 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Quantifiable Visual Explanations Without Ground-Truth
May 18, 2026Explainable AI (XAI) techniques are increasingly important for the validation and responsible use of modern deep learning models, but are difficult to evaluate due to the lack of good ground-truth to compare against. We propose a framework that serves as a quantifiable metric for the quality of XAI methods, based on continuous input perturbation. Our metric formally considers the sufficiency and necessity of the attributed information to the model's decision-making, and we illustrate a range of cases where it aligns better with human intuitions of explanation quality than do existing metrics. To exploit the properties of this metric, we also propose a novel XAI method, considering the case where we fine-tune a model using a differentiable approximation of the metric as a supervision signal. The result is an adapter module that can be trained on top of any black-box model to output causal explanations of the model's decision process, without degrading model performance. We show that the explanations generated by this method outperform those of competing XAI techniques according to a number of quantifiable metrics.
How Much Power Must We Extract From a Receiver Antenna to Effect Communications?
Oct 09, 2024



Subject to the laws of classical physics - the science that governs the design of today's wireless communication systems - there is no need to extract power from a receiver antenna in order to effect communications. If we dispense with a transmission line and, instead, make the front-end electronics colocated with the antenna, then a high input-impedance preamplifier can measure the open-circuit voltage directly on the antenna port without drawing either current or power. Neither Friis' concept of noise figure, nor Shannon information theory, nor electronics technology dictates that we must extract power from an antenna.
VisioPhysioENet: Multimodal Engagement Detection using Visual and Physiological Signals
Sep 24, 2024



This paper presents VisioPhysioENet, a novel multimodal system that leverages visual cues and physiological signals to detect learner engagement. It employs a two-level approach for visual feature extraction using the Dlib library for facial landmark extraction and the OpenCV library for further estimations. This is complemented by extracting physiological signals using the plane-orthogonal-to-skin method to assess cardiovascular activity. These features are integrated using advanced machine learning classifiers, enhancing the detection of various engagement levels. We rigorously evaluate VisioPhysioENet on the DAiSEE dataset, where it achieves an accuracy of 63.09%, demonstrating a superior ability to discern various levels of engagement compared to existing methodologies. The proposed system's code can be accessed at https://github.com/MIntelligence-Group/VisioPhysioENet.
GraphPrint: Extracting Features from 3D Protein Structure for Drug Target Affinity Prediction
Jul 15, 2024



