 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Visual Question Answering by Visual Grounding from Attention Supervision Mining
Aug 01, 2018



A key aspect of VQA models that are interpretable is their ability to ground their answers to relevant regions in the image. Current approaches with this capability rely on supervised learning and human annotated groundings to train attention mechanisms inside the VQA architecture. Unfortunately, obtaining human annotations specific for visual grounding is difficult and expensive. In this work, we demonstrate that we can effectively train a VQA architecture with grounding supervision that can be automatically obtained from available region descriptions and object annotations. We also show that our model trained with this mined supervision generates visual groundings that achieve a higher correlation with respect to manually-annotated groundings, meanwhile achieving state-of-the-art VQA accuracy.
A Deep Learning Based Behavioral Approach to Indoor Autonomous Navigation
Mar 12, 2018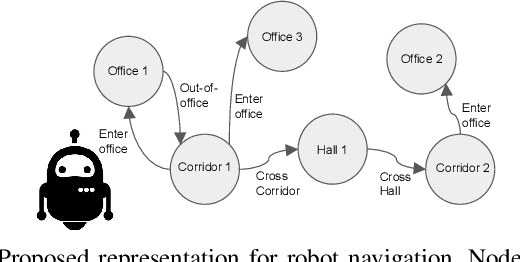
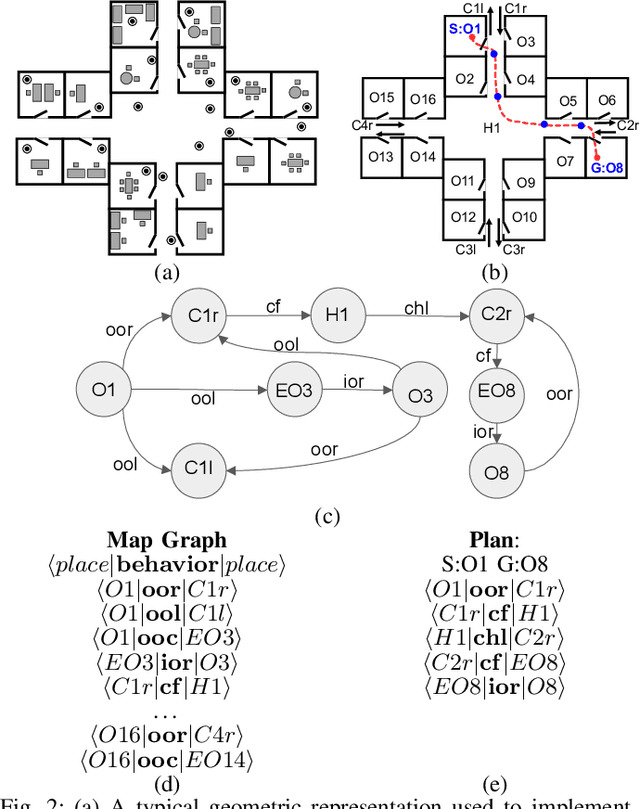

