 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Guessing: a Verifiable Gradient Inversion Attack in Federated Learning
Apr 16, 2026Gradient inversion attacks threaten client privacy in federated learning by reconstructing training samples from clients' shared gradients. Gradients aggregate contributions from multiple records and existing attacks may fail to disentangle them, yielding incorrect reconstructions with no intrinsic way to certify success. In vision and language, attackers may fall back on human inspection to judge reconstruction plausibility, but this is far less feasible for numerical tabular records, fueling the impression that tabular data is less vulnerable. We challenge this perception by proposing a verifiable gradient inversion attack (VGIA) that provides an explicit certificate of correctness for reconstructed samples. Our method adopts a geometric view of ReLU leakage: the activation boundary of a fully connected layer defines a hyperplane in input space. VGIA introduces an algebraic, subspace-based verification test that detects when a hyperplane-delimited region contains exactly one record. Once isolation is certified, VGIA recovers the corresponding feature vector analytically and reconstructs the target via a lightweight optimization step. Experiments on tabular benchmarks with large batch sizes demonstrate exact record and target recovery in regimes where existing state-of-the-art attacks either fail or cannot assess reconstruction fidelity. Compared to prior geometric approaches, VGIA allocates hyperplane queries more effectively, yielding faster reconstructions with fewer attack rounds.
Improved Learning via k-DTW: A Novel Dissimilarity Measure for Curves
May 29, 2025This paper introduces $k$-Dynamic Time Warping ($k$-DTW), a novel dissimilarity measure for polygonal curves. $k$-DTW has stronger metric properties than Dynamic Time Warping (DTW) and is more robust to outliers than the Fr\'{e}chet distance, which are the two gold standards of dissimilarity measures for polygonal curves. We show interesting properties of $k$-DTW and give an exact algorithm as well as a $(1+\varepsilon)$-approximation algorithm for $k$-DTW by a parametric search for the $k$-th largest matched distance. We prove the first dimension-free learning bounds for curves and further learning theoretic results. $k$-DTW not only admits smaller sample size than DTW for the problem of learning the median of curves, where some factors depending on the curves' complexity $m$ are replaced by $k$, but we also show a surprising separation on the associated Rademacher and Gaussian complexities: $k$-DTW admits strictly smaller bounds than DTW, by a factor $\tilde\Omega(\sqrt{m})$ when $k\ll m$. We complement our theoretical findings with an experimental illustration of the benefits of using $k$-DTW for clustering and nearest neighbor classification.
Cutting Through Privacy: A Hyperplane-Based Data Reconstruction Attack in Federated Learning
May 15, 2025



Federated Learning (FL) enables collaborative training of machine learning models across distributed clients without sharing raw data, ostensibly preserving data privacy. Nevertheless, recent studies have revealed critical vulnerabilities in FL, showing that a malicious central server can manipulate model updates to reconstruct clients' private training data. Existing data reconstruction attacks have important limitations: they often rely on assumptions about the clients' data distribution or their efficiency significantly degrades when batch sizes exceed just a few tens of samples. In this work, we introduce a novel data reconstruction attack that overcomes these limitations. Our method leverages a new geometric perspective on fully connected layers to craft malicious model parameters, enabling the perfect recovery of arbitrarily large data batches in classification tasks without any prior knowledge of clients' data. Through extensive experiments on both image and tabular datasets, we demonstrate that our attack outperforms existing methods and achieves perfect reconstruction of data batches two orders of magnitude larger than the state of the art.
(k, l)-Medians Clustering of Trajectories Using Continuous Dynamic Time Warping
Dec 01, 2020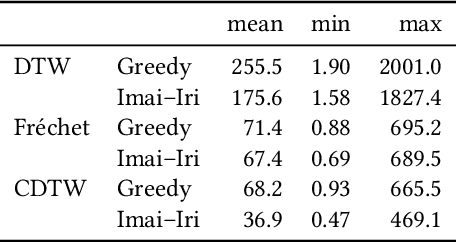
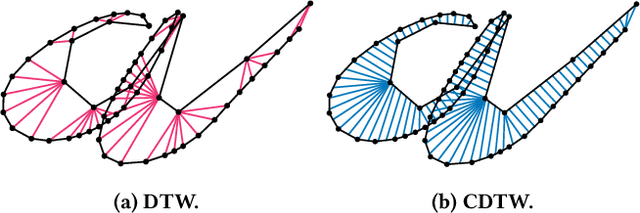
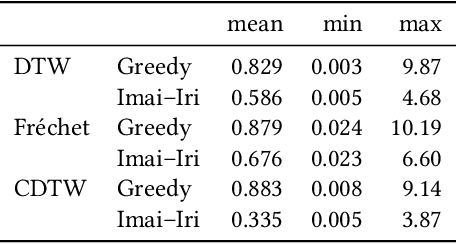
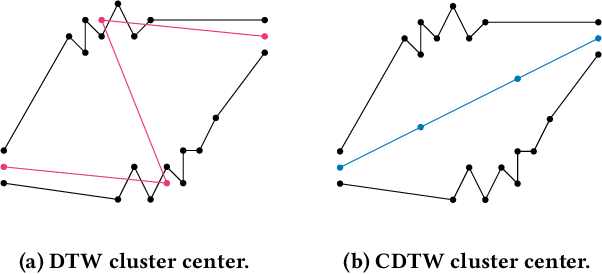
Due to the massively increasing amount of available geospatial data and the need to present it in an understandable way, clustering this data is more important than ever. As clusters might contain a large number of objects, having a representative for each cluster significantly facilitates understanding a clustering. Clustering methods relying on such representatives are called center-based. In this work we consider the problem of center-based clustering of trajectories. In this setting, the representative of a cluster is again a trajectory. To obtain a compact representation of the clusters and to avoid overfitting, we restrict the complexity of the representative trajectories by a parameter l. This restriction, however, makes discrete distance measures like dynamic time warping (DTW) less suited. There is recent work on center-based clustering of trajectories with a continuous distance measure, namely, the Fr\'echet distance. While the Fr\'echet distance allows for restriction of the center complexity, it can also be sensitive to outliers, whereas averaging-type distance measures, like DTW, are less so. To obtain a trajectory clustering algorithm that allows restricting center complexity and is more robust to outliers, we propose the usage of a continuous version of DTW as distance measure, which we call continuous dynamic time warping (CDTW). Our contribution is twofold: 1. To combat the lack of practical algorithms for CDTW, we develop an approximation algorithm that computes it. 2. We develop the first clustering algorithm under this distance measure and show a practical way to compute a center from a set of trajectories and subsequently iteratively improve it. To obtain insights into the results of clustering under CDTW on practical data, we conduct extensive experiments.