 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetworked Multi-Agent Reinforcement Learning with Emergent Communication
Apr 09, 2020

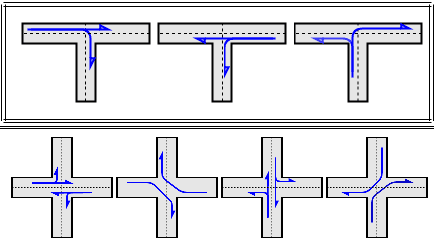
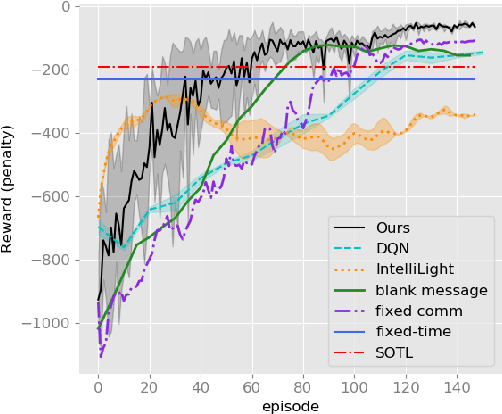
Multi-Agent Reinforcement Learning (MARL) methods find optimal policies for agents that operate in the presence of other learning agents. Central to achieving this is how the agents coordinate. One way to coordinate is by learning to communicate with each other. Can the agents develop a language while learning to perform a common task? In this paper, we formulate and study a MARL problem where cooperative agents are connected to each other via a fixed underlying network. These agents can communicate along the edges of this network by exchanging discrete symbols. However, the semantics of these symbols are not predefined and, during training, the agents are required to develop a language that helps them in accomplishing their goals. We propose a method for training these agents using emergent communication. We demonstrate the applicability of the proposed framework by applying it to the problem of managing traffic controllers, where we achieve state-of-the-art performance as compared to a number of strong baselines. More importantly, we perform a detailed analysis of the emergent communication to show, for instance, that the developed language is grounded and demonstrate its relationship with the underlying network topology. To the best of our knowledge, this is the only work that performs an in depth analysis of emergent communication in a networked MARL setting while being applicable to a broad class of problems.
A Statistical Model for Dynamic Networks with Neural Variational Inference
Nov 26, 2019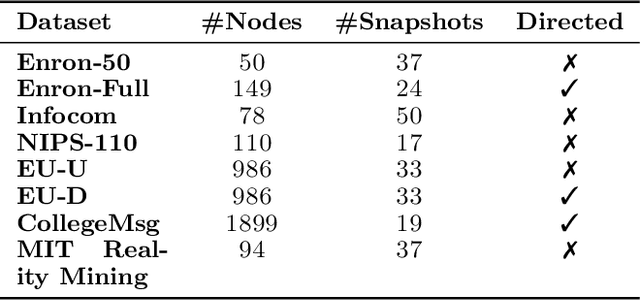
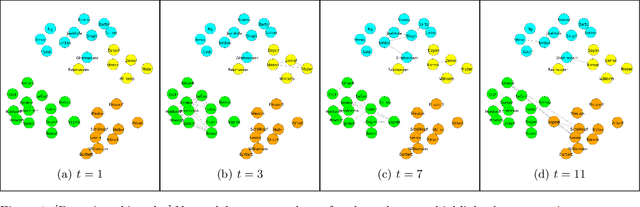
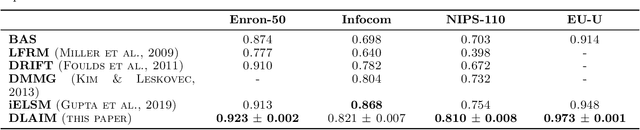
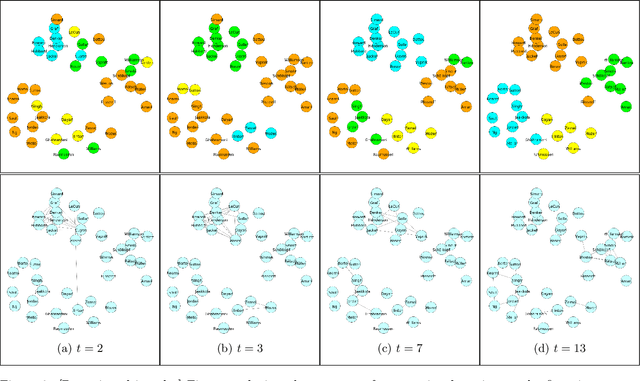