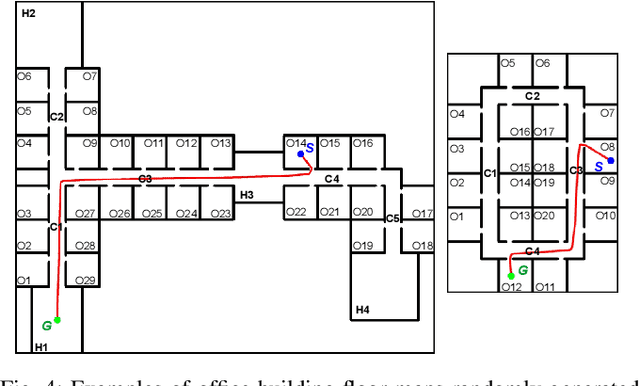
We present a semantically rich graph representation for indoor robotic navigation. Our graph representation encodes: semantic locations such as offices or corridors as nodes, and navigational behaviors such as enter office or cross a corridor as edges. In particular, our navigational behaviors operate directly from visual inputs to produce motor controls and are implemented with deep learning architectures. This enables the robot to avoid explicit computation of its precise location or the geometry of the environment, and enables navigation at a higher level of semantic abstraction. We evaluate the effectiveness of our representation by simulating navigation tasks in a large number of virtual environments. Our results show that using a simple sets of perceptual and navigational behaviors, the proposed approach can successfully guide the way of the robot as it completes navigational missions such as going to a specific office. Furthermore, our implementation shows to be effective to control the selection and switching of behaviors.
Exploring Content-based Artwork Recommendation with Metadata and Visual Features
Oct 23, 2017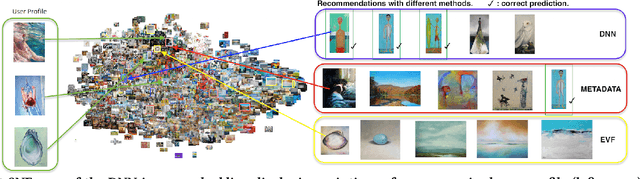
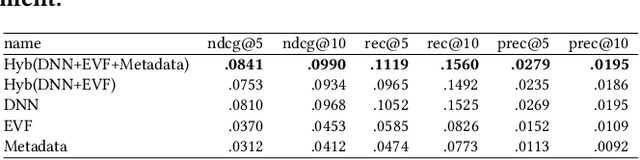
Compared to other areas, artwork recommendation has received little attention, despite the continuous growth of the artwork market. Previous research has relied on ratings and metadata to make artwork recommendations, as well as visual features extracted with deep neural networks (DNN). However, these features have no direct interpretation to explicit visual features (e.g. brightness, texture) which might hinder explainability and user-acceptance. In this work, we study the impact of artwork metadata as well as visual features (DNN-based and attractiveness-based) for physical artwork recommendation, using images and transaction data from the UGallery online artwork store. Our results indicate that: (i) visual features perform better than manually curated data, (ii) DNN-based visual features perform better than attractiveness-based ones, and (iii) a hybrid approach improves the performance further. Our research can inform the development of new artwork recommenders relying on diverse content data.
Comparing Neural and Attractiveness-based Visual Features for Artwork Recommendation
Jul 21, 2017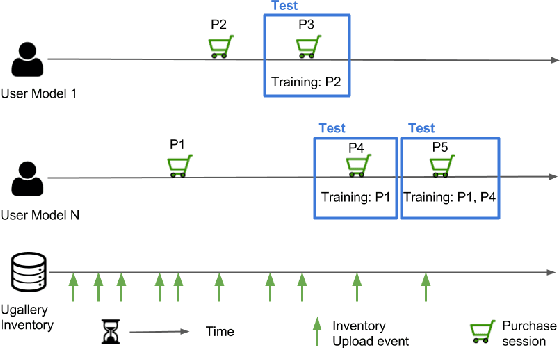
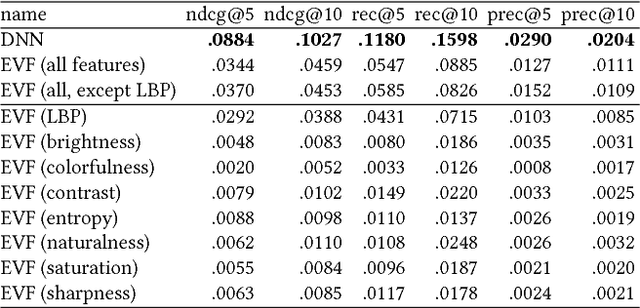

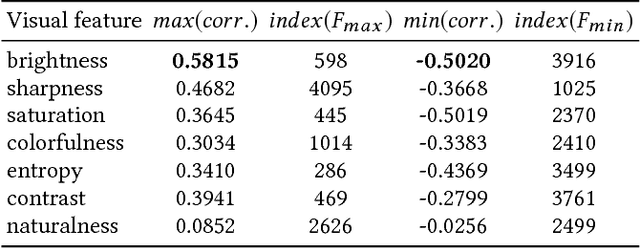
Advances in image processing and computer vision in the latest years have brought about the use of visual features in artwork recommendation. Recent works have shown that visual features obtained from pre-trained deep neural networks (DNNs) perform very well for recommending digital art. Other recent works have shown that explicit visual features (EVF) based on attractiveness can perform well in preference prediction tasks, but no previous work has compared DNN features versus specific attractiveness-based visual features (e.g. brightness, texture) in terms of recommendation performance. In this work, we study and compare the performance of DNN and EVF features for the purpose of physical artwork recommendation using transactional data from UGallery, an online store of physical paintings. In addition, we perform an exploratory analysis to understand if DNN embedded features have some relation with certain EVF. Our results show that DNN features outperform EVF, that certain EVF features are more suited for physical artwork recommendation and, finally, we show evidence that certain neurons in the DNN might be partially encoding visual features such as brightness, providing an opportunity for explaining recommendations based on visual neural models.
How a General-Purpose Commonsense Ontology can Improve Performance of Learning-Based Image Retrieval
May 24, 2017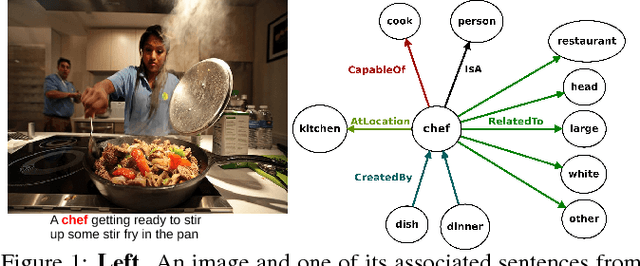
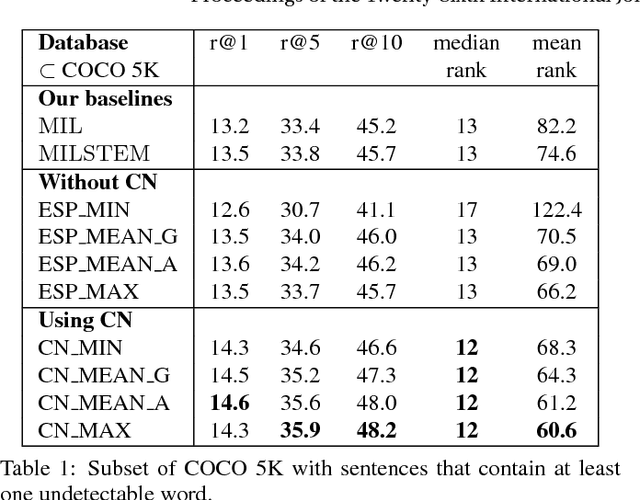

