 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Controlled to the Wild: Evaluation of Pentesting Agents for the Real-World
May 11, 2026AI pentesting agents are increasingly credible as offensive security systems, but current benchmarks still provide limited guidance on which will perform best in real-world targets. Existing evaluation protocols assess and optimize for predefined goals such as capture-the-flag, remote code execution, exploit reproduction, or trajectory similarity, in simplified or narrow settings. These tools are valuable for measuring bounded capabilities, yet they do not adequately capture the complexity, open-ended exploration, and strategic decision-making required in realistic pentesting. In this paper, we present a practical evaluation protocol that shifts assessment from task completion to validated vulnerability discovery, allowing evaluation in sufficiently complex targets spanning multiple attack surfaces and vulnerability classes. The protocol combines structured ground-truth with LLM-based semantic matching to identify vulnerabilities, bipartite resolution to score findings under realistic ambiguity, continuous ground-truth maintenance, repeated and cumulative evaluation of stochastic agents, efficiency metrics, and reduced-suite selection for sustainable experimentation. This protocol extends the state of the art by enabling a more realistic, operationally informative comparison of AI pentesting agents. To enable reproducibility, we also release expert-annotated ground truth and code for the proposed evaluation protocol: https://github.com/jd0965199-oss/ethibench.
Pastprop-RNN: improved predictions of the future by correcting the past
Jun 25, 2021
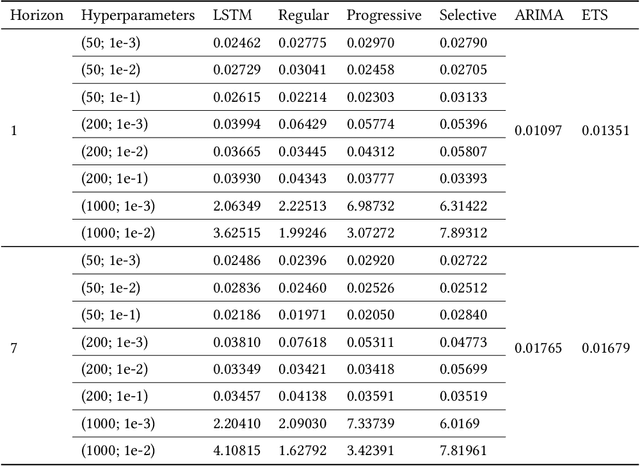
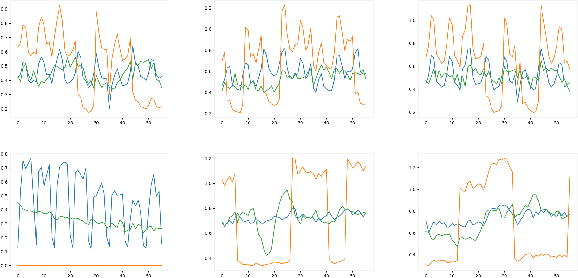
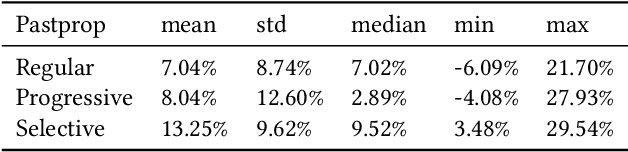
Forecasting accuracy is reliant on the quality of available past data. Data disruptions can adversely affect the quality of the generated model (e.g. unexpected events such as out-of-stock products when forecasting demand). We address this problem by pastcasting: predicting how data should have been in the past to explain the future better. We propose Pastprop-LSTM, a data-centric backpropagation algorithm that assigns part of the responsibility for errors to the training data and changes it accordingly. We test three variants of Pastprop-LSTM on forecasting competition datasets, M4 and M5, plus the Numenta Anomaly Benchmark. Empirical evaluation indicates that the proposed method can improve forecasting accuracy, especially when the prediction errors of standard LSTM are high. It also demonstrates the potential of the algorithm on datasets containing anomalies.