In this paper we propose a statistical model for dynamically evolving networks, together with a variational inference approach. Our model, which we call Dynamic Latent Attribute Interaction Model (DLAIM), encodes edge dependencies across different time snapshots. It represents nodes via latent attributes and uses attribute interaction matrices to model the presence of edges. Both are allowed to evolve with time, thus allowing us to capture the dynamics of the network. We develop a neural network based variational inference procedure that provides a suitable way to learn the model parameters. The main strengths of DLAIM are: (i) it is flexible as it does not impose strict assumptions on network evolution unlike existing approaches, (ii) it applies to both directed as well as undirected networks, and more importantly, (iii) learned node attributes and interaction matrices may be interpretable and therefore provide insights on the mechanisms behind network evolution. Experiments done on real world networks for the task of link forecasting demonstrate the superior performance of our model as compared to existing approaches.
Restricted Boltzmann Stochastic Block Model: A Generative Model for Networks with Attributes
Nov 11, 2019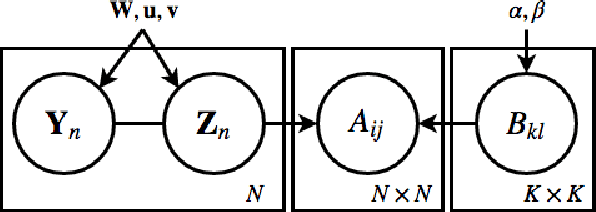
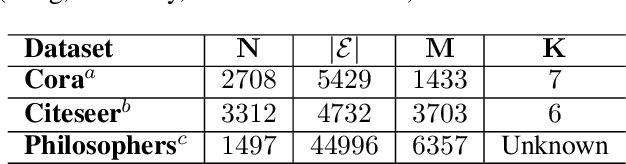
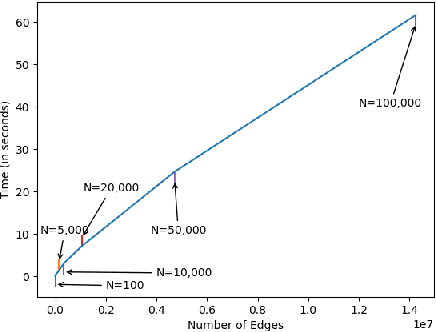
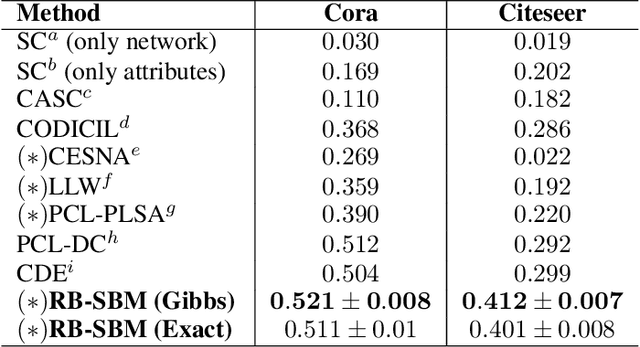
In most practical contexts network indexed data consists not only of a description about the presence/absence of links, but also attributes and information about the nodes and/or links. Building on success of Stochastic Block Models (SBM) we propose a simple yet powerful generalization of SBM for networks with node attributes. In a standard SBM the rows of latent community membership matrix are sampled from a multinomial. In RB-SBM, our proposed model, these rows are sampled from a Restricted Boltzmann Machine (RBM) that models a joint distribution over observed attributes and latent community membership. This model has the advantage of being simple while combining connectivity and attribute information, and it has very few tuning parameters. Furthermore, we show that inference can be done efficiently in linear time and it can be naturally extended to accommodate, for instance, overlapping communities. We demonstrate the performance of our model on multiple synthetic and real world networks with node attributes where we obtain state-of-the-art results on the task of community detection.
