 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Meta-Features with Knowledge Graph Embeddings for Meta-Learning
Mar 20, 2026The vast collection of machine learning records available on the web presents a significant opportunity for meta-learning, where past experiments are leveraged to improve performance. Two crucial meta-learning tasks are pipeline performance estimation (PPE), which predicts pipeline performance on target datasets, and dataset performance-based similarity estimation (DPSE), which identifies datasets with similar performance patterns. Existing approaches primarily rely on dataset meta-features (e.g., number of instances, class entropy, etc.) to represent datasets numerically and approximate these meta-learning tasks. However, these approaches often overlook the wealth of past experimental results and pipeline metadata available. This limits their ability to capture dataset - pipeline interactions that reveal performance similarity patterns. In this work, we propose KGmetaSP, a knowledge-graph-embeddings approach that leverages existing experiment data to capture these interactions and improve both PPE and DPSE. We represent datasets and pipelines within a unified knowledge graph (KG) and derive embeddings that support pipeline-agnostic meta-models for PPE and distance-based retrieval for DPSE. To validate our approach, we construct a large-scale benchmark comprising 144,177 OpenML experiments, enabling a rich cross-dataset evaluation. KGmetaSP enables accurate PPE using a single pipeline-agnostic meta-model and improves DPSE over baselines. The proposed KGmetaSP, KG, and benchmark are released, establishing a new reference point for meta-learning and demonstrating how consolidating open experiment data into a unified KG advances the field.
Shape Fragments
Dec 22, 2021
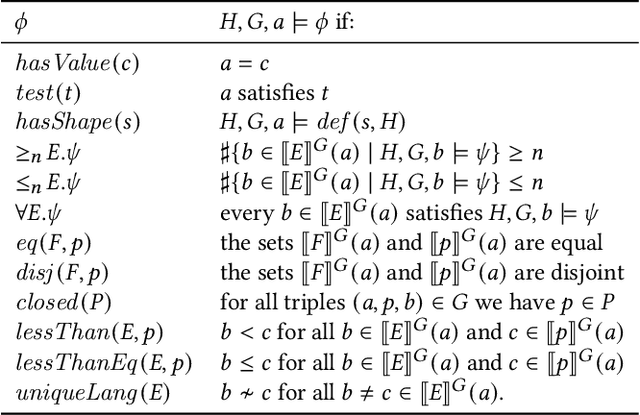

In constraint languages for RDF graphs, such as ShEx and SHACL, constraints on nodes and their properties in RDF graphs are known as "shapes". Schemas in these languages list the various shapes that certain targeted nodes must satisfy for the graph to conform to the schema. Using SHACL, we propose in this paper a novel use of shapes, by which a set of shapes is used to extract a subgraph from an RDF graph, the so-called shape fragment. Our proposed mechanism fits in the framework of Linked Data Fragments. In this paper, (i) we define our extraction mechanism formally, building on recently proposed SHACL formalizations; (ii) we establish correctness properties, which relate shape fragments to notions of provenance for database queries; (iii) we compare shape fragments with SPARQL queries; (iv) we discuss implementation options; and (v) we present initial experiments demonstrating that shape fragments are a feasible new idea.
R2RML and RML Comparison for RDF Generation, their Rules Validation and Inconsistency Resolution
May 13, 2020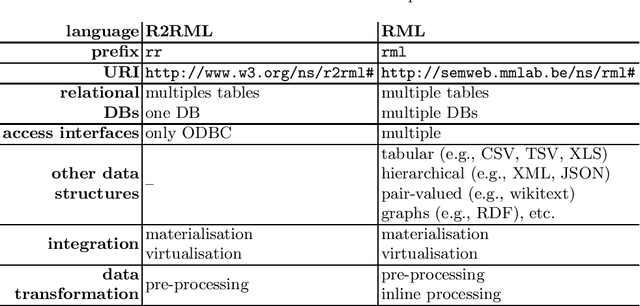
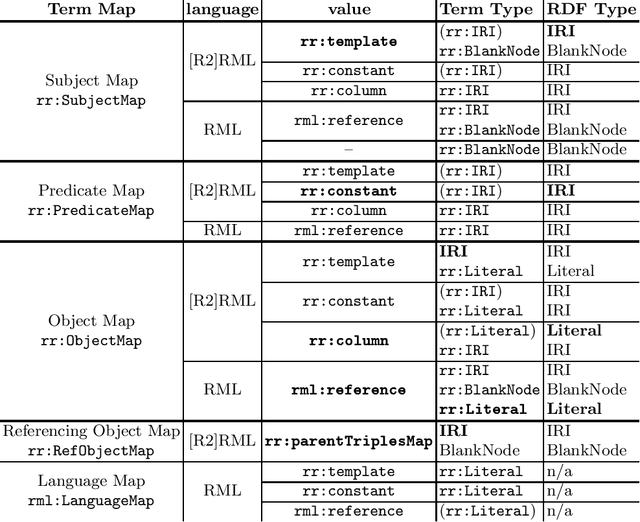
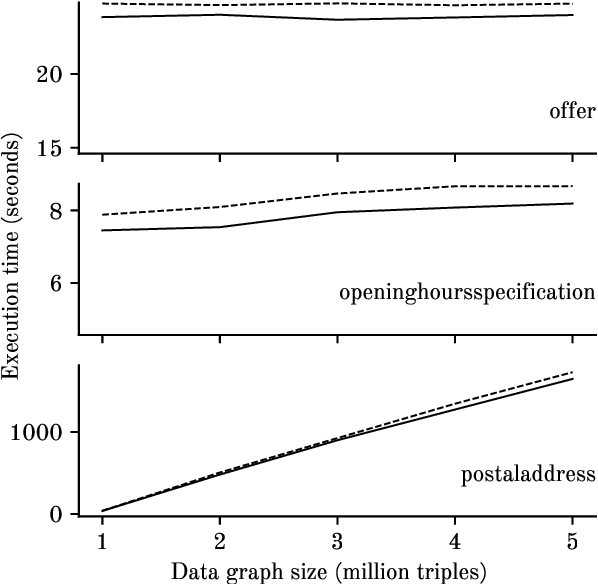
In this paper, an overview of the state of the art on knowledge graph generation is provided, with focus on the two prevalent mapping languages: the W3C recommended R2RML and its generalisation RML. We look into details on their differences and explain how knowledge graphs, in the form of RDF graphs, can be generated with each one of the two mapping languages. Then we assess if the vocabulary terms were properly applied to the data and no violations occurred on their use, either using R2RML or RML to generate the desired knowledge graph.