 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn collapsed representation of hierarchical Completely Random Measures
Jun 02, 2016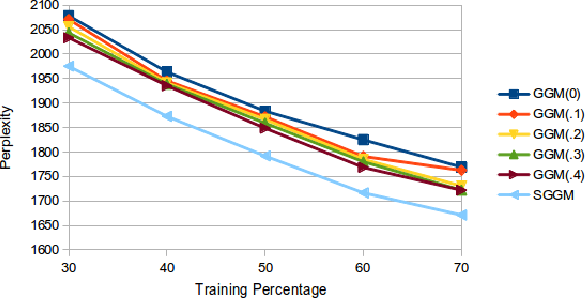
The aim of the paper is to provide an exact approach for generating a Poisson process sampled from a hierarchical CRM, without having to instantiate the infinitely many atoms of the random measures. We use completely random measures~(CRM) and hierarchical CRM to define a prior for Poisson processes. We derive the marginal distribution of the resultant point process, when the underlying CRM is marginalized out. Using well known properties unique to Poisson processes, we were able to derive an exact approach for instantiating a Poisson process with a hierarchical CRM prior. Furthermore, we derive Gibbs sampling strategies for hierarchical CRM models based on Chinese restaurant franchise sampling scheme. As an example, we present the sum of generalized gamma process (SGGP), and show its application in topic-modelling. We show that one can determine the power-law behaviour of the topics and words in a Bayesian fashion, by defining a prior on the parameters of SGGP.
Consistency of Spectral Hypergraph Partitioning under Planted Partition Model
Feb 03, 2016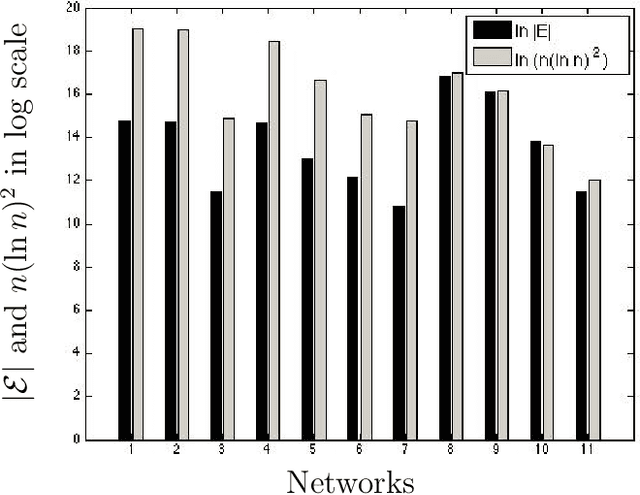

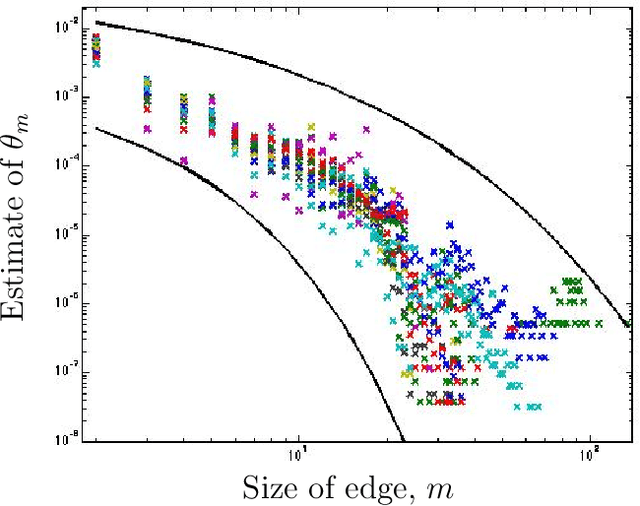
Hypergraph partitioning lies at the heart of a number of problems in machine learning and network sciences. Many algorithms for hypergraph partitioning have been proposed that extend standard approaches for graph partitioning to the case of hypergraphs. However, theoretical aspects of such methods have seldom received attention in the literature as compared to the extensive studies on the guarantees of graph partitioning. For instance, consistency results of spectral graph partitioning under the stochastic block model are well known. In this paper, we present a planted partition model for sparse random non-uniform hypergraphs that generalizes the stochastic block model. We derive an error bound for a spectral hypergraph partitioning algorithm under this model using matrix concentration inequalities. To the best of our knowledge, this is the first consistency result related to partitioning non-uniform hypergraphs.