Active Learning with Siamese Twins for Sequence Tagging
Nov 01, 2019
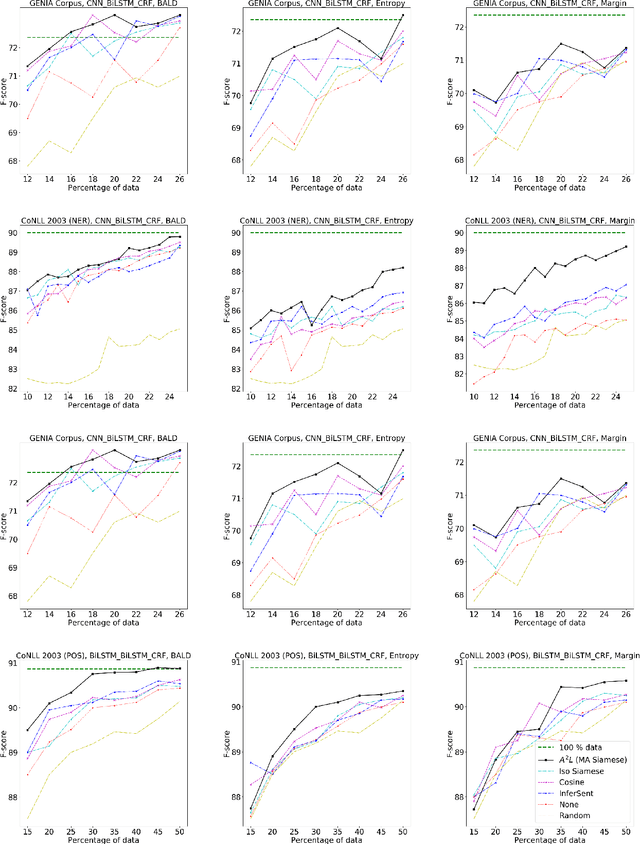
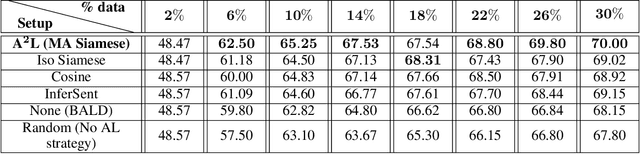
Deep learning, in general, and natural language processing methods, in particular, rely heavily on annotated samples to achieve good performance. However, manually annotating data is expensive and time consuming. Active Learning (AL) strategies reduce the need for huge volumes of labelled data by iteratively selecting a small number of examples for manual annotation based on their estimated utility in training the given model. In this paper, we argue that since AL strategies choose examples independently, they may potentially select similar examples, all of which do not aid in the learning process. We propose a method, referred to as Active$\mathbf{^2}$ Learning (A$\mathbf{^2}$L), that actively adapts to the sequence tagging model being trained, to further eliminate such redundant examples chosen by an AL strategy. We empirically demonstrate that A$\mathbf{^2}$L improves the performance of state-of-the-art AL strategies on different sequence tagging tasks. Furthermore, we show that A$\mathbf{^2}$L is widely applicable by using it in conjunction with different AL strategies and sequence tagging models. We demonstrate that the proposed A$\mathbf{^2}$L able to reach full data F-score with $\approx\mathbf{2-16 \%}$ less data compared to state-of-art AL strategies on different sequence tagging datasets.
