposed model yields the following coefficients of determination: $R^2 = 0.806, 0.815$ and 0.99 as compared with the highest values obtained by commonly used techniques: $R^2 = 0.82$ (Beggs and Brill correlation), $R^2 = 0.823$ (Mukherjee and Brill correlation) and $R^2 = 0.98$ (Beggs and Brill correlation).