 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning via Differential Privacy
Feb 10, 2018
We explore the use of tools from differential privacy in the design and analysis of online learning algorithms. We develop a simple and powerful analysis technique for Follow-The-Leader type algorithms under privacy-preserving perturbations. This leads to the minimax optimal algorithm for k-sparse online PCA and the best-known perturbation based algorithm for the dense online PCA. We also show that the differential privacy is the core notion of algorithm stability in various online learning problems.
Lasso Guarantees for Time Series Estimation Under Subgaussian Tails and $ β$-Mixing
Feb 05, 2018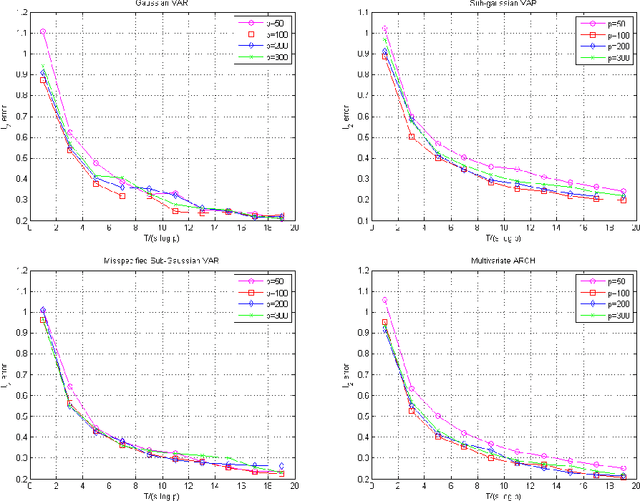
Many theoretical results on estimation of high dimensional time series require specifying an underlying data generating model (DGM). Instead, along the footsteps of~\cite{wong2017lasso}, this paper relies only on (strict) stationarity and $ \beta $-mixing condition to establish consistency of lasso when data comes from a $\beta$-mixing process with marginals having subgaussian tails. Because of the general assumptions, the data can come from DGMs different than standard time series models such as VAR or ARCH. When the true DGM is not VAR, the lasso estimates correspond to those of the best linear predictors using the past observations. We establish non-asymptotic inequalities for estimation and prediction errors of the lasso estimates. Together with~\cite{wong2017lasso}, we provide lasso guarantees that cover full spectrum of the parameters in specifications of $ \beta $-mixing subgaussian time series. Applications of these results potentially extend to non-Gaussian, non-Markovian and non-linear times series models as the examples we provide demonstrate. In order to prove our results, we derive a novel Hanson-Wright type concentration inequality for $\beta$-mixing subgaussian random vectors that may be of independent interest.
Beyond the Hazard Rate: More Perturbation Algorithms for Adversarial Multi-armed Bandits
Jan 05, 2018Recent work on follow the perturbed leader (FTPL) algorithms for the adversarial multi-armed bandit problem has highlighted the role of the hazard rate of the distribution generating the perturbations. Assuming that the hazard rate is bounded, it is possible to provide regret analyses for a variety of FTPL algorithms for the multi-armed bandit problem. This paper pushes the inquiry into regret bounds for FTPL algorithms beyond the bounded hazard rate condition. There are good reasons to do so: natural distributions such as the uniform and Gaussian violate the condition. We give regret bounds for both bounded support and unbounded support distributions without assuming the hazard rate condition. We also disprove a conjecture that the Gaussian distribution cannot lead to a low-regret algorithm. In fact, it turns out that it leads to near optimal regret, up to logarithmic factors. A key ingredient in our approach is the introduction of a new notion called the generalized hazard rate.
Markov Decision Processes with Continuous Side Information
Nov 15, 2017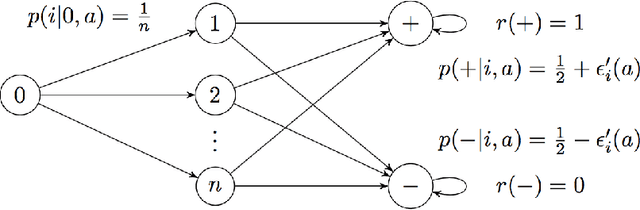
We consider a reinforcement learning (RL) setting in which the agent interacts with a sequence of episodic MDPs. At the start of each episode the agent has access to some side-information or context that determines the dynamics of the MDP for that episode. Our setting is motivated by applications in healthcare where baseline measurements of a patient at the start of a treatment episode form the context that may provide information about how the patient might respond to treatment decisions. We propose algorithms for learning in such Contextual Markov Decision Processes (CMDPs) under an assumption that the unobserved MDP parameters vary smoothly with the observed context. We also give lower and upper PAC bounds under the smoothness assumption. Because our lower bound has an exponential dependence on the dimension, we consider a tractable linear setting where the context is used to create linear combinations of a finite set of MDPs. For the linear setting, we give a PAC learning algorithm based on KWIK learning techniques.