CUDA: Contradistinguisher for Unsupervised Domain Adaptation
Sep 08, 2019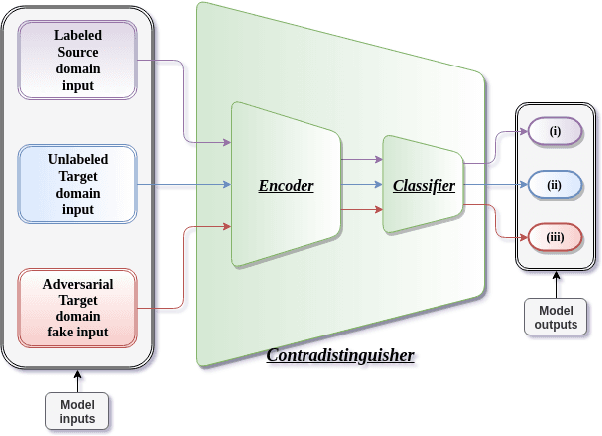

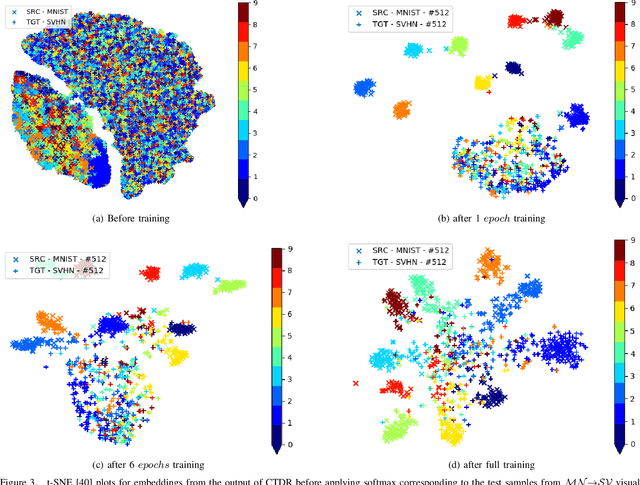
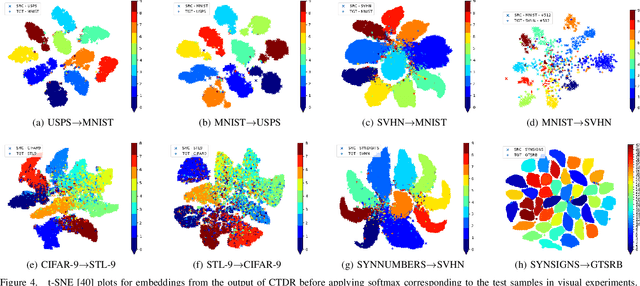
In this paper, we propose a simple model referred as Contradistinguisher (CTDR) for unsupervised domain adaptation whose objective is to jointly learn to contradistinguish on unlabeled target domain in a fully unsupervised manner along with prior knowledge acquired by supervised learning on an entirely different domain. Most recent works in domain adaptation rely on an indirect way of first aligning the source and target domain distributions and then learn a classifier on a labeled source domain to classify target domain. This approach of an indirect way of addressing the real task of unlabeled target domain classification has three main drawbacks. (i) The sub-task of obtaining a perfect alignment of the domain in itself might be impossible due to large domain shift (e.g., language domains). (ii) The use of multiple classifiers to align the distributions unnecessarily increases the complexity of the neural networks leading to over-fitting in many cases. (iii) Due to distribution alignment, the domain-specific information is lost as the domains get morphed. In this work, we propose a simple and direct approach that does not require domain alignment. We jointly learn CTDR on both source and target distribution for unsupervised domain adaptation task using contradistinguish loss for the unlabeled target domain in conjunction with a supervised loss for labeled source domain. Our experiments show that avoiding domain alignment by directly addressing the task of unlabeled target domain classification using CTDR achieves state-of-the-art results on eight visual and four language benchmark domain adaptation datasets.