* 35 pages, 2 figures, 1 table
Smoothed Functional Algorithms for Stochastic Optimization using q-Gaussian Distributions
Jul 03, 2014
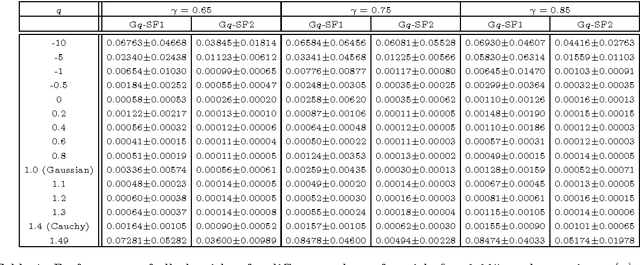
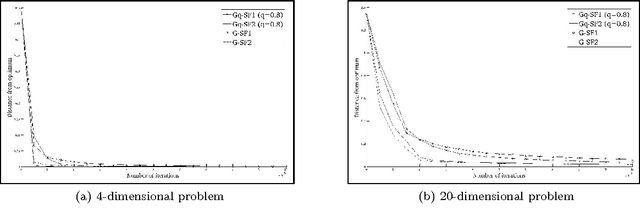
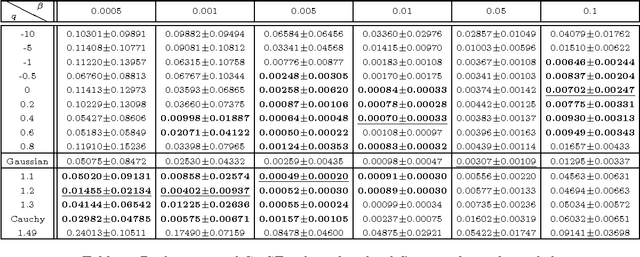
Smoothed functional (SF) schemes for gradient estimation are known to be efficient in stochastic optimization algorithms, specially when the objective is to improve the performance of a stochastic system. However, the performance of these methods depends on several parameters, such as the choice of a suitable smoothing kernel. Different kernels have been studied in literature, which include Gaussian, Cauchy and uniform distributions among others. This paper studies a new class of kernels based on the q-Gaussian distribution, that has gained popularity in statistical physics over the last decade. Though the importance of this family of distributions is attributed to its ability to generalize the Gaussian distribution, we observe that this class encompasses almost all existing smoothing kernels. This motivates us to study SF schemes for gradient estimation using the q-Gaussian distribution. Using the derived gradient estimates, we propose two-timescale algorithms for optimization of a stochastic objective function in a constrained setting with projected gradient search approach. We prove the convergence of our algorithms to the set of stationary points of an associated ODE. We also demonstrate their performance numerically through simulations on a queuing model.
Spectral Clustering with Jensen-type kernels and their multi-point extensions
Mar 18, 2014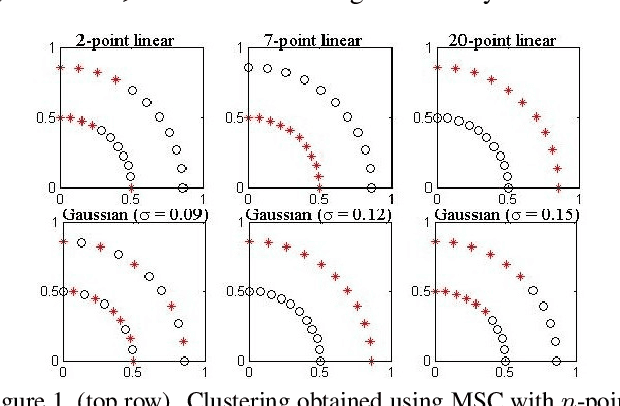
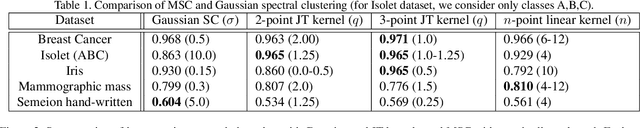
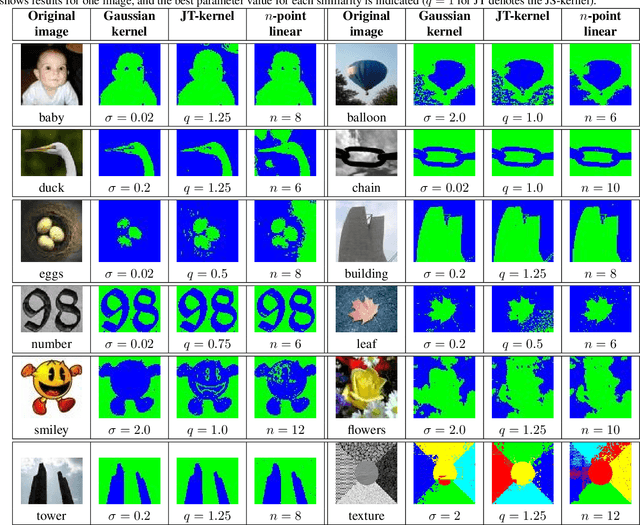
Motivated by multi-distribution divergences, which originate in information theory, we propose a notion of `multi-point' kernels, and study their applications. We study a class of kernels based on Jensen type divergences and show that these can be extended to measure similarity among multiple points. We study tensor flattening methods and develop a multi-point (kernel) spectral clustering (MSC) method. We further emphasize on a special case of the proposed kernels, which is a multi-point extension of the linear (dot-product) kernel and show the existence of cubic time tensor flattening algorithm in this case. Finally, we illustrate the usefulness of our contributions using standard data sets and image segmentation tasks.