An Actor-Critic Contextual Bandit Algorithm for Personalized Mobile Health Interventions
Jun 28, 2017
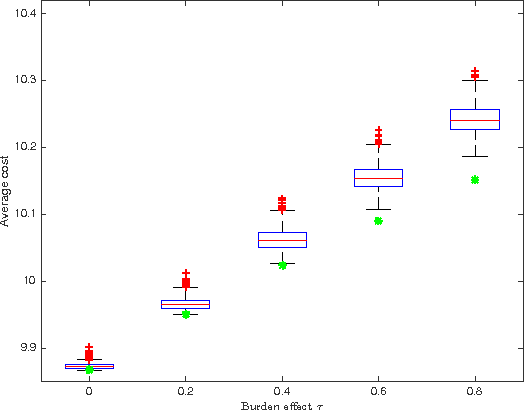
Increasing technological sophistication and widespread use of smartphones and wearable devices provide opportunities for innovative and highly personalized health interventions. A Just-In-Time Adaptive Intervention (JITAI) uses real-time data collection and communication capabilities of modern mobile devices to deliver interventions in real-time that are adapted to the in-the-moment needs of the user. The lack of methodological guidance in constructing data-based JITAIs remains a hurdle in advancing JITAI research despite the increasing popularity of JITAIs among clinical scientists. In this article, we make a first attempt to bridge this methodological gap by formulating the task of tailoring interventions in real-time as a contextual bandit problem. Interpretability requirements in the domain of mobile health lead us to formulate the problem differently from existing formulations intended for web applications such as ad or news article placement. Under the assumption of linear reward function, we choose the reward function (the "critic") parameterization separately from a lower dimensional parameterization of stochastic policies (the "actor"). We provide an online actor-critic algorithm that guides the construction and refinement of a JITAI. Asymptotic properties of the actor-critic algorithm are developed and backed up by numerical experiments. Additional numerical experiments are conducted to test the robustness of the algorithm when idealized assumptions used in the analysis of contextual bandit algorithm are breached.
Sampled Fictitious Play is Hannan Consistent
Apr 11, 2017Fictitious play is a simple and widely studied adaptive heuristic for playing repeated games. It is well known that fictitious play fails to be Hannan consistent. Several variants of fictitious play including regret matching, generalized regret matching and smooth fictitious play, are known to be Hannan consistent. In this note, we consider sampled fictitious play: at each round, the player samples past times and plays the best response to previous moves of other players at the sampled time points. We show that sampled fictitious play, using Bernoulli sampling, is Hannan consistent. Unlike several existing Hannan consistency proofs that rely on concentration of measure results, ours instead uses anti-concentration results from Littlewood-Offord theory.
On Lipschitz Continuity and Smoothness of Loss Functions in Learning to Rank
Sep 13, 2016In binary classification and regression problems, it is well understood that Lipschitz continuity and smoothness of the loss function play key roles in governing generalization error bounds for empirical risk minimization algorithms. In this paper, we show how these two properties affect generalization error bounds in the learning to rank problem. The learning to rank problem involves vector valued predictions and therefore the choice of the norm with respect to which Lipschitz continuity and smoothness are defined becomes crucial. Choosing the $\ell_\infty$ norm in our definition of Lipschitz continuity allows us to improve existing bounds. Furthermore, under smoothness assumptions, our choice enables us to prove rates that interpolate between $1/\sqrt{n}$ and $1/n$ rates. Application of our results to ListNet, a popular learning to rank method, gives state-of-the-art performance guarantees.
