 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrad Detect: Gradient-Based Hallucination Detection in LLMs
Jun 23, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks, yet they remain prone to generating hallucinations. Detecting these hallucinations is critical for deploying LLMs reliably in high-stakes applications. We present Grad Detect, a gradient-based approach for predicting hallucinations by analyzing layer-wise gradient patterns from a single forward-backward pass during inference. Our method shows that the internal gradient structure of a model carries rich information about the correctness of its output. This information is not accessible through output-level signals alone. We evaluate Grad Detect on several Q&A benchmarks across both hallucination detection and model abstention prediction, where it consistently outperforms confidence-based and sampling-based baselines. Through comprehensive layer ablation studies across all eleven models from four architectural families, we find that the final five layers concentrate over 97% of the discriminative gradient signal, enabling efficient deployment with minimal performance loss. Grad Detect provides a unified framework for predicting multiple dimensions of LLM reliability, offering strong predictive performance alongside interpretable insights into where and how model failures originate.
* Accepted to the 2nd Workshop on Compositional Learning at ICML 2026, Seoul, South Korea. Copyright 2026 by the author(s)
Arcee: Differentiable Recurrent State Chain for Generative Vision Modeling with Mamba SSMs
Nov 17, 2025State-space models (SSMs), Mamba in particular, are increasingly adopted for long-context sequence modeling, providing linear-time aggregation via an input-dependent, causal selective-scan operation. Along this line, recent "Mamba-for-vision" variants largely explore multiple scan orders to relax strict causality for non-sequential signals (e.g., images). Rather than preserving cross-block memory, the conventional formulation of the selective-scan operation in Mamba reinitializes each block's state-space dynamics from zero, discarding the terminal state-space representation (SSR) from the previous block. Arcee, a cross-block recurrent state chain, reuses each block's terminal state-space representation as the initial condition for the next block. Handoff across blocks is constructed as a differentiable boundary map whose Jacobian enables end-to-end gradient flow across terminal boundaries. Key to practicality, Arcee is compatible with all prior "vision-mamba" variants, parameter-free, and incurs constant, negligible cost. As a modeling perspective, we view terminal SSR as a mild directional prior induced by a causal pass over the input, rather than an estimator of the non-sequential signal itself. To quantify the impact, for unconditional generation on CelebA-HQ (256$\times$256) with Flow Matching, Arcee reduces FID$\downarrow$ from $82.81$ to $15.33$ ($5.4\times$ lower) on a single scan-order Zigzag Mamba baseline. Efficient CUDA kernels and training code will be released to support rigorous and reproducible research.
Diversity-Enriched Option-Critic
Nov 04, 2020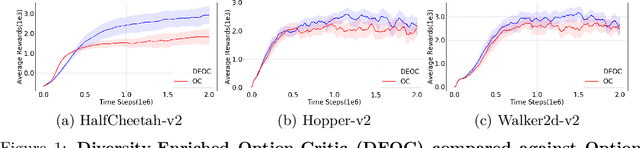

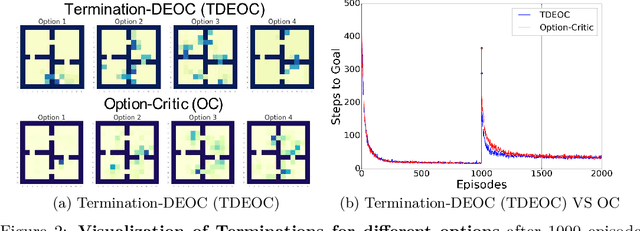

Temporal abstraction allows reinforcement learning agents to represent knowledge and develop strategies over different temporal scales. The option-critic framework has been demonstrated to learn temporally extended actions, represented as options, end-to-end in a model-free setting. However, feasibility of option-critic remains limited due to two major challenges, multiple options adopting very similar behavior, or a shrinking set of task relevant options. These occurrences not only void the need for temporal abstraction, they also affect performance. In this paper, we tackle these problems by learning a diverse set of options. We introduce an information-theoretic intrinsic reward, which augments the task reward, as well as a novel termination objective, in order to encourage behavioral diversity in the option set. We show empirically that our proposed method is capable of learning options end-to-end on several discrete and continuous control tasks, outperforms option-critic by a wide margin. Furthermore, we show that our approach sustainably generates robust, reusable, reliable and interpretable options, in contrast to option-critic.