 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verifiable Federated Unlearning: Framework, Challenges, and The Road Ahead
Oct 01, 2025Federated unlearning (FUL) enables removing the data influence from the model trained across distributed clients, upholding the right to be forgotten as mandated by privacy regulations. FUL facilitates a value exchange where clients gain privacy-preserving control over their data contributions, while service providers leverage decentralized computing and data freshness. However, this entire proposition is undermined because clients have no reliable way to verify that their data influence has been provably removed, as current metrics and simple notifications offer insufficient assurance. We envision unlearning verification becoming a pivotal and trust-by-design part of the FUL life-cycle development, essential for highly regulated and data-sensitive services and applications like healthcare. This article introduces veriFUL, a reference framework for verifiable FUL that formalizes verification entities, goals, approaches, and metrics. Specifically, we consolidate existing efforts and contribute new insights, concepts, and metrics to this domain. Finally, we highlight research challenges and identify potential applications and developments for verifiable FUL and veriFUL.
XCycles Backprojection Acoustic Super-Resolution
May 19, 2021
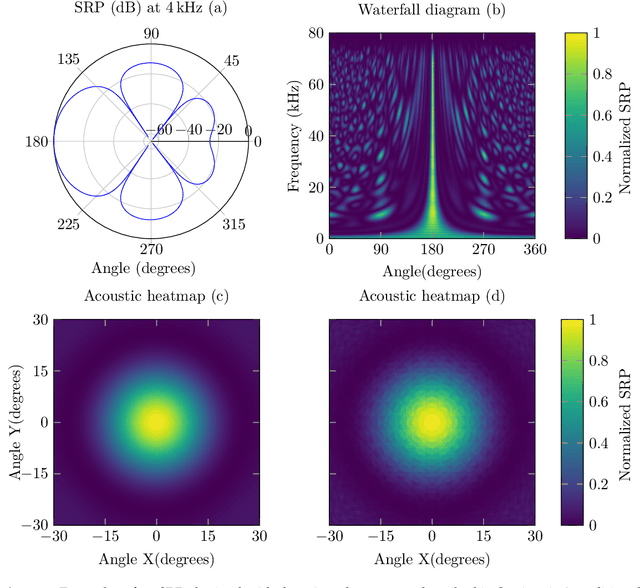
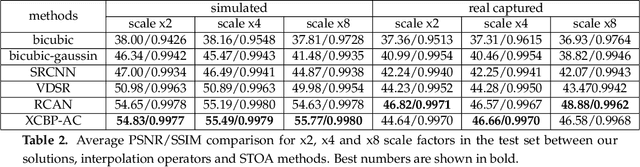
The computer vision community has paid much attention to the development of visible image super-resolution (SR) using deep neural networks (DNNs) and has achieved impressive results. The advancement of non-visible light sensors, such as acoustic imaging sensors, has attracted much attention, as they allow people to visualize the intensity of sound waves beyond the visible spectrum. However, because of the limitations imposed on acquiring acoustic data, new methods for improving the resolution of the acoustic images are necessary. At this time, there is no acoustic imaging dataset designed for the SR problem. This work proposed a novel backprojection model architecture for the acoustic image super-resolution problem, together with Acoustic Map Imaging VUB-ULB Dataset (AMIVU). The dataset provides large simulated and real captured images at different resolutions. The proposed XCycles BackProjection model (XCBP), in contrast to the feedforward model approach, fully uses the iterative correction procedure in each cycle to reconstruct the residual error correction for the encoded features in both low- and high-resolution space. The proposed approach was evaluated on the dataset and showed high outperformance compared to the classical interpolation operators and to the recent feedforward state-of-the-art models. It also contributed to a drastically reduced sub-sampling error produced during the data acquisition.