To go deep or wide in learning?
Feb 23, 2014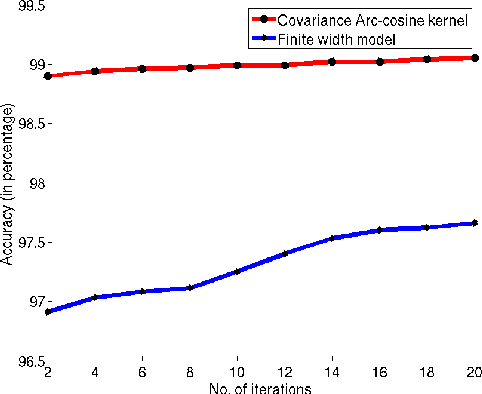
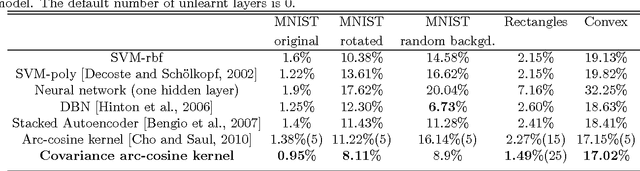
To achieve acceptable performance for AI tasks, one can either use sophisticated feature extraction methods as the first layer in a two-layered supervised learning model, or learn the features directly using a deep (multi-layered) model. While the first approach is very problem-specific, the second approach has computational overheads in learning multiple layers and fine-tuning of the model. In this paper, we propose an approach called wide learning based on arc-cosine kernels, that learns a single layer of infinite width. We propose exact and inexact learning strategies for wide learning and show that wide learning with single layer outperforms single layer as well as deep architectures of finite width for some benchmark datasets.
Generative Maximum Entropy Learning for Multiclass Classification
Dec 30, 2013Maximum entropy approach to classification is very well studied in applied statistics and machine learning and almost all the methods that exists in literature are discriminative in nature. In this paper, we introduce a maximum entropy classification method with feature selection for large dimensional data such as text datasets that is generative in nature. To tackle the curse of dimensionality of large data sets, we employ conditional independence assumption (Naive Bayes) and we perform feature selection simultaneously, by enforcing a `maximum discrimination' between estimated class conditional densities. For two class problems, in the proposed method, we use Jeffreys ($J$) divergence to discriminate the class conditional densities. To extend our method to the multi-class case, we propose a completely new approach by considering a multi-distribution divergence: we replace Jeffreys divergence by Jensen-Shannon ($JS$) divergence to discriminate conditional densities of multiple classes. In order to reduce computational complexity, we employ a modified Jensen-Shannon divergence ($JS_{GM}$), based on AM-GM inequality. We show that the resulting divergence is a natural generalization of Jeffreys divergence to a multiple distributions case. As far as the theoretical justifications are concerned we show that when one intends to select the best features in a generative maximum entropy approach, maximum discrimination using $J-$divergence emerges naturally in binary classification. Performance and comparative study of the proposed algorithms have been demonstrated on large dimensional text and gene expression datasets that show our methods scale up very well with large dimensional datasets.
