 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainability of SLMs by investigating Token Level Activation
May 21, 2026Transformer-based language models such as BERT having 110M+ parameters have revolutionized natural language understanding, yet their internal mechanisms remain largely opaque to researchers and practitioners. Traditional attention-based interpretability methods often emphasize structurally important but semantically weak tokens such as punctuation marks rather than meaningful semantic relationships. This work introduces a lightweight and model-agnostic framework for quantifying token-level representational importance using hidden-state activation strengths at Layer 8 of BERT. The proposed Activation Flow Network (AFN) framework computes Token Activation Strength using the L2 norm of Layer-8 hidden representations, enabling direct ranking of semantically salient tokens. The study further introduces a threshold-based activation bucket formulation that partitions tokens into HIGH-activation and LOW-activation groups using an empirical upper-quartile activation boundary. Experimental observations demonstrate that semantically meaningful content words consistently occupy the HIGH-activation bucket and dominate representational activation shifts, while structurally supportive tokens contribute comparatively less. The results suggest that Layer 8 acts as a critical semantic consolidation zone balancing structural and semantic information processing. By revealing how activation magnitudes concentrate around semantically informative tokens, this work provides an interpretable and computationally efficient alternative to attentioncentric analysis, contributing toward transforming BERT from a "black box" into a more transparent "glass box" model for natural language understanding.
A New Technique for AI Explainability using Feature Association Map
May 14, 2026Lack of transparency in AI systems poses challenges in critical real-life applications. It is important to be able to explain the decisions of an AI system to ensure trust on the system. Explainable AI (XAI) algorithms play a vital role in achieving this objective. In this paper, we are proposing a new algorithm for Explaining AI systems, FAMeX (Feature Association Map based eXplainability). The proposed algorithm is based on a graph-theoretic formulation of the feature set termed as Feature Association Map (FAM). The foundation of the modelling is based on association between features. The proposed FAMeX algorithm has been found to be better than the competing XAI algorithms - Permutation Feature Importance (PFI) and SHapley Additive exPlanations (SHAP). Experiments conducted with eight benchmark algorithms show that FAMeX is able to gauge feature importance in the context of classification better than the competing algorithms. This definitely shows that FAMeX is a promising algorithm in explaining the predictions from an AI system
Bangla hate speech detection on social media using attention-based recurrent neural network
Mar 31, 2022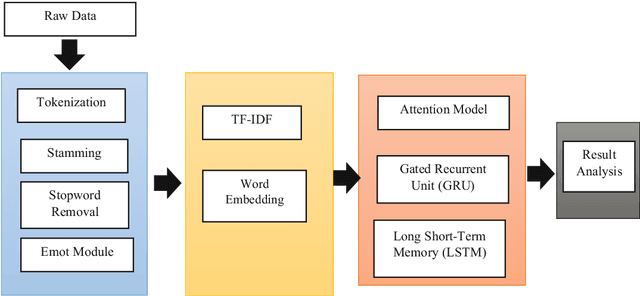

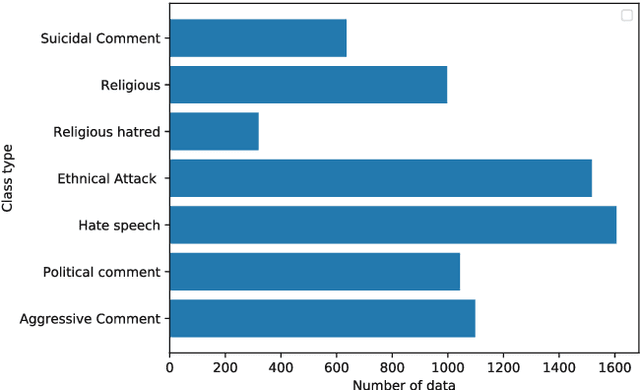

Hate speech has spread more rapidly through the daily use of technology and, most notably, by sharing your opinions or feelings on social media in a negative aspect. Although numerous works have been carried out in detecting hate speeches in English, German, and other languages, very few works have been carried out in the context of the Bengali language. In contrast, millions of people communicate on social media in Bengali. The few existing works that have been carried out need improvements in both accuracy and interpretability. This article proposed encoder decoder based machine learning model, a popular tool in NLP, to classify user's Bengali comments on Facebook pages. A dataset of 7,425 Bengali comments, consisting of seven distinct categories of hate speeches, was used to train and evaluate our model. For extracting and encoding local features from the comments, 1D convolutional layers were used. Finally, the attention mechanism, LSTM, and GRU based decoders have been used for predicting hate speech categories. Among the three encoder decoder algorithms, the attention-based decoder obtained the best accuracy (77%).