 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Course of News Events: A Comparison of Bottom-Up and Top-Down Approaches for Collecting Text-Based Data about Disasters
Jul 01, 2026News articles are an important source of information on disaster impacts and adaptation. A key methodological challenge in socio-environmental studies is how to select a representative data sample. Two approaches are common: querying news databases top-down with the aid of an existing disaster inventory or using NLP methods to cluster news texts bottom-up based on temporal and spatial features. Using a dataset of German news about landslides worldwide, we compare these approaches and discuss variations in event coverage. Such research design decision can influence the resulting news sample, affecting its use in studies of inequality in media coverage, disaster monitoring and inventory enrichment.
The Newsworthiness of Brazilian Distress: A Peak Analysis on Time Series of International Media Attention to Disasters in Brazil
May 06, 2026Media coverage influences disaster response, yet the drivers of international media attention to local events remain unevenly understood. Brazil offers a compelling case: some of its natural and technological disasters occasionally hit the international headlines. However, systematic analyses of what makes these events be discussed abroad are still missing. Addressing this gap requires representative, validated and country-specific news datasets. This paper presents a peak analysis of 2k news about Brazilian fires and landslides in German newspapers from 2000 to 2024. Using time series segmentation to detect news event peaks, we examine the extent to which they can be temporally aligned with observations in national and global disaster databases.
Geolocating News about Extreme Climate Events: A Comparative Analysis of Off-the-Shelf Tools for Toponym Identification in German
May 05, 2026Determining the geolocation of extreme climate events and disasters in texts is a common problem in climate impact and adaptation research. Named-entity recognition (NER) tools are typically used to identify a pool of toponyms that serve as candidate event locations. In this study, we conduct a comparative analysis of three off-the-shelf NER tools, namely Flair, Spacy and Stanza. We describe and quantify differences between their outputs for German news articles and evaluate them extrinsically based on three methods to determine the country where events took place. We show how their contrasts are propagated into downstream tasks and can yield distinct decisions about a document's geographical focus, which, in turn, can impact conclusions about countries' prominence in German media.
Retrieving Floods without Floodlights: Topic Models as Binary Classifiers for Extreme Climate Events in German News
May 05, 2026In studies of media coverage of extreme climate events, NLP methods have become indispensable for identifying relevant texts in large news databases. Still, enough annotated data to train accurate deep learning-based classifiers from scratch is often not available. Topic Models have the advantage of being both unsupervised and interpretable, but are typically used only for exploratory analysis or data characterisation. In this study, we investigate how to employ Topic Models as binary classifiers for refining the retrieval of relevant news about seven types of extreme climate events in the German media. Our method relies on the posterior distributions estimated by Topic Models to select relevant documents, without modifying their training procedure. Using an annotated sample to guide the evaluation, we show that the probabilities assigned to keywords used to query news databases can also be informative for selecting relevant topics and improve sample precision. We compare our results to a fine-tuned text embedding classifier and an open-weight LLM, discussing observed trade-offs, e.g. the LLM's lowest precision. Moreover, we show that results are hazard-dependent, which speaks against considering climate events as a single category in NLP tasks.
Using Language Models on Low-end Hardware
May 08, 2023This paper evaluates the viability of using fixed language models for training text classification networks on low-end hardware. We combine language models with a CNN architecture and put together a comprehensive benchmark with 8 datasets covering single-label and multi-label classification of topic, sentiment, and genre. Our observations are distilled into a list of trade-offs, concluding that there are scenarios, where not fine-tuning a language model yields competitive effectiveness at faster training, requiring only a quarter of the memory compared to fine-tuning.