On Voting Strategies and Emergent Communication
Feb 19, 2019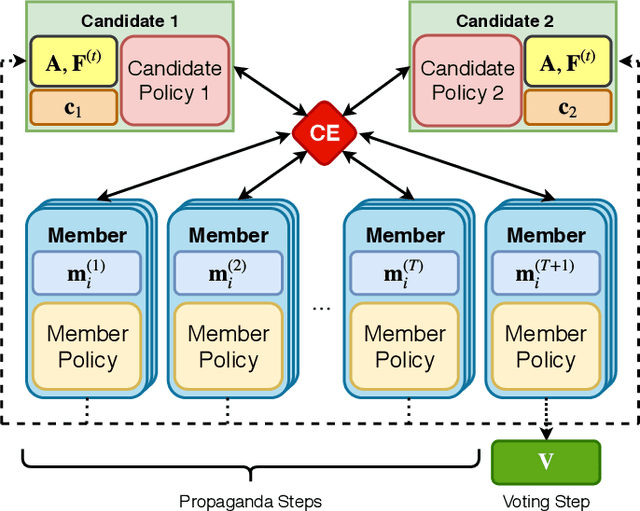

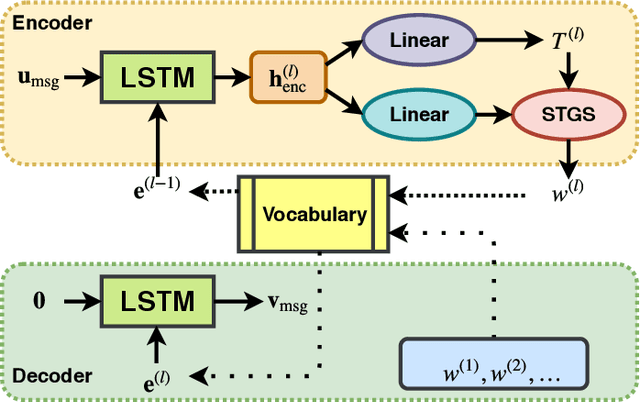
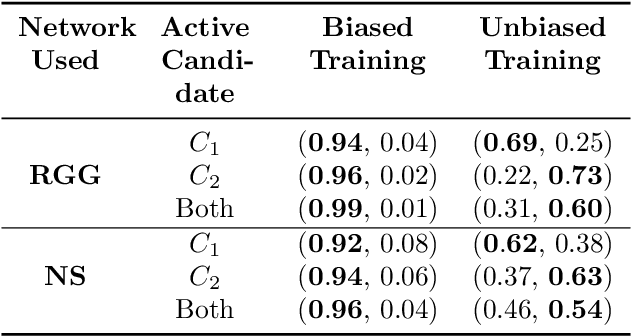
Humans use language to collectively execute complex strategies in addition to using it as a referential tool for referring to physical entities. While existing approaches that study the emergence of language in settings where the language mainly acts as a referential tool, in this paper, we study the role of emergent languages in discovering and implementing strategies in a multi-agent setting. The agents in our setup are connected via a network and are allowed to exchange messages in the form of sequences of discrete symbols. We formulate the problem as a voting game, where two candidate agents are contesting in an election and their goal is to convince the population members (other agents) in the network to vote for them by sending them messages. We use neural networks to parameterize the policies followed by agents in the game. We investigate the effect of choosing different training objectives and strategies for agents in the game and make observations about the emergent language in each case. To the best of our knowledge this is the first work that explores emergence of language for discovering and implementing strategies in a setting where agents are connected via an underlying network.
