 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-LoRA: Auto Component LoRA for Personalized Artistic Style Image Generation
Apr 03, 2025Personalized image generation allows users to preserve styles or subjects of a provided small set of images for further image generation. With the advancement in large text-to-image models, many techniques have been developed to efficiently fine-tune those models for personalization, such as Low Rank Adaptation (LoRA). However, LoRA-based methods often face the challenge of adjusting the rank parameter to achieve satisfactory results. To address this challenge, AutoComponent-LoRA (AC-LoRA) is proposed, which is able to automatically separate the signal component and noise component of the LoRA matrices for fast and efficient personalized artistic style image generation. This method is based on Singular Value Decomposition (SVD) and dynamic heuristics to update the hyperparameters during training. Superior performance over existing methods in overcoming model underfitting or overfitting problems is demonstrated. The results were validated using FID, CLIP, DINO, and ImageReward, achieving an average of 9% improvement.
* 11 pages, 4 figures, ICCGV 2025, SPIE
Policy Diversity for Cooperative Agents
Aug 28, 2023



Standard cooperative multi-agent reinforcement learning (MARL) methods aim to find the optimal team cooperative policy to complete a task. However there may exist multiple different ways of cooperating, which usually are very needed by domain experts. Therefore, identifying a set of significantly different policies can alleviate the task complexity for them. Unfortunately, there is a general lack of effective policy diversity approaches specifically designed for the multi-agent domain. In this work, we propose a method called Moment-Matching Policy Diversity to alleviate this problem. This method can generate different team policies to varying degrees by formalizing the difference between team policies as the difference in actions of selected agents in different policies. Theoretically, we show that our method is a simple way to implement a constrained optimization problem that regularizes the difference between two trajectory distributions by using the maximum mean discrepancy. The effectiveness of our approach is demonstrated on a challenging team-based shooter.
Regularized Contrastive Learning of Semantic Search
Sep 27, 2022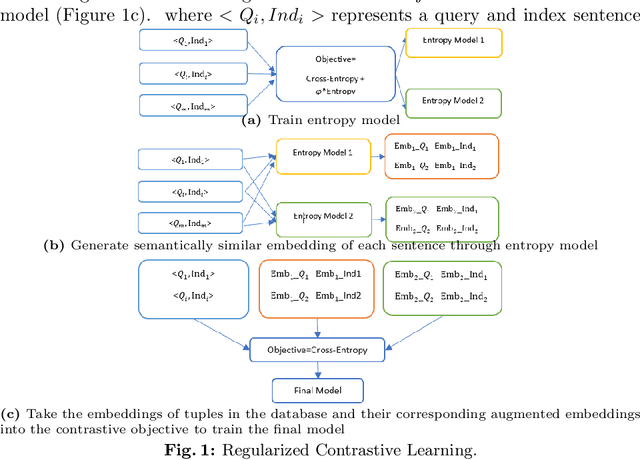
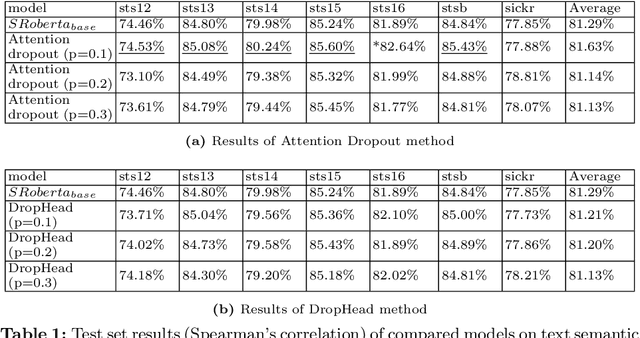
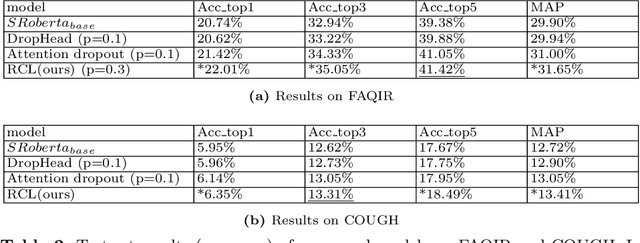
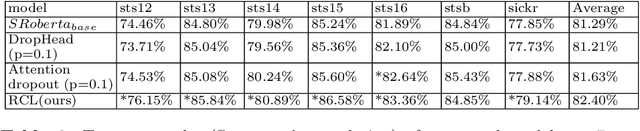
Semantic search is an important task which objective is to find the relevant index from a database for query. It requires a retrieval model that can properly learn the semantics of sentences. Transformer-based models are widely used as retrieval models due to their excellent ability to learn semantic representations. in the meantime, many regularization methods suitable for them have also been proposed. In this paper, we propose a new regularization method: Regularized Contrastive Learning, which can help transformer-based models to learn a better representation of sentences. It firstly augments several different semantic representations for every sentence, then take them into the contrastive objective as regulators. These contrastive regulators can overcome overfitting issues and alleviate the anisotropic problem. We firstly evaluate our approach on 7 semantic search benchmarks with the outperforming pre-trained model SRoBERTA. The results show that our method is more effective for learning a superior sentence representation. Then we evaluate our approach on 2 challenging FAQ datasets, Cough and Faqir, which have long query and index. The results of our experiments demonstrate that our method outperforms baseline methods.
Regularized Soft Actor-Critic for Behavior Transfer Learning
Sep 27, 2022
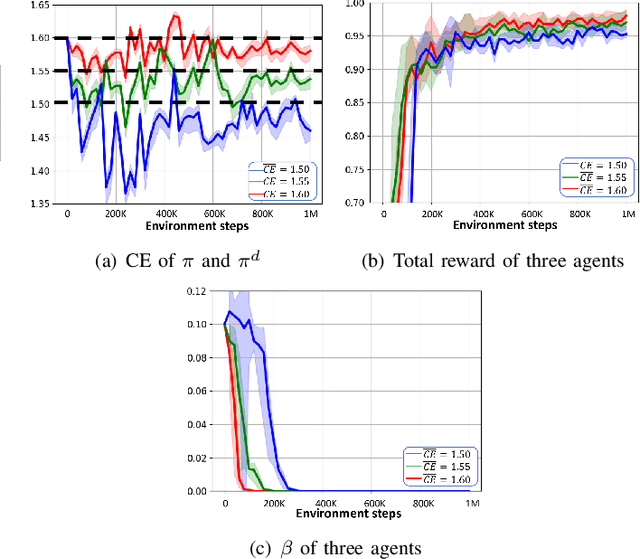
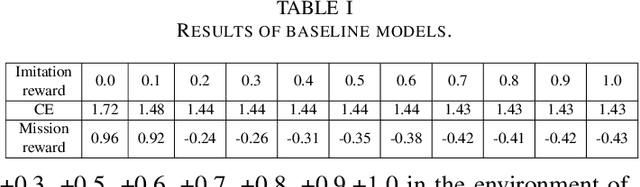
Existing imitation learning methods mainly focus on making an agent effectively mimic a demonstrated behavior, but do not address the potential contradiction between the behavior style and the objective of a task. There is a general lack of efficient methods that allow an agent to partially imitate a demonstrated behavior to varying degrees, while completing the main objective of a task. In this paper we propose a method called Regularized Soft Actor-Critic which formulates the main task and the imitation task under the Constrained Markov Decision Process framework (CMDP). The main task is defined as the maximum entropy objective used in Soft Actor-Critic (SAC) and the imitation task is defined as a constraint. We evaluate our method on continuous control tasks relevant to video games applications.