Using Text Classification with a Bayesian Correction for Estimating Overreporting in the Creditor Reporting System on Climate Adaptation Finance
Nov 30, 2022Development funds are essential to finance climate change adaptation and are thus an important part of international climate policy. % However, the absence of a common reporting practice makes it difficult to assess the amount and distribution of such funds. Research has questioned the credibility of reported figures, indicating that adaptation financing is in fact lower than published figures suggest. Projects claiming a greater relevance to climate change adaptation than they target are referred to as "overreported". To estimate realistic rates of overreporting in large data sets over times, we propose an approach based on state-of-the-art text classification. To date, assessments of credibility have relied on small, manually evaluated samples. We use such a sample data set to train a classifier with an accuracy of $89.81\% \pm 0.83\%$ (tenfold cross-validation) and extrapolate to larger data sets to identify overreporting. Additionally, we propose a method that incorporates evidence of smaller, higher-quality data to correct predicted rates using Bayes' theorem. This enables a comparison of different annotation schemes to estimate the degree of overreporting in climate change adaptation. Our results support findings that indicate extensive overreporting of $32.03\%$ with a credible interval of $[19.81\%;48.34\%]$.
Application of the interactive Leipzig Corpus Miner as a generic research platform for the use in the social sciences
Oct 06, 2021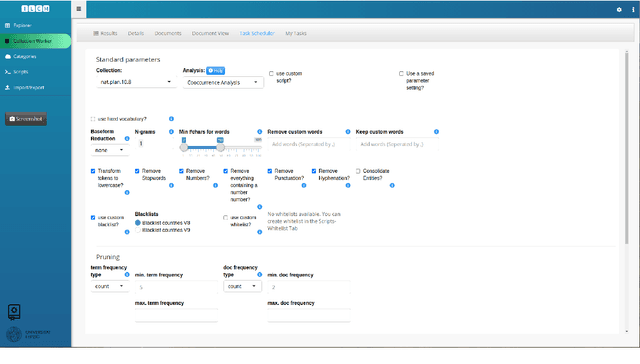

This article introduces to the interactive Leipzig Corpus Miner (iLCM) - a newly released, open-source software to perform automatic content analysis. Since the iLCM is based on the R-programming language, its generic text mining procedures provided via a user-friendly graphical user interface (GUI) can easily be extended using the integrated IDE RStudio-Server or numerous other interfaces in the tool. Furthermore, the iLCM offers various possibilities to use quantitative and qualitative research approaches in combination. Some of these possibilities will be presented in more detail in the following.
Small-text: Active Learning for Text Classification in Python
Jul 21, 2021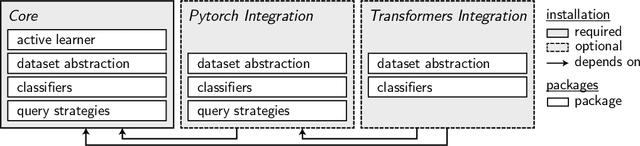

We present small-text, a simple modular active learning library, which offers pool-based active learning for text classification in Python. It comes with various pre-implemented state-of-the-art query strategies, including some which can leverage the GPU. Clearly defined interfaces allow to combine a multitude of such query strategies with different classifiers, thereby facilitating a quick mix and match, and enabling a rapid development of both active learning experiments and applications. To make various classifiers accessible in a consistent way, it integrates several well-known machine learning libraries, namely, scikit-learn, PyTorch, and huggingface transformers -- for which the latter integrations are available as optionally installable extensions. The library is available under the MIT License at https://github.com/webis-de/small-text.