Deep Discriminative Learning for Unsupervised Domain Adaptation
Nov 17, 2018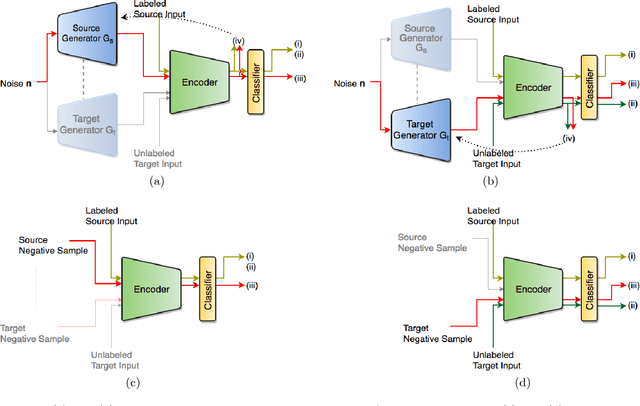
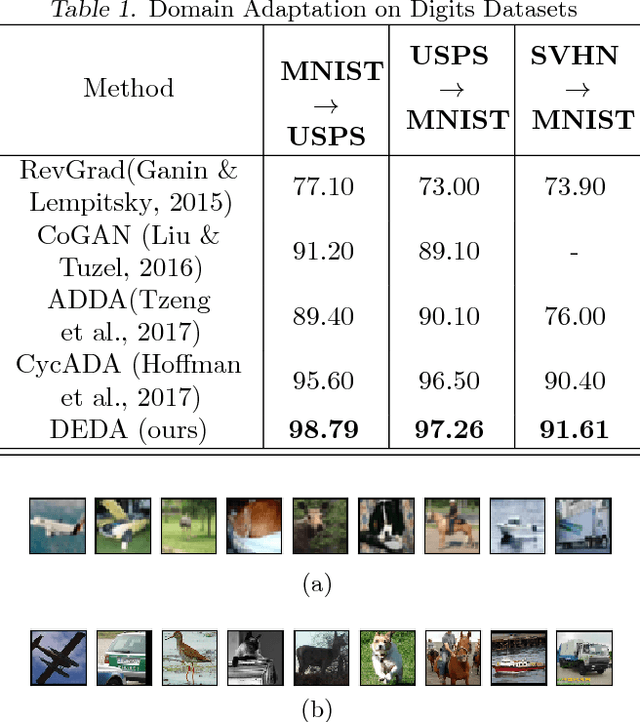

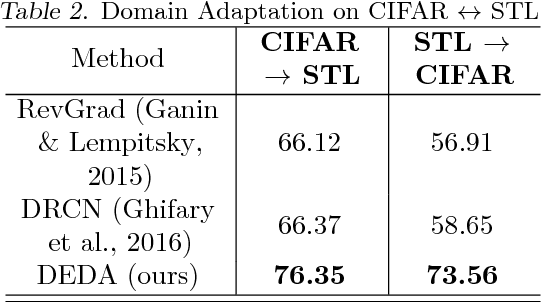
The primary objective of domain adaptation methods is to transfer knowledge from a source domain to a target domain that has similar but different data distributions. Thus, in order to correctly classify the unlabeled target domain samples, the standard approach is to learn a common representation for both source and target domain, thereby indirectly addressing the problem of learning a classifier in the target domain. However, such an approach does not address the task of classification in the target domain directly. In contrast, we propose an approach that directly addresses the problem of learning a classifier in the unlabeled target domain. In particular, we train a classifier to correctly classify the training samples while simultaneously classifying the samples in the target domain in an unsupervised manner. The corresponding model is referred to as Discriminative Encoding for Domain Adaptation (DEDA). We show that this simple approach for performing unsupervised domain adaptation is indeed quite powerful. Our method achieves state of the art results in unsupervised adaptation tasks on various image classification benchmarks. We also obtained state of the art performance on domain adaptation in Amazon reviews sentiment classification dataset. We perform additional experiments when the source data has less labeled examples and also on zero-shot domain adaptation task where no target domain samples are used for training.
