 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Sampling via Wasserstein Autoencoders and Triangular Transport
Apr 03, 2026We present Conditional Wasserstein Autoencoders (CWAEs), a framework for conditional simulation that exploits low-dimensional structure in both the conditioned and the conditioning variables. The key idea is to modify a Wasserstein autoencoder to use a (block-) triangular decoder and impose an appropriate independence assumption on the latent variables. We show that the resulting model gives an autoencoder that can exploit low-dimensional structure while simultaneously the decoder can be used for conditional simulation. We explore various theoretical properties of CWAEs, including their connections to conditional optimal transport (OT) problems. We also present alternative formulations that lead to three architectural variants forming the foundation of our algorithms. We present a series of numerical experiments that demonstrate that our different CWAE variants achieve substantial reductions in approximation error relative to the low-rank ensemble Kalman filter (LREnKF), particularly in problems where the support of the conditional measures is truly low-dimensional.
Causal Optimal Coupling for Gaussian Input-Output Distributional Data
Apr 01, 2026We study the problem of identifying an optimal coupling between input-output distributional data generated by a causal dynamical system. The coupling is required to satisfy prescribed marginal distributions and a causality constraint reflecting the temporal structure of the system. We formulate this problem as a Schr"odinger Bridge, which seeks the coupling closest - in Kullback-Leibler divergence - to a given prior while enforcing both marginal and causality constraints. For the case of Gaussian marginals and general time-dependent quadratic cost functions, we derive a fully tractable characterization of the Sinkhorn iterations that converges to the optimal solution. Beyond its theoretical contribution, the proposed framework provides a principled foundation for applying causal optimal transport methods to system identification from distributional data.
Error Analysis of Triangular Optimal Transport Maps for Filtering
Oct 22, 2025We present a systematic analysis of estimation errors for a class of optimal transport based algorithms for filtering and data assimilation. Along the way, we extend previous error analyses of Brenier maps to the case of conditional Brenier maps that arise in the context of simulation based inference. We then apply these results in a filtering scenario to analyze the optimal transport filtering algorithm of Al-Jarrah et al. (2024, ICML). An extension of that algorithm along with numerical benchmarks on various non-Gaussian and high-dimensional examples are provided to demonstrate its effectiveness and practical potential.
Fast filtering of non-Gaussian models using Amortized Optimal Transport Maps
Mar 16, 2025In this paper, we present the amortized optimal transport filter (A-OTF) designed to mitigate the computational burden associated with the real-time training of optimal transport filters (OTFs). OTFs can perform accurate non-Gaussian Bayesian updates in the filtering procedure, but they require training at every time step, which makes them expensive. The proposed A-OTF framework exploits the similarity between OTF maps during an initial/offline training stage in order to reduce the cost of inference during online calculations. More precisely, we use clustering algorithms to select relevant subsets of pre-trained maps whose weighted average is used to compute the A-OTF model akin to a mixture of experts. A series of numerical experiments validate that A-OTF achieves substantial computational savings during online inference while preserving the inherent flexibility and accuracy of OTF.
Conditional Optimal Transport on Function Spaces
Nov 17, 2023



We present a systematic study of conditional triangular transport maps in function spaces from the perspective of optimal transportation and with a view towards amortized Bayesian inference. More specifically, we develop a theory of constrained optimal transport problems that describe block-triangular Monge maps that characterize conditional measures along with their Kantorovich relaxations. This generalizes the theory of optimal triangular transport to separable infinite-dimensional function spaces with general cost functions. We further tailor our results to the case of Bayesian inference problems and obtain regularity estimates on the conditioning maps from the prior to the posterior. Finally, we present numerical experiments that demonstrate the computational applicability of our theoretical results for amortized and likelihood-free inference of functional parameters.
Optimal Transport-based Nonlinear Filtering in High-dimensional Settings
Oct 21, 2023