Uncertainty-based Query Strategies for Active Learning with Transformers
Jul 12, 2021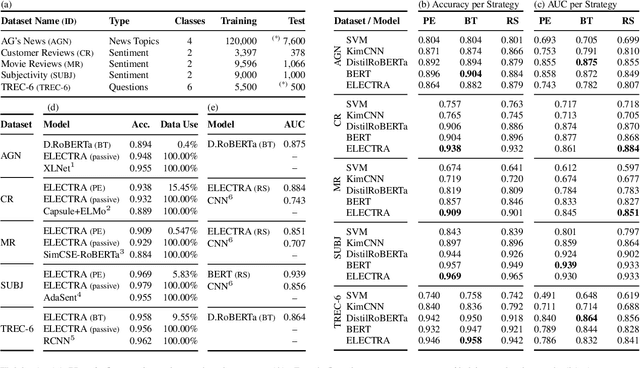
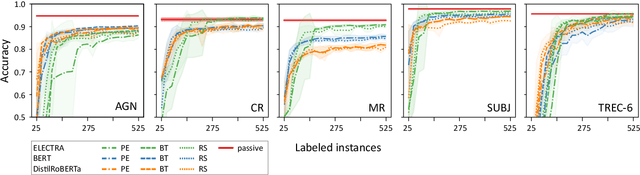
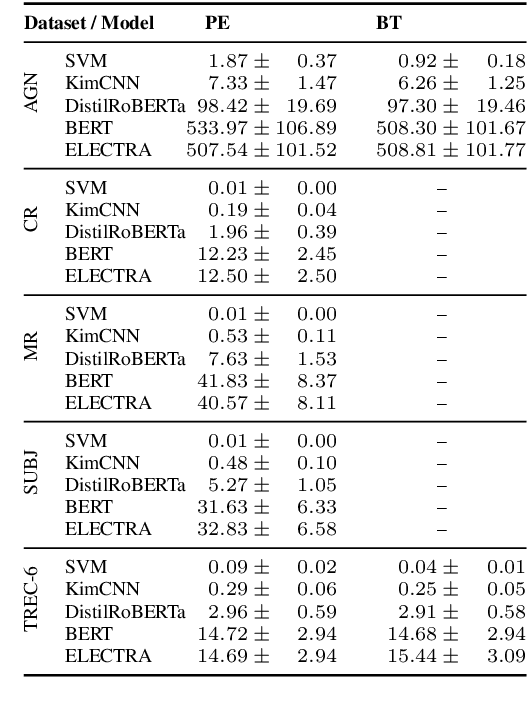
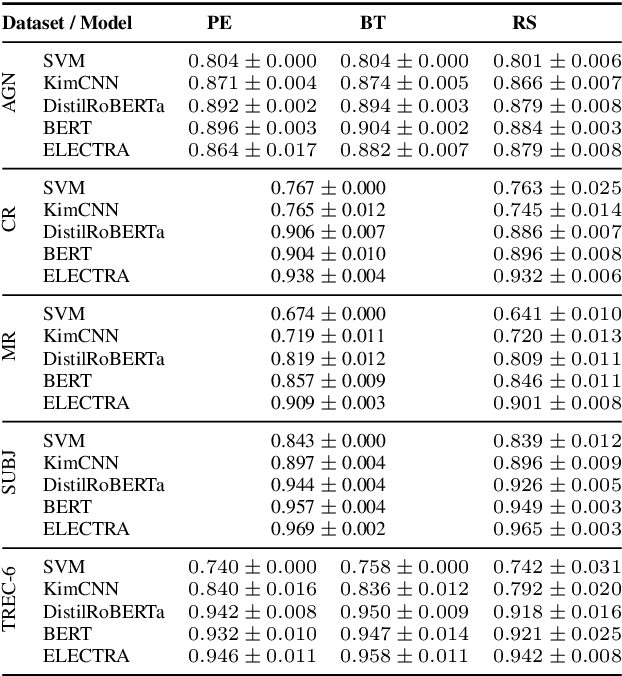
Active learning is the iterative construction of a classification model through targeted labeling, enabling significant labeling cost savings. As most research on active learning has been carried out before transformer-based language models ("transformers") became popular, despite its practical importance, comparably few papers have investigated how transformers can be combined with active learning to date. This can be attributed to the fact that using state-of-the-art query strategies for transformers induces a prohibitive runtime overhead, which effectively cancels out, or even outweighs aforementioned cost savings. In this paper, we revisit uncertainty-based query strategies, which had been largely outperformed before, but are particularly suited in the context of fine-tuning transformers. In an extensive evaluation on five widely used text classification benchmarks, we show that considerable improvements of up to 14.4 percentage points in area under the learning curve are achieved, as well as a final accuracy close to the state of the art for all but one benchmark, using only between 0.4% and 15% of the training data.