On Power-law Kernels, corresponding Reproducing Kernel Hilbert Space and Applications
Apr 01, 2013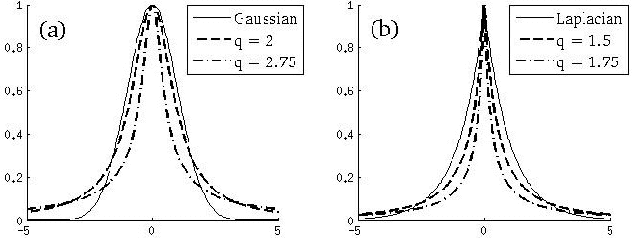
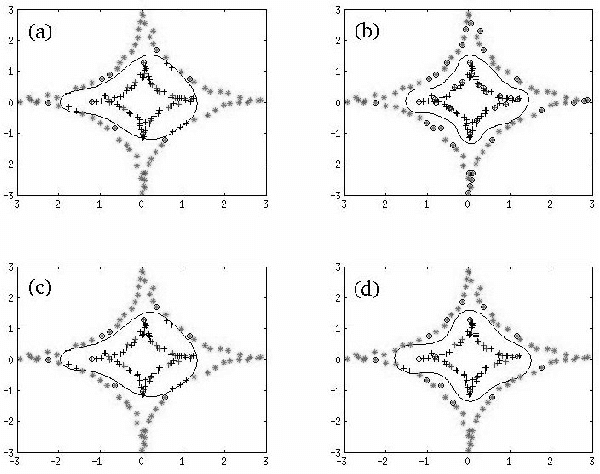
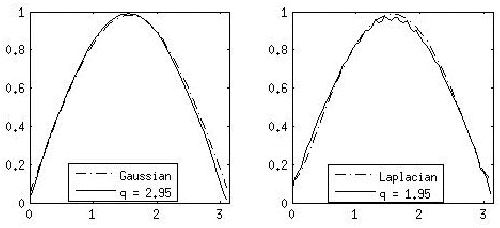
The role of kernels is central to machine learning. Motivated by the importance of power-law distributions in statistical modeling, in this paper, we propose the notion of power-law kernels to investigate power-laws in learning problem. We propose two power-law kernels by generalizing Gaussian and Laplacian kernels. This generalization is based on distributions, arising out of maximization of a generalized information measure known as nonextensive entropy that is very well studied in statistical mechanics. We prove that the proposed kernels are positive definite, and provide some insights regarding the corresponding Reproducing Kernel Hilbert Space (RKHS). We also study practical significance of both kernels in classification and regression, and present some simulation results.
Cauchy Annealing Schedule: An Annealing Schedule for Boltzmann Selection Scheme in Evolutionary Algorithms
Aug 24, 2004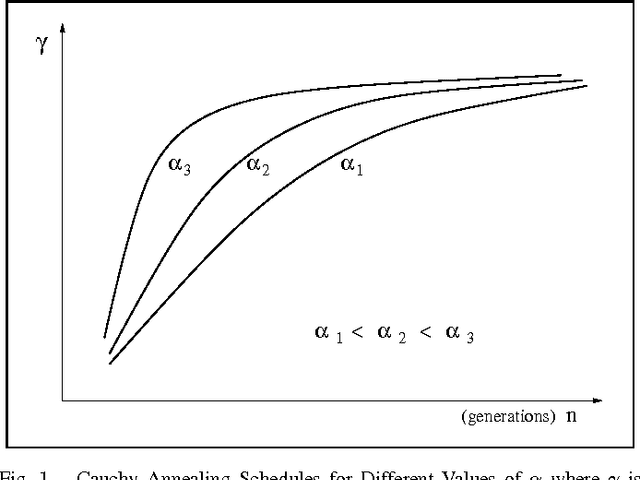
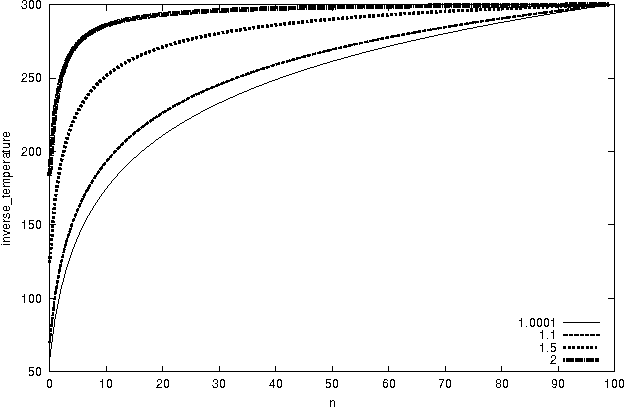
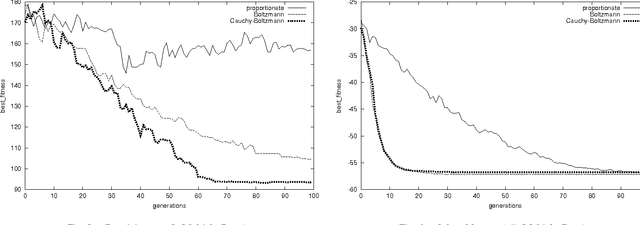
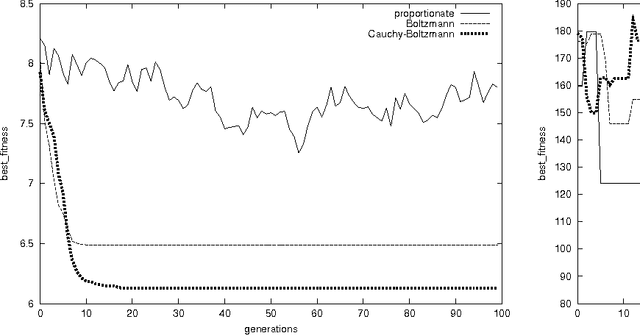
Boltzmann selection is an important selection mechanism in evolutionary algorithms as it has theoretical properties which help in theoretical analysis. However, Boltzmann selection is not used in practice because a good annealing schedule for the `inverse temperature' parameter is lacking. In this paper we propose a Cauchy annealing schedule for Boltzmann selection scheme based on a hypothesis that selection-strength should increase as evolutionary process goes on and distance between two selection strengths should decrease for the process to converge. To formalize these aspects, we develop formalism for selection mechanisms using fitness distributions and give an appropriate measure for selection-strength. In this paper, we prove an important result, by which we derive an annealing schedule called Cauchy annealing schedule. We demonstrate the novelty of proposed annealing schedule using simulations in the framework of genetic algorithms.
