 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022

Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022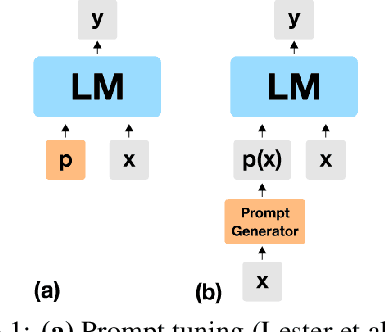
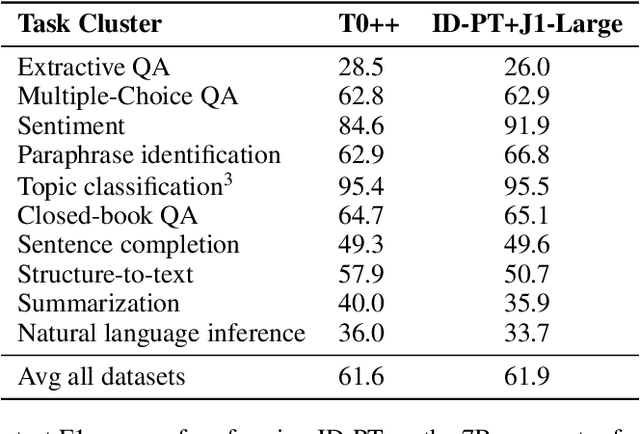
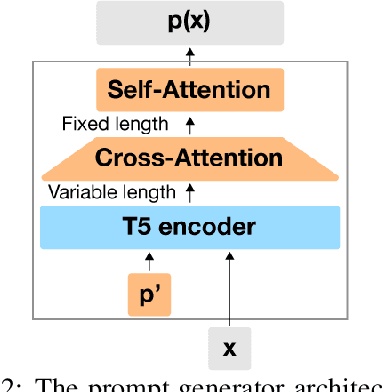

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
Sub-Task Decomposition Enables Learning in Sequence to Sequence Tasks
Apr 06, 2022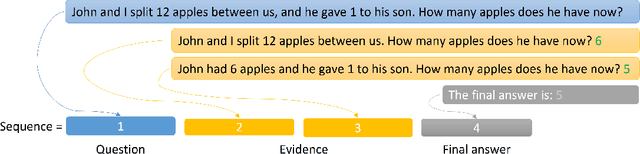
The field of Natural Language Processing (NLP) has experienced a dramatic leap in capabilities with the recent introduction of huge Language Models (LMs). Despite this success, natural language problems that involve several compounded steps are still practically unlearnable, even by the largest LMs. This complies with experimental failures for end-to-end learning of composite problems that were demonstrated in a variety of domains. A known mitigation is to introduce intermediate supervision for solving sub-tasks of the compounded problem. Recently, several works have demonstrated high gains by taking a straightforward approach for incorporating intermediate supervision in compounded natural language problems: the sequence-to-sequence LM is fed with an augmented input, in which the decomposed tasks' labels are simply concatenated to the original input. In this paper, we prove a positive learning result that motivates these recent efforts. We show that when concatenating intermediate supervision to the input and training a sequence-to-sequence model on this modified input, an unlearnable composite problem becomes learnable. We prove this for the notoriously unlearnable composite task of bit-subset parity, with the intermediate supervision being parity results of increasingly large bit-subsets. Beyond motivating contemporary empirical efforts for incorporating intermediate supervision in sequence-to-sequence language models, our positive theoretical result is the first of its kind in the landscape of results on the benefits of intermediate supervision: Until now, all theoretical results on the subject are negative, i.e., show cases where learning is impossible without intermediate supervision, while our result is positive, showing a case where learning is facilitated in the presence of intermediate supervision.
The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design
Oct 25, 2021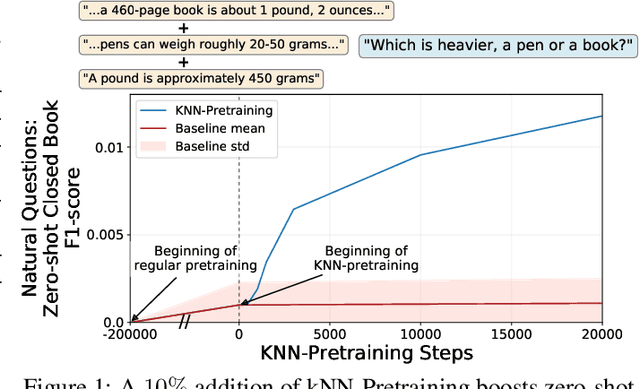