On Consistency of Compressive Spectral Clustering
May 29, 2018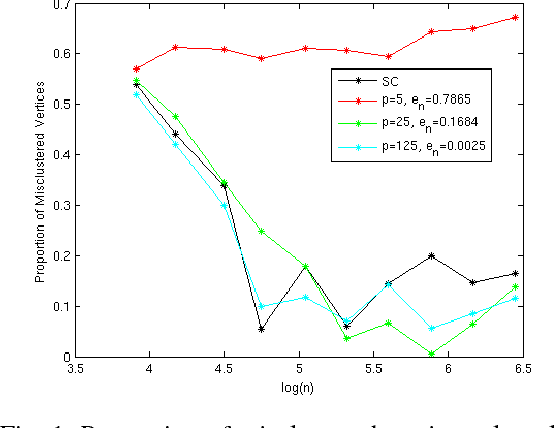
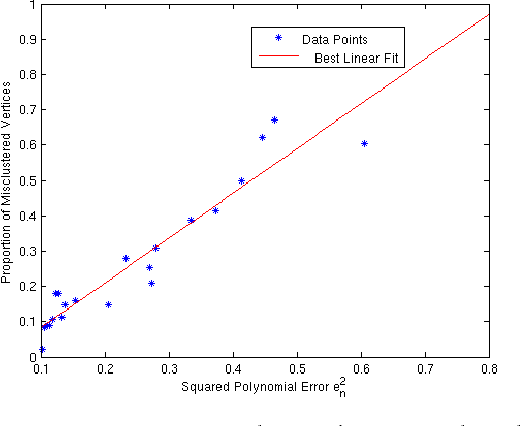
Spectral clustering is one of the most popular methods for community detection in graphs. A key step in spectral clustering algorithms is the eigen decomposition of the $n{\times}n$ graph Laplacian matrix to extract its $k$ leading eigenvectors, where $k$ is the desired number of clusters among $n$ objects. This is prohibitively complex to implement for very large datasets. However, it has recently been shown that it is possible to bypass the eigen decomposition by computing an approximate spectral embedding through graph filtering of random signals. In this paper, we analyze the working of spectral clustering performed via graph filtering on the stochastic block model. Specifically, we characterize the effects of sparsity, dimensionality and filter approximation error on the consistency of the algorithm in recovering planted clusters.
* Accepted for publication at the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, Colorado, USA
Learning beyond datasets: Knowledge Graph Augmented Neural Networks for Natural language Processing
May 21, 2018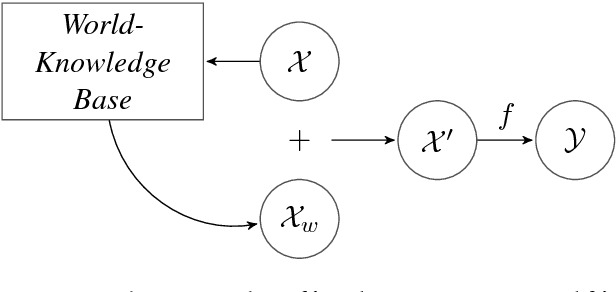
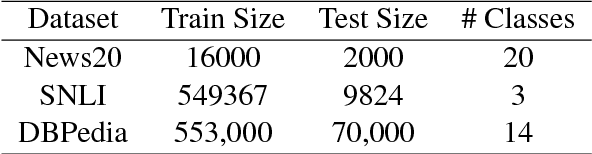
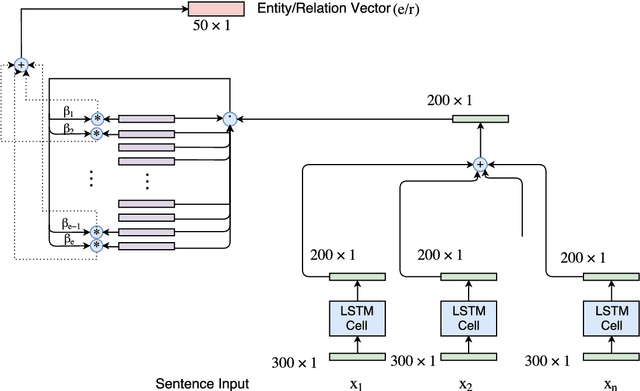
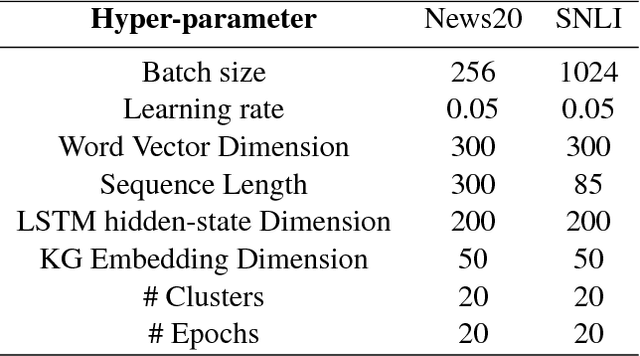
Machine Learning has been the quintessential solution for many AI problems, but learning is still heavily dependent on the specific training data. Some learning models can be incorporated with a prior knowledge in the Bayesian set up, but these learning models do not have the ability to access any organised world knowledge on demand. In this work, we propose to enhance learning models with world knowledge in the form of Knowledge Graph (KG) fact triples for Natural Language Processing (NLP) tasks. Our aim is to develop a deep learning model that can extract relevant prior support facts from knowledge graphs depending on the task using attention mechanism. We introduce a convolution-based model for learning representations of knowledge graph entity and relation clusters in order to reduce the attention space. We show that the proposed method is highly scalable to the