 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning beyond datasets: Knowledge Graph Augmented Neural Networks for Natural language Processing
May 21, 2018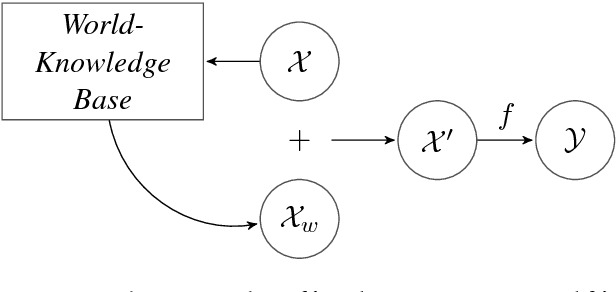
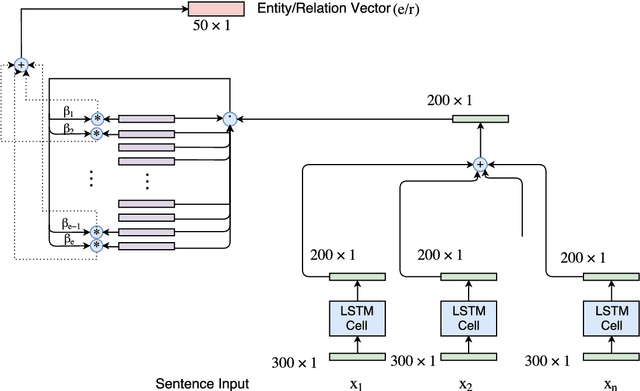
Machine Learning has been the quintessential solution for many AI problems, but learning is still heavily dependent on the specific training data. Some learning models can be incorporated with a prior knowledge in the Bayesian set up, but these learning models do not have the ability to access any organised world knowledge on demand. In this work, we propose to enhance learning models with world knowledge in the form of Knowledge Graph (KG) fact triples for Natural Language Processing (NLP) tasks. Our aim is to develop a deep learning model that can extract relevant prior support facts from knowledge graphs depending on the task using attention mechanism. We introduce a convolution-based model for learning representations of knowledge graph entity and relation clusters in order to reduce the attention space. We show that the proposed method is highly scalable to the amount of prior information that has to be processed and can be applied to any generic NLP task. Using this method we show significant improvement in performance for text classification with News20, DBPedia datasets and natural language inference with Stanford Natural Language Inference (SNLI) dataset. We also demonstrate that a deep learning model can be trained well with substantially less amount of labeled training data, when it has access to organised world knowledge in the form of knowledge graph.
Instance-based Inductive Deep Transfer Learning by Cross-Dataset Querying with Locality Sensitive Hashing
Feb 16, 2018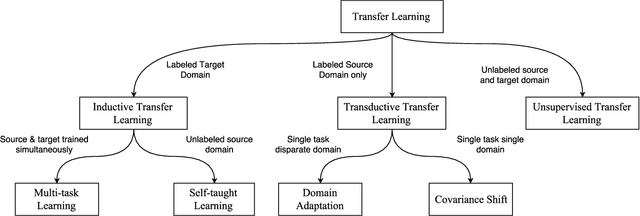
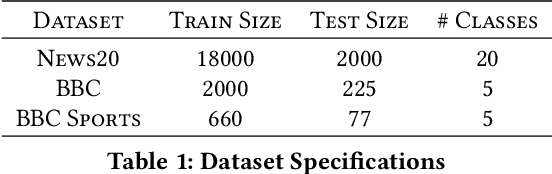
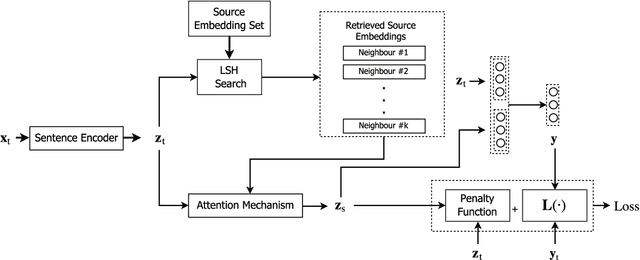
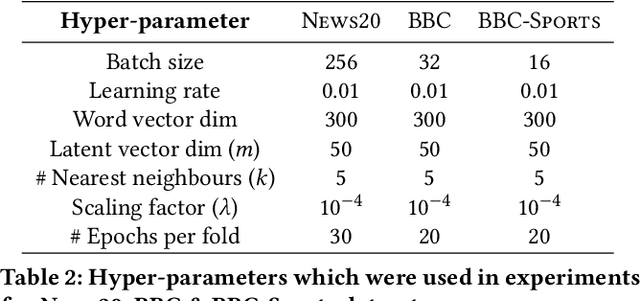
Supervised learning models are typically trained on a single dataset and the performance of these models rely heavily on the size of the dataset, i.e., amount of data available with the ground truth. Learning algorithms try to generalize solely based on the data that is presented with during the training. In this work, we propose an inductive transfer learning method that can augment learning models by infusing similar instances from different learning tasks in the Natural Language Processing (NLP) domain. We propose to use instance representations from a source dataset, \textit{without inheriting anything} from the source learning model. Representations of the instances of \textit{source} \& \textit{target} datasets are learned, retrieval of relevant source instances is performed using soft-attention mechanism and \textit{locality sensitive hashing}, and then, augmented into the model during training on the target dataset. Our approach simultaneously exploits the local \textit{instance level information} as well as the macro statistical viewpoint of the dataset. Using this approach we have shown significant improvements for three major news classification datasets over the baseline. Experimental evaluations also show that the proposed approach reduces dependency on labeled data by a significant margin for comparable performance. With our proposed cross dataset learning procedure we show that one can achieve competitive/better performance than learning from a single dataset.