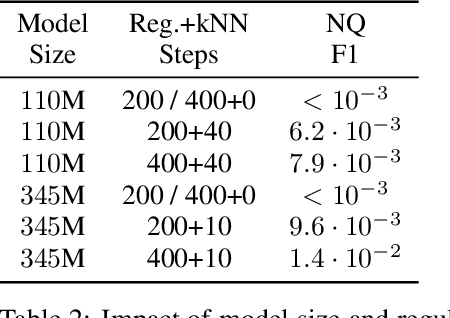
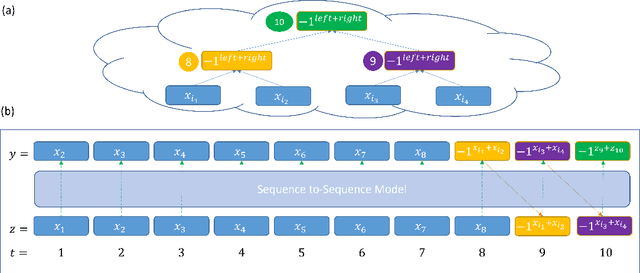
Pretraining Neural Language Models (NLMs) over a large corpus involves chunking the text into training examples, which are contiguous text segments of sizes processable by the neural architecture. We highlight a bias introduced by this common practice: we prove that the pretrained NLM can model much stronger dependencies between text segments that appeared in the same training example, than it can between text segments that appeared in different training examples. This intuitive result has a twofold role. First, it formalizes the motivation behind a broad line of recent successful NLM training heuristics, proposed for the pretraining and fine-tuning stages, which do not necessarily appear related at first glance. Second, our result clearly indicates further improvements to be made in NLM pretraining for the benefit of Natural Language Understanding tasks. As an example, we propose "kNN-Pretraining": we show that including semantically related non-neighboring sentences in the same pretraining example yields improved sentence representations and open domain question answering abilities. This theoretically motivated degree of freedom for "pretraining example design" indicates new training schemes for self-improving representations.
Which transformer architecture fits my data? A vocabulary bottleneck in self-attention
May 09, 2021



After their successful debut in natural language processing, Transformer architectures are now becoming the de-facto standard in many domains. An obstacle for their deployment over new modalities is the architectural configuration: the optimal depth-to-width ratio has been shown to dramatically vary across data types (e.g., $10$x larger over images than over language). We theoretically predict the existence of an embedding rank bottleneck that limits the contribution of self-attention width to the Transformer expressivity. We thus directly tie the input vocabulary size and rank to the optimal depth-to-width ratio, since a small vocabulary size or rank dictates an added advantage of depth over width. We empirically demonstrate the existence of this bottleneck and its implications on the depth-to-width interplay of Transformer architectures, linking the architecture variability across domains to the often glossed-over usage of different vocabulary sizes or embedding ranks in different domains. As an additional benefit, our rank bottlenecking framework allows us to identify size redundancies of $25\%-50\%$ in leading NLP models such as ALBERT and T5.
Neural tensor contractions and the expressive power of deep neural quantum states
Mar 18, 2021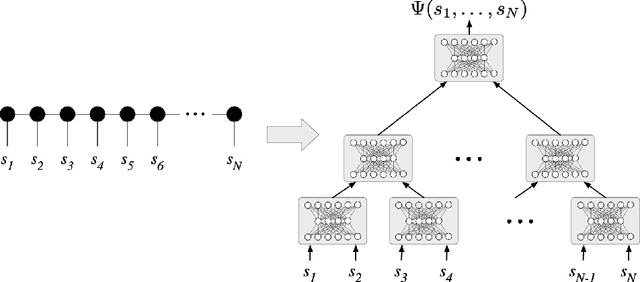