Online Learning to Rank with Top-k Feedback
Aug 23, 2016
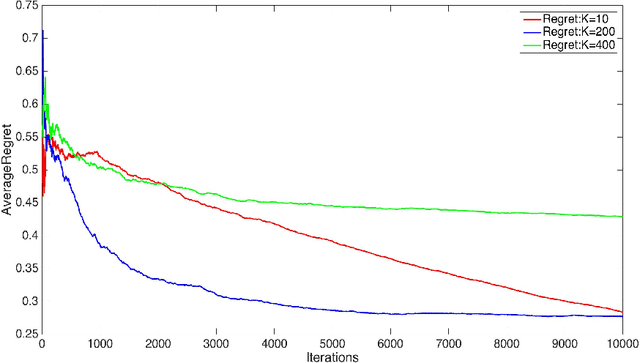
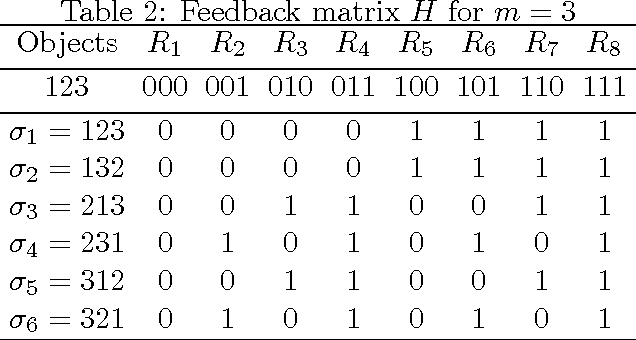
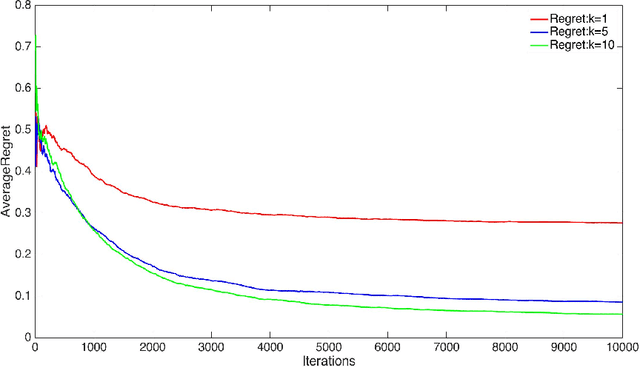
We consider two settings of online learning to rank where feedback is restricted to top ranked items. The problem is cast as an online game between a learner and sequence of users, over $T$ rounds. In both settings, the learners objective is to present ranked list of items to the users. The learner's performance is judged on the entire ranked list and true relevances of the items. However, the learner receives highly restricted feedback at end of each round, in form of relevances of only the top $k$ ranked items, where $k \ll m$. The first setting is \emph{non-contextual}, where the list of items to be ranked is fixed. The second setting is \emph{contextual}, where lists of items vary, in form of traditional query-document lists. No stochastic assumption is made on the generation process of relevances of items and contexts. We provide efficient ranking strategies for both the settings. The strategies achieve $O(T^{2/3})$ regret, where regret is based on popular ranking measures in first setting and ranking surrogates in second setting. We also provide impossibility results for certain ranking measures and a certain class of surrogates, when feedback is restricted to the top ranked item, i.e. $k=1$. We empirically demonstrate the performance of our algorithms on simulated and real world datasets.
Phased Exploration with Greedy Exploitation in Stochastic Combinatorial Partial Monitoring Games
Aug 23, 2016Partial monitoring games are repeated games where the learner receives feedback that might be different from adversary's move or even the reward gained by the learner. Recently, a general model of combinatorial partial monitoring (CPM) games was proposed \cite{lincombinatorial2014}, where the learner's action space can be exponentially large and adversary samples its moves from a bounded, continuous space, according to a fixed distribution. The paper gave a confidence bound based algorithm (GCB) that achieves $O(T^{2/3}\log T)$ distribution independent and $O(\log T)$ distribution dependent regret bounds. The implementation of their algorithm depends on two separate offline oracles and the distribution dependent regret additionally requires existence of a unique optimal action for the learner. Adopting their CPM model, our first contribution is a Phased Exploration with Greedy Exploitation (PEGE) algorithmic framework for the problem. Different algorithms within the framework achieve $O(T^{2/3}\sqrt{\log T})$ distribution independent and $O(\log^2 T)$ distribution dependent regret respectively. Crucially, our framework needs only the simpler "argmax" oracle from GCB and the distribution dependent regret does not require existence of a unique optimal action. Our second contribution is another algorithm, PEGE2, which combines gap estimation with a PEGE algorithm, to achieve an $O(\log T)$ regret bound, matching the GCB guarantee but removing the dependence on size of the learner's action space. However, like GCB, PEGE2 requires access to both offline oracles and the existence of a unique optimal action. Finally, we discuss how our algorithm can be efficiently applied to a CPM problem of practical interest: namely, online ranking with feedback at the top.