Mining Legacy Issues in Open Pit Mining Sites: Innovation & Support of Renaturalization and Land Utilization
May 13, 2021
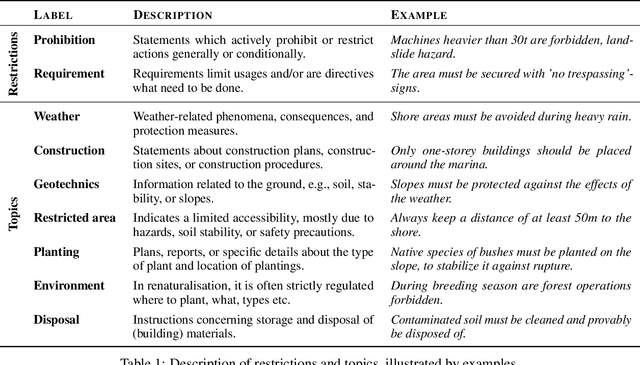
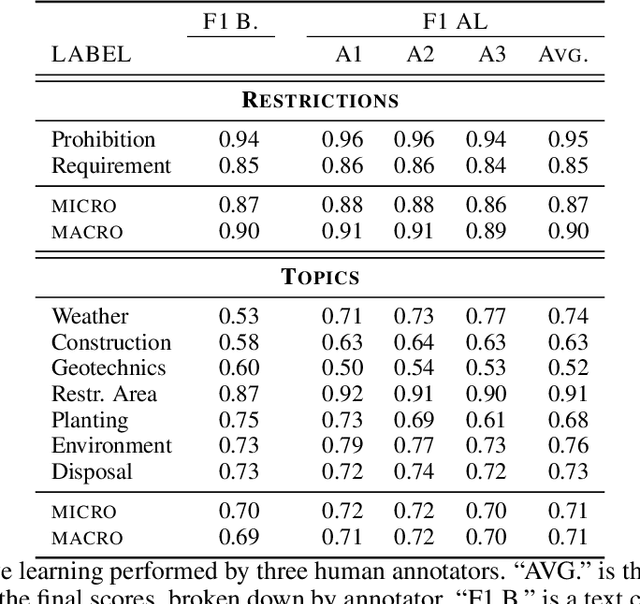
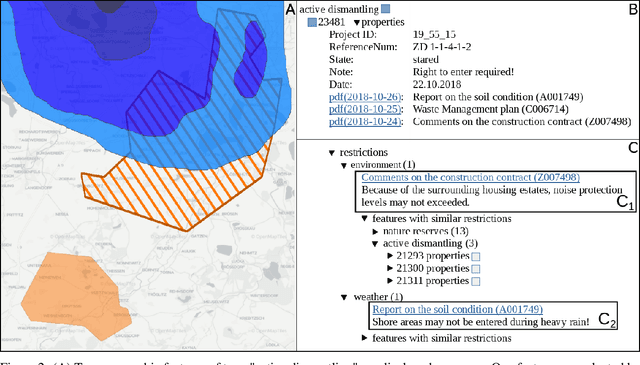
Open pit mines left many regions worldwide inhospitable or uninhabitable. To put these regions back into use, entire stretches of land must be renaturalized. For the sustainable subsequent use or transfer to a new primary use, many contaminated sites and soil information have to be permanently managed. In most cases, this information is available in the form of expert reports in unstructured data collections or file folders, which in the best case are digitized. Due to size and complexity of the data, it is difficult for a single person to have an overview of this data in order to be able to make reliable statements. This is one of the most important obstacles to the rapid transfer of these areas to after-use. An information-based approach to this issue supports fulfilling several Sustainable Development Goals regarding environment issues, health and climate action. We use a stack of Optical Character Recognition, Text Classification, Active Learning and Geographic Information System Visualization to effectively mine and visualize this information. Subsequently, we link the extracted information to geographic coordinates and visualize them using a Geographic Information System. Active Learning plays a vital role because our dataset provides no training data. In total, we process nine categories and actively learn their representation in our dataset. We evaluate the OCR, Active Learning and Text Classification separately to report the performance of the system. Active Learning and text classification results are twofold: Whereas our categories about restrictions work sufficient ($>$.85 F1), the seven topic-oriented categories were complicated for human coders and hence the results achieved mediocre evaluation scores ($<$.70 F1).