Generalized Evolutionary Algorithm based on Tsallis Statistics
Jul 16, 2004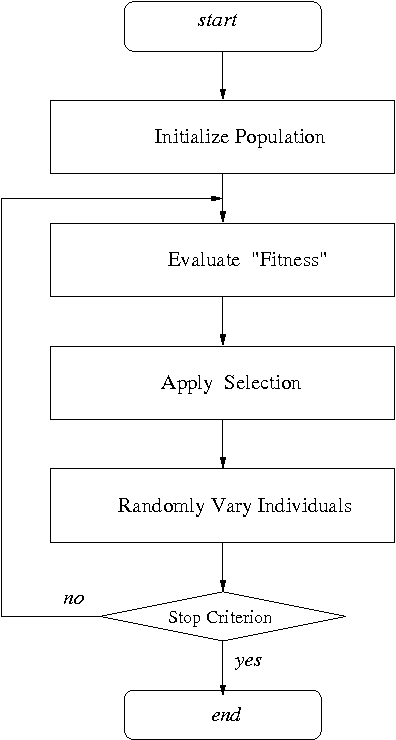

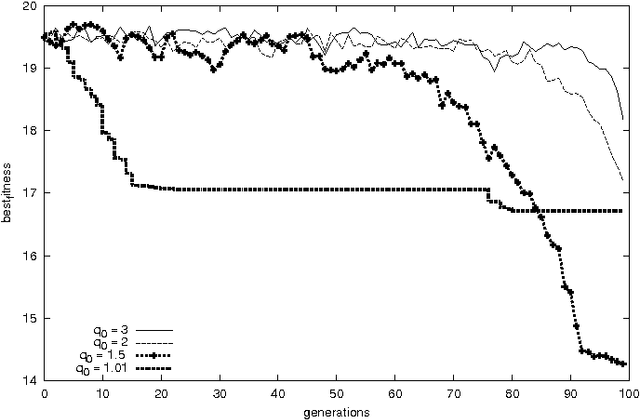
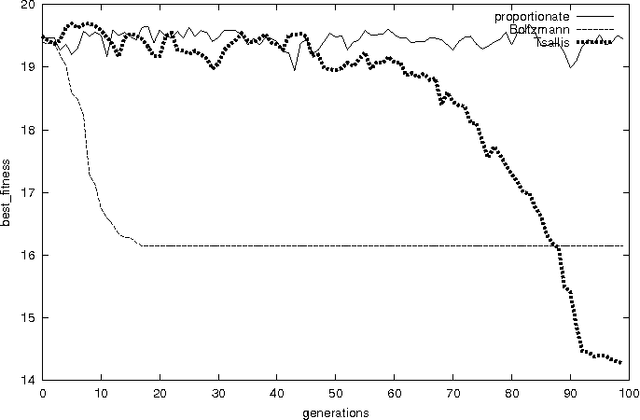
Generalized evolutionary algorithm based on Tsallis canonical distribution is proposed. The algorithm uses Tsallis generalized canonical distribution to weigh the configurations for `selection' instead of Gibbs-Boltzmann distribution. Our simulation results show that for an appropriate choice of non-extensive index that is offered by Tsallis statistics, evolutionary algorithms based on this generalization outperform algorithms based on Gibbs-Boltzmann distribution.