Perceptron like Algorithms for Online Learning to Rank
Aug 23, 2016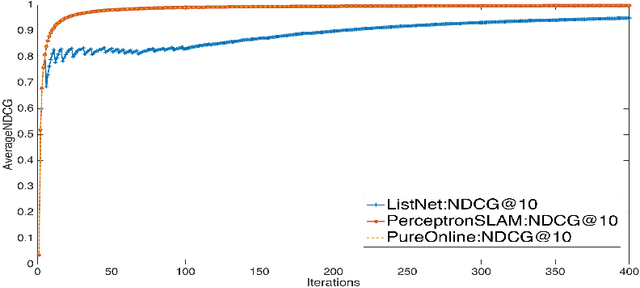
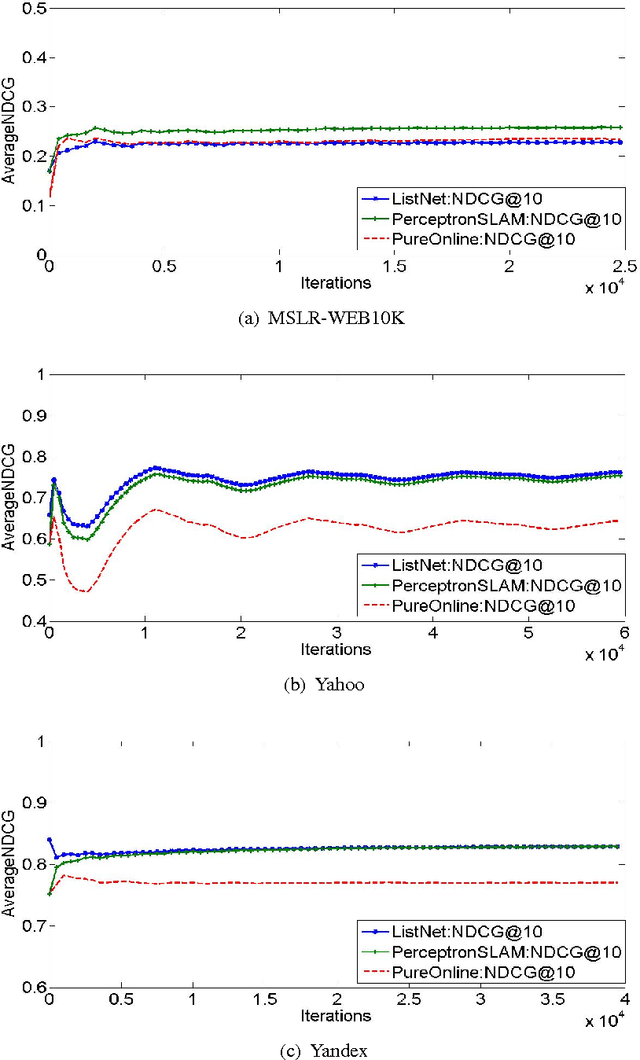
Perceptron is a classic online algorithm for learning a classification function. In this paper, we provide a novel extension of the perceptron algorithm to the learning to rank problem in information retrieval. We consider popular listwise performance measures such as Normalized Discounted Cumulative Gain (NDCG) and Average Precision (AP). A modern perspective on perceptron for classification is that it is simply an instance of online gradient descent (OGD), during mistake rounds, using the hinge loss function. Motivated by this interpretation, we propose a novel family of listwise, large margin ranking surrogates. Members of this family can be thought of as analogs of the hinge loss. Exploiting a certain self-bounding property of the proposed family, we provide a guarantee on the cumulative NDCG (or AP) induced loss incurred by our perceptron-like algorithm. We show that, if there exists a perfect oracle ranker which can correctly rank each instance in an online sequence of ranking data, with some margin, the cumulative loss of perceptron algorithm on that sequence is bounded by a constant, irrespective of the length of the sequence. This result is reminiscent of Novikoff's convergence theorem for the classification perceptron. Moreover, we prove a lower bound on the cumulative loss achievable by any deterministic algorithm, under the assumption of existence of perfect oracle ranker. The lower bound shows that our perceptron bound is not tight, and we propose another, \emph{purely online}, algorithm which achieves the lower bound. We provide empirical results on simulated and large commercial datasets to corroborate our theoretical results.