This paper addresses the problem of nonlinear filtering, i.e., computing the conditional distribution of the state of a stochastic dynamical system given a history of noisy partial observations. The primary focus is on scenarios involving degenerate likelihoods or high-dimensional states, where traditional sequential importance resampling (SIR) particle filters face the weight degeneracy issue. Our proposed method builds on an optimal transport interpretation of nonlinear filtering, leading to a simulation-based and likelihood-free algorithm that estimates the Brenier optimal transport map from the current distribution of the state to the distribution at the next time step. Our formulation allows us to harness the approximation power of neural networks to model complex and multi-modal distributions and employ stochastic optimization algorithms to enhance scalability. Extensive numerical experiments are presented that compare our method to the SIR particle filter and the ensemble Kalman filter, demonstrating the superior performance of our method in terms of sample efficiency, high-dimensional scalability, and the ability to capture complex and multi-modal distributions.
Duality-Based Stochastic Policy Optimization for Estimation with Unknown Noise Covariances
Oct 26, 2022
Duality of control and estimation allows mapping recent advances in data-guided control to the estimation setup. This paper formalizes and utilizes such a mapping by considering learning the optimal (steady-state) Kalman gain when process and measurement noise statistics are unknown. Specifically, building on the duality between synthesizing optimal control and estimation gains, the filter design problem is formalized as direct policy learning; subsequently, a Stochastic Gradient Descent (SGD) approach is adopted to learn the optimal filter gain. In this direction, control and estimation duality is also used to extend existing theoretical results for direct policy updates for Linear Quadratic Regulator (LQR) to establish convergence of the proposed algorithm-while addressing subtle differences between the two synthesis problems. The results are illustrated via several numerical examples.
An Optimal Transport Formulation of Bayes' Law for Nonlinear Filtering Algorithms
Mar 22, 2022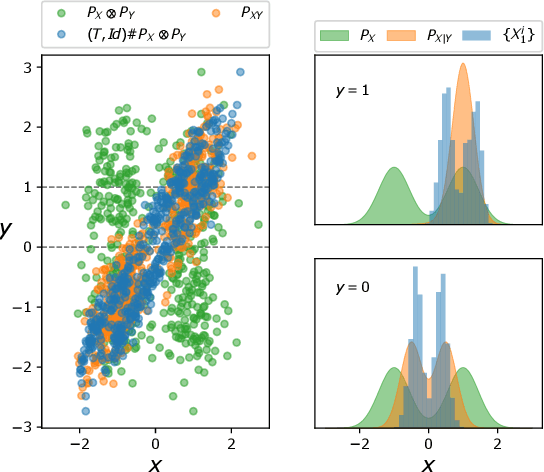
This paper presents a variational representation of the Bayes' law using optimal transportation theory. The variational representation is in terms of the optimal transportation between the joint distribution of the (state, observation) and their independent coupling. By imposing certain structure on the transport map, the solution to the variational problem is used to construct a Brenier-type map that transports the prior distribution to the posterior distribution for any value of the observation signal. The new formulation is used to derive the optimal transport form of the Ensemble Kalman filter (EnKF) for the discrete-time filtering problem and propose a novel extension of EnKF to the non-Gaussian setting utilizing input convex neural networks. Finally, the proposed methodology is used to derive the optimal transport form of the feedback particle filler (FPF) in the continuous-time limit, which constitutes its first variational construction without explicitly using the nonlinear filtering equation or Bayes' law.
Variational Wasserstein gradient flow
Dec 04, 2021



The gradient flow of a function over the space of probability densities with respect to the Wasserstein metric often exhibits nice properties and has been utilized in several machine learning applications. The standard approach to compute the Wasserstein gradient flow is the finite difference which discretizes the underlying space over a grid, and is not scalable. In this work, we propose a scalable proximal gradient type algorithm for Wasserstein gradient flow. The key of our method is a variational formulation of the objective function, which makes it possible to realize the JKO proximal map through a primal-dual optimization. This primal-dual problem can be efficiently solved by alternatively updating the parameters in the inner and outer loops. Our framework covers all the classical Wasserstein gradient flows including the heat equation and the porous medium equation. We demonstrate the performance and scalability of our algorithm with several numerical examples.
Deep FPF: Gain function approximation in high-dimensional setting
Oct 02, 2020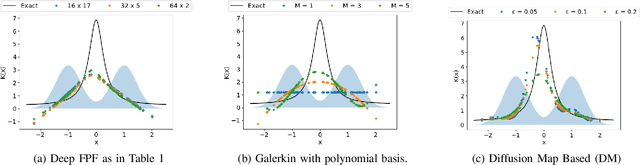
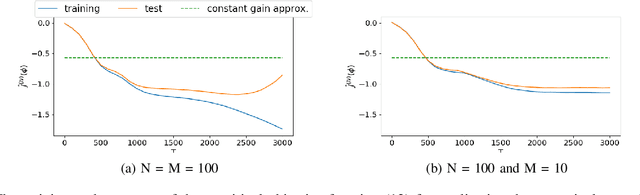
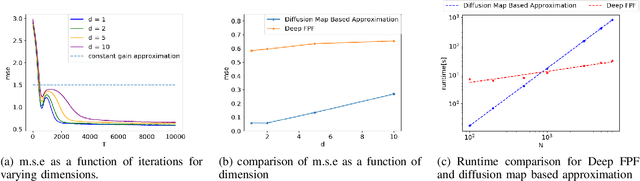
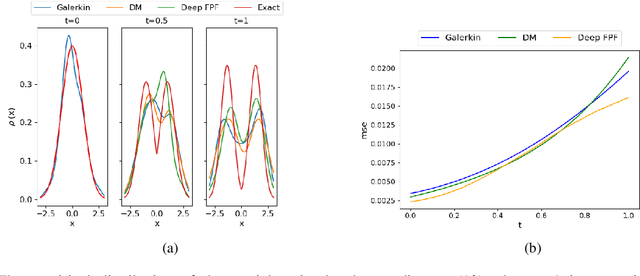
In this paper, we present a novel approach to approximate the gain function of the feedback particle filter (FPF). The exact gain function is the solution of a Poisson equation involving a probability-weighted Laplacian. The numerical problem is to approximate the exact gain function using only finitely many particles sampled from the probability distribution. Inspired by the recent success of the deep learning methods, we represent the gain function as a gradient of the output of a neural network. Thereupon considering a certain variational formulation of the Poisson equation, an optimization problem is posed for learning the weights of the neural network. A stochastic gradient algorithm is described for this purpose. The proposed approach has two significant properties/advantages: (i) The stochastic optimization algorithm allows one to process, in parallel, only a batch of samples (particles) ensuring good scaling properties with the number of particles; (ii) The remarkable representation power of neural networks means that the algorithm is potentially applicable and useful to solve high-dimensional problems. We numerically establish these two properties and provide extensive comparison to the existing approaches.