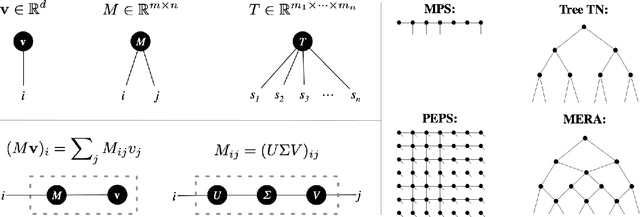
We establish a direct connection between general tensor networks and deep feed-forward artificial neural networks. The core of our results is the construction of neural-network layers that efficiently perform tensor contractions, and that use commonly adopted non-linear activation functions. The resulting deep networks feature a number of edges that closely matches the contraction complexity of the tensor networks to be approximated. In the context of many-body quantum states, this result establishes that neural-network states have strictly the same or higher expressive power than practically usable variational tensor networks. As an example, we show that all matrix product states can be efficiently written as neural-network states with a number of edges polynomial in the bond dimension and depth logarithmic in the system size. The opposite instead does not hold true, and our results imply that there exist quantum states that are not efficiently expressible in terms of matrix product states or practically usable PEPS, but that are instead efficiently expressible with neural network states.
Limits to Depth Efficiencies of Self-Attention
Jun 22, 2020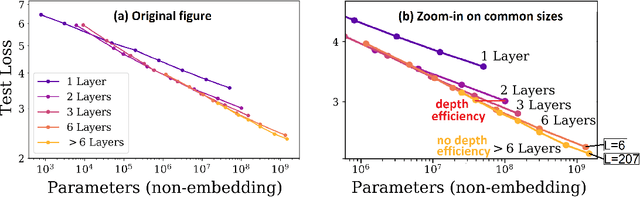
Self-attention architectures, which are rapidly pushing the frontier in natural language processing, demonstrate a surprising depth-inefficient behavior: Empirical signals indicate that increasing the internal representation (network width) is just as useful as increasing the number of self-attention layers (network depth). In this paper, we theoretically study the interplay between depth and width in self-attention, and shed light on the root of the above phenomenon. We invalidate the seemingly plausible hypothesis by which widening is as effective as deepening for self-attention, and show that in fact stacking self-attention layers is so effective that it quickly saturates a capacity of the network width. Specifically, we pinpoint a "depth threshold" that is logarithmic in $d_x$, the network width: $L_{\textrm{th}}=\log_{3}(d_x)$. For networks of depth that is below the threshold, we establish a double-exponential depth-efficiency of the self-attention operation, while for depths over the threshold we show that depth-inefficiency kicks in. Our predictions strongly accord with extensive empirical ablations in Kaplan et al. (2020), accounting for the different behaviors in the two depth-(in)efficiency regimes. By identifying network width as a limiting factor, our analysis indicates that solutions for dramatically increasing the width can facilitate the next leap in self-attention expressivity.
On the Ethics of Building AI in a Responsible Manner
Mar 30, 2020The AI-alignment problem arises when there is a discrepancy between the goals that a human designer specifies to an AI learner and a potential catastrophic outcome that does not reflect what the human designer really wants. We argue that a formalism of AI alignment that does not distinguish between strategic and agnostic misalignments is not useful, as it deems all technology as un-safe. We propose a definition of a strategic-AI-alignment and prove that most machine learning algorithms that are being used in practice today do not suffer from the strategic-AI-alignment problem. However, without being careful, today's technology might lead to strategic misalignment.
SenseBERT: Driving Some Sense into BERT
Aug 15, 2019