Accurate drug target affinity prediction can improve drug candidate selection, accelerate the drug discovery process, and reduce drug production costs. Previous work focused on traditional fingerprints or used features extracted based on the amino acid sequence in the protein, ignoring its 3D structure which affects its binding affinity. In this work, we propose GraphPrint: a framework for incorporating 3D protein structure features for drug target affinity prediction. We generate graph representations for protein 3D structures using amino acid residue location coordinates and combine them with drug graph representation and traditional features to jointly learn drug target affinity. Our model achieves a mean square error of 0.1378 and a concordance index of 0.8929 on the KIBA dataset and improves over using traditional protein features alone. Our ablation study shows that the 3D protein structure-based features provide information complementary to traditional features.
Shannon Theory for Wireless Communication in a Resonant Chamber
Nov 15, 2023A closed electromagnetic resonant chamber (RC) is a highly favorable artificial environment for wireless communication. A pair of antennas within the chamber constitutes a two-port network described by an impedance matrix. We analyze communication between the two antennas when the RC has perfectly conducting walls and the impedance matrix is imaginary-valued. The transmit antenna is driven by a current source, and the receive antenna is connected to a load resistor whose voltage is measured by an infinite-impedance amplifier. There are a countably infinite number of poles in the channel, associated with resonance in the RC, which migrate towards the real frequency axis as the load resistance increases. There are two sources of receiver noise: the Johnson noise of the load resistor, and the internal amplifier noise. An application of Shannon theory yields the capacity of the link, subject to bandwidth and power constraints on the transmit current. For a constant transmit power, capacity increases without bound as the load resistance increases. Surprisingly, the capacity-attaining allocation of transmit power versus frequency avoids placing power close to the resonant frequencies.
Class-Incremental Continual Learning for General Purpose Healthcare Models
Nov 07, 2023Healthcare clinics regularly encounter dynamic data that changes due to variations in patient populations, treatment policies, medical devices, and emerging disease patterns. Deep learning models can suffer from catastrophic forgetting when fine-tuned in such scenarios, causing poor performance on previously learned tasks. Continual learning allows learning on new tasks without performance drop on previous tasks. In this work, we investigate the performance of continual learning models on four different medical imaging scenarios involving ten classification datasets from diverse modalities, clinical specialties, and hospitals. We implement various continual learning approaches and evaluate their performance in these scenarios. Our results demonstrate that a single model can sequentially learn new tasks from different specialties and achieve comparable performance to naive methods. These findings indicate the feasibility of recycling or sharing models across the same or different medical specialties, offering another step towards the development of general-purpose medical imaging AI that can be shared across institutions.
Autonomous Soft Tissue Retraction Using Demonstration-Guided Reinforcement Learning
Sep 02, 2023In the context of surgery, robots can provide substantial assistance by performing small, repetitive tasks such as suturing, needle exchange, and tissue retraction, thereby enabling surgeons to concentrate on more complex aspects of the procedure. However, existing surgical task learning mainly pertains to rigid body interactions, whereas the advancement towards more sophisticated surgical robots necessitates the manipulation of soft bodies. Previous work focused on tissue phantoms for soft tissue task learning, which can be expensive and can be an entry barrier to research. Simulation environments present a safe and efficient way to learn surgical tasks before their application to actual tissue. In this study, we create a Robot Operating System (ROS)-compatible physics simulation environment with support for both rigid and soft body interactions within surgical tasks. Furthermore, we investigate the soft tissue interactions facilitated by the patient-side manipulator of the DaVinci surgical robot. Leveraging the pybullet physics engine, we simulate kinematics and establish anchor points to guide the robotic arm when manipulating soft tissue. Using demonstration-guided reinforcement learning (RL) algorithms, we investigate their performance in comparison to traditional reinforcement learning algorithms. Our in silico trials demonstrate a proof-of-concept for autonomous surgical soft tissue retraction. The results corroborate the feasibility of learning soft body manipulation through the application of reinforcement learning agents. This work lays the foundation for future research into the development and refinement of surgical robots capable of managing both rigid and soft tissue interactions. Code is available at https://github.com/amritpal-001/tissue_retract.
An Application of Deep Learning for Sweet Cherry Phenotyping using YOLO Object Detection
Feb 13, 2023Tree fruit breeding is a long-term activity involving repeated measurements of various fruit quality traits on a large number of samples. These traits are traditionally measured by manually counting the fruits, weighing to indirectly measure the fruit size, and fruit colour is classified subjectively into different color categories using visual comparison to colour charts. These processes are slow, expensive and subject to evaluators' bias and fatigue. Recent advancements in deep learning can help automate this process. A method was developed to automatically count the number of sweet cherry fruits in a camera's field of view in real time using YOLOv3. A system capable of analyzing the image data for other traits such as size and color was also developed using Python. The YOLO model obtained close to 99% accuracy in object detection and counting of cherries and 90% on the Intersection over Union metric for object localization when extracting size and colour information. The model surpasses human performance and offers a significant improvement compared to manual counting.
A Text to Speech System with English to Punjabi Conversion
Nov 13, 2014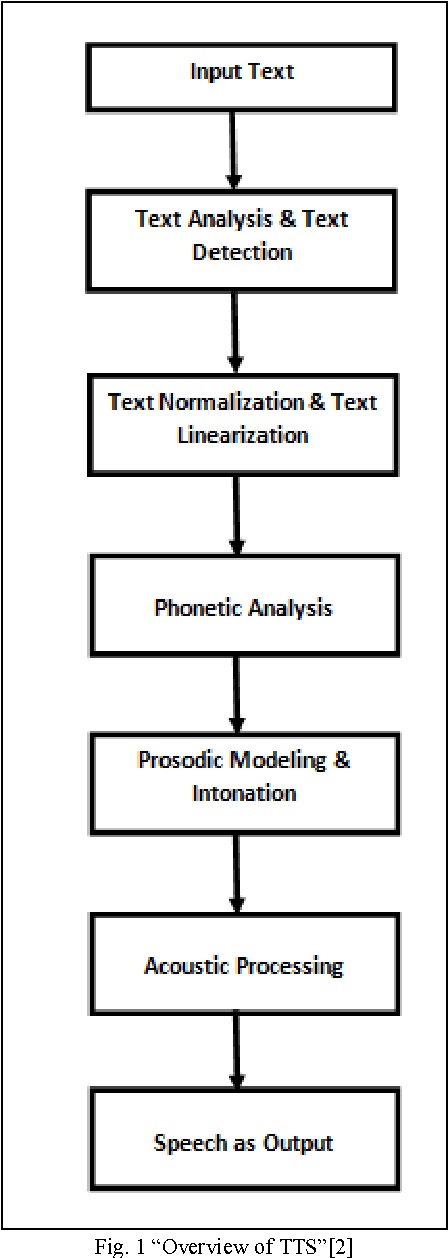

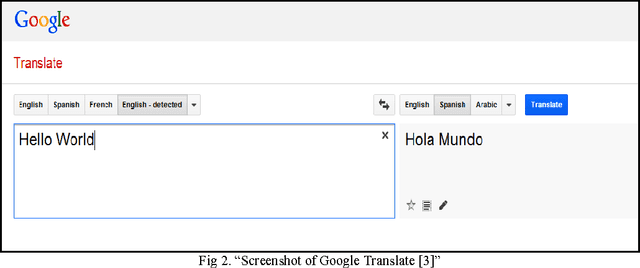
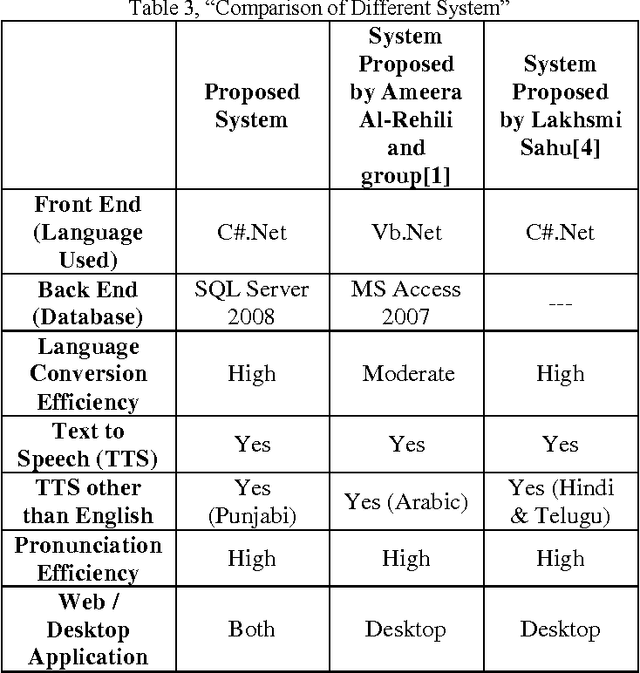
The paper aims to show how an application can be developed that converts the English language into the Punjabi Language, and the same application can convert the Text to Speech(TTS) i.e. pronounce the text. This application can be really beneficial for those with special needs.
* 5 pages, 8 figures, 3 tables