 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocRipple: A Two-Stage Framework for Cold-Start Video Recommendations
Aug 10, 2025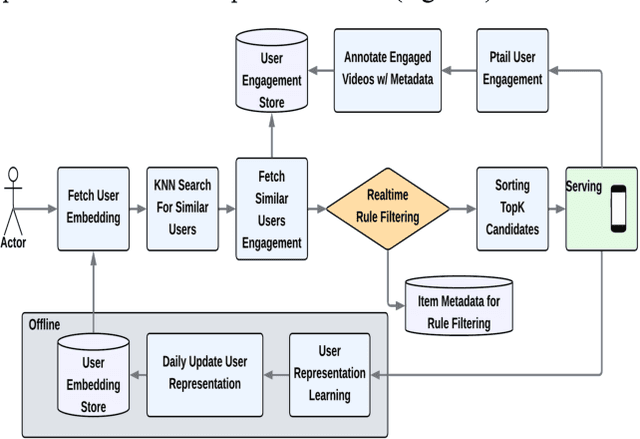
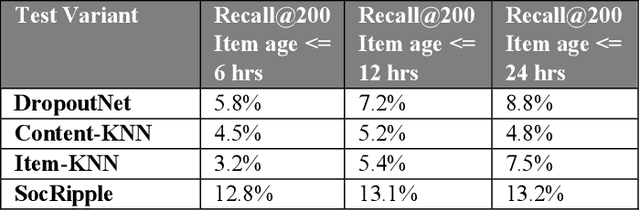
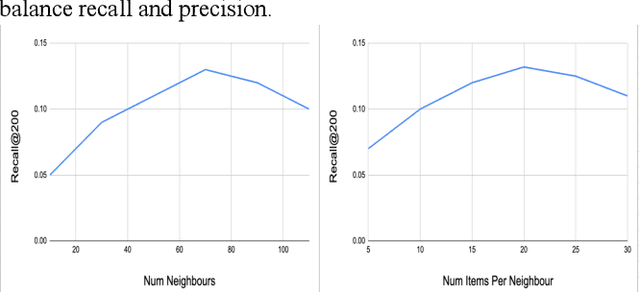
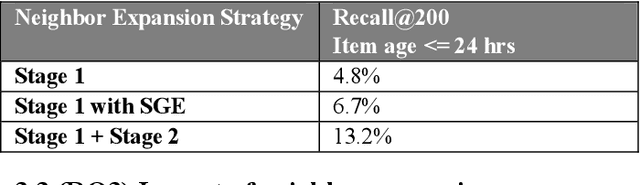
Most industry scale recommender systems face critical cold start challenges new items lack interaction history, making it difficult to distribute them in a personalized manner. Standard collaborative filtering models underperform due to sparse engagement signals, while content only approaches lack user specific relevance. We propose SocRipple, a novel two stage retrieval framework tailored for coldstart item distribution in social graph based platforms. Stage 1 leverages the creators social connections for targeted initial exposure. Stage 2 builds on early engagement signals and stable user embeddings learned from historical interactions to "ripple" outwards via K Nearest Neighbor (KNN) search. Large scale experiments on a major video platform show that SocRipple boosts cold start item distribution by +36% while maintaining user engagement rate on cold start items, effectively balancing new item exposure with personalized recommendations.
RADAR: Recall Augmentation through Deferred Asynchronous Retrieval
Jun 08, 2025Modern large-scale recommender systems employ multi-stage ranking funnel (Retrieval, Pre-ranking, Ranking) to balance engagement and computational constraints (latency, CPU). However, the initial retrieval stage, often relying on efficient but less precise methods like K-Nearest Neighbors (KNN), struggles to effectively surface the most engaging items from billion-scale catalogs, particularly distinguishing highly relevant and engaging candidates from merely relevant ones. We introduce Recall Augmentation through Deferred Asynchronous Retrieval (RADAR), a novel framework that leverages asynchronous, offline computation to pre-rank a significantly larger candidate set for users using the full complexity ranking model. These top-ranked items are stored and utilized as a high-quality retrieval source during online inference, bypassing online retrieval and pre-ranking stages for these candidates. We demonstrate through offline experiments that RADAR significantly boosts recall (2X Recall@200 vs DNN retrieval baseline) by effectively combining a larger retrieved candidate set with a more powerful ranking model. Online A/B tests confirm a +0.8% lift in topline engagement metrics, validating RADAR as a practical and effective method to improve recommendation quality under strict online serving constraints.
Finding Interest Needle in Popularity Haystack: Improving Retrieval by Modeling Item Exposure
Mar 31, 2025Recommender systems operate in closed feedback loops, where user interactions reinforce popularity bias, leading to over-recommendation of already popular items while under-exposing niche or novel content. Existing bias mitigation methods, such as Inverse Propensity Scoring (IPS) and Off- Policy Correction (OPC), primarily operate at the ranking stage or during training, lacking explicit real-time control over exposure dynamics. In this work, we introduce an exposure- aware retrieval scoring approach, which explicitly models item exposure probability and adjusts retrieval-stage ranking at inference time. Unlike prior work, this method decouples exposure effects from engagement likelihood, enabling controlled trade-offs between fairness and engagement in large-scale recommendation platforms. We validate our approach through online A/B experiments in a real-world video recommendation system, demonstrating a 25% increase in uniquely retrieved items and a 40% reduction in the dominance of over-popular content, all while maintaining overall user engagement levels. Our results establish a scalable, deployable solution for mitigating popularity bias at the retrieval stage, offering a new paradigm for bias-aware personalization.