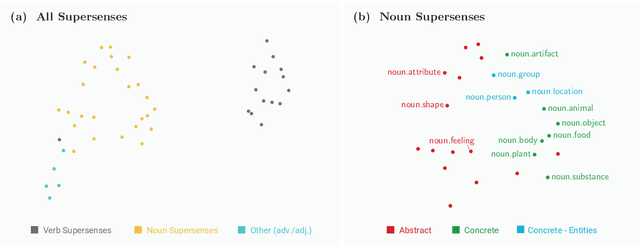
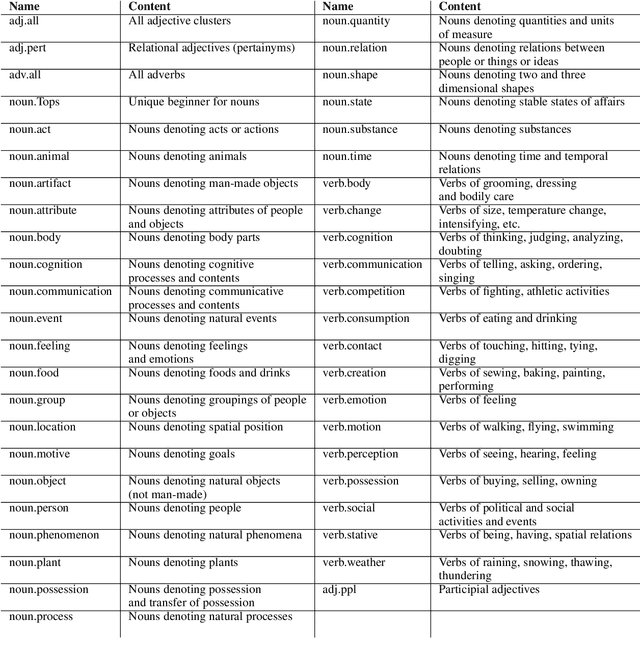
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.
Deep autoregressive models for the efficient variational simulation of many-body quantum systems
Feb 11, 2019

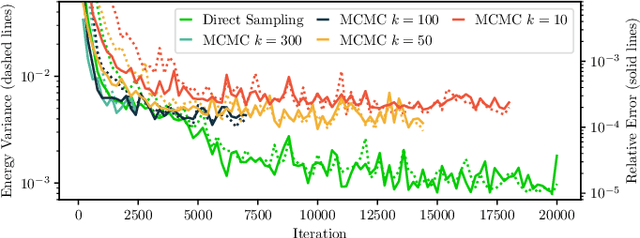
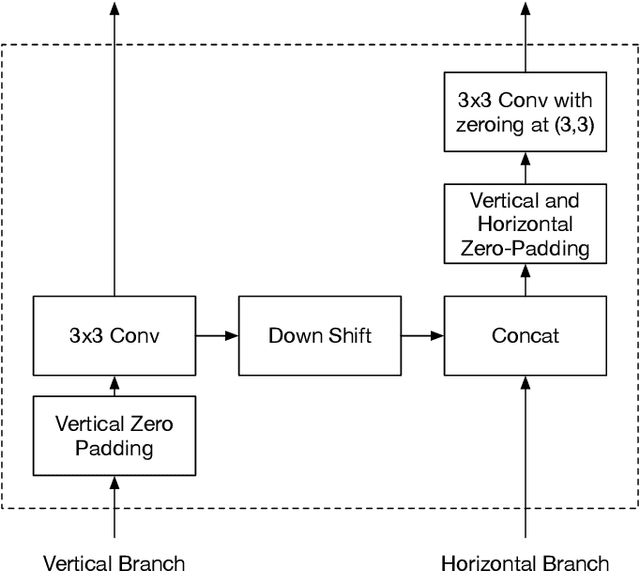
Artificial Neural Networks were recently shown to be an efficient representation of highly-entangled many-body quantum states. In practical applications, neural-network states inherit numerical schemes used in Variational Monte Carlo, most notably the use of Markov-Chain Monte-Carlo (MCMC) sampling to estimate quantum expectations. The local stochastic sampling in MCMC caps the potential advantages of neural networks in two ways: (i) Its intrinsic computational cost sets stringent practical limits on the width and depth of the networks, and therefore limits their expressive capacity; (ii) Its difficulty in generating precise and uncorrelated samples can result in estimations of observables that are very far from their true value. Inspired by the state-of-the-art generative models used in machine learning, we propose a specialized Neural Network architecture that supports efficient and exact sampling, completely circumventing the need for Markov Chain sampling. We demonstrate our approach for a two-dimensional interacting spin model, showcasing the ability to obtain accurate results on larger system sizes than those currently accessible to neural-network quantum states.