amount of prior information that has to be processed and can be applied to any generic NLP task. Using this method we show significant improvement in performance for text classification with News20, DBPedia datasets and natural language inference with Stanford Natural Language Inference (SNLI) dataset. We also demonstrate that a deep learning model can be trained well with substantially less amount of labeled training data, when it has access to organised world knowledge in the form of knowledge graph.
Instance-based Inductive Deep Transfer Learning by Cross-Dataset Querying with Locality Sensitive Hashing
Feb 16, 2018
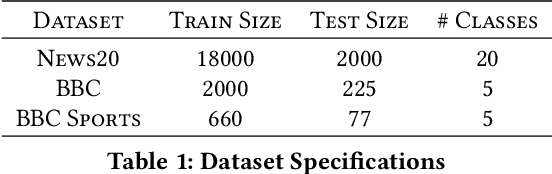
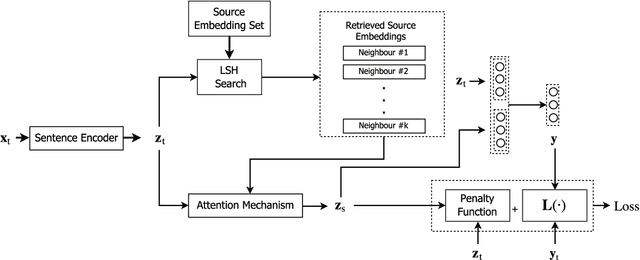
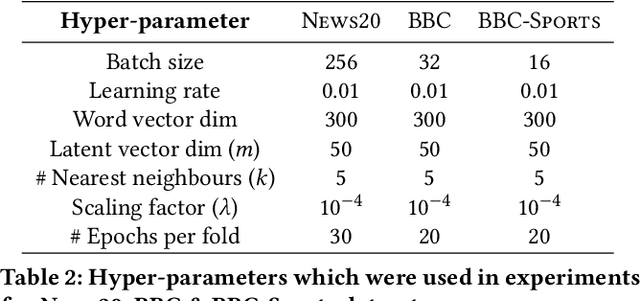
Supervised learning models are typically trained on a single dataset and the performance of these models rely heavily on the size of the dataset, i.e., amount of data available with the ground truth. Learning algorithms try to generalize solely based on the data that is presented with during the training. In this work, we propose an inductive transfer learning method that can augment learning models by infusing similar instances from different learning tasks in the Natural Language Processing (NLP) domain. We propose to use instance representations from a source dataset, \textit{without inheriting anything} from the source learning model. Representations of the instances of \textit{source} \& \textit{target} datasets are learned, retrieval of relevant source instances is performed using soft-attention mechanism and \textit{locality sensitive hashing}, and then, augmented into the model during training on the target dataset. Our approach simultaneously exploits the local \textit{instance level information} as well as the macro statistical viewpoint of the dataset. Using this approach we have shown significant improvements for three major news classification datasets over the baseline. Experimental evaluations also show that the proposed approach reduces dependency on labeled data by a significant margin for comparable performance. With our proposed cross dataset learning procedure we show that one can achieve competitive/better performance than learning from a single dataset.