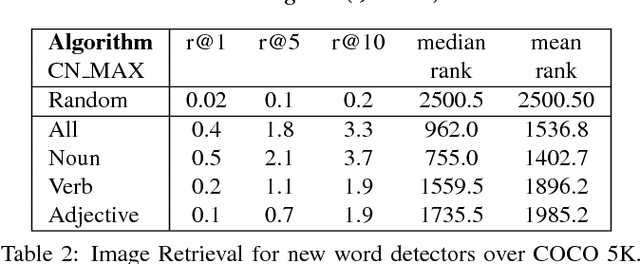
The knowledge representation community has built general-purpose ontologies which contain large amounts of commonsense knowledge over relevant aspects of the world, including useful visual information, e.g.: "a ball is used by a football player", "a tennis player is located at a tennis court". Current state-of-the-art approaches for visual recognition do not exploit these rule-based knowledge sources. Instead, they learn recognition models directly from training examples. In this paper, we study how general-purpose ontologies---specifically, MIT's ConceptNet ontology---can improve the performance of state-of-the-art vision systems. As a testbed, we tackle the problem of sentence-based image retrieval. Our retrieval approach incorporates knowledge from ConceptNet on top of a large pool of object detectors derived from a deep learning technique. In our experiments, we show that ConceptNet can improve performance on a common benchmark dataset. Key to our performance is the use of the ESPGAME dataset to select visually relevant relations from ConceptNet. Consequently, a main conclusion of this work is that general-purpose commonsense ontologies improve performance on visual reasoning tasks when properly filtered to select meaningful visual relations.
A Hierarchical Pose-Based Approach to Complex Action Understanding Using Dictionaries of Actionlets and Motion Poselets
Jun 15, 2016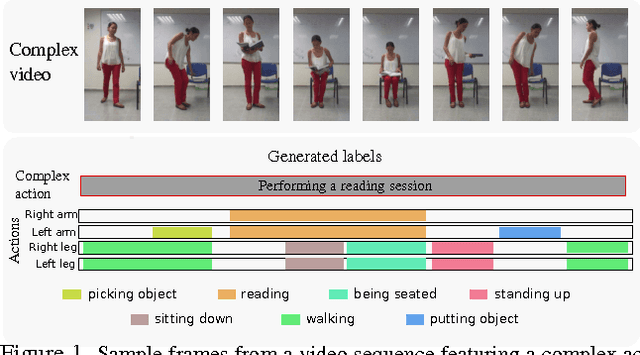

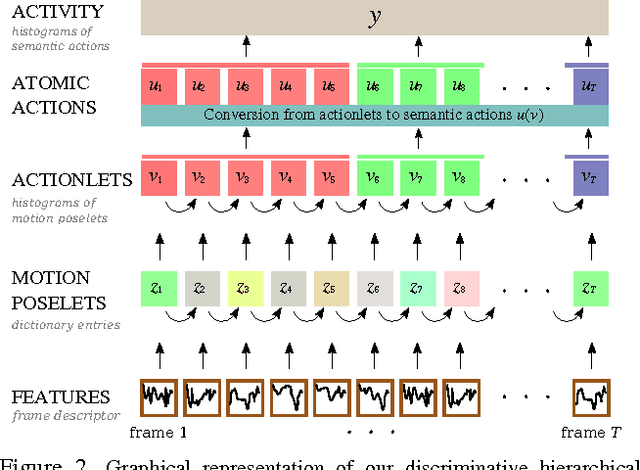
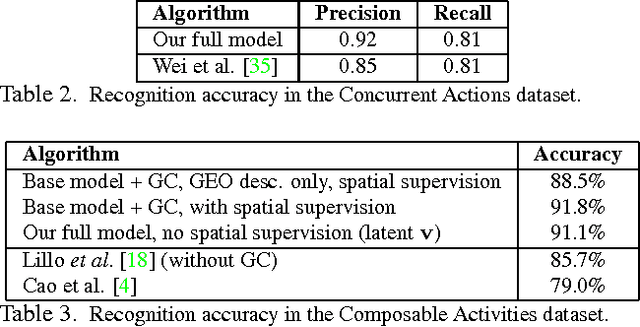
In this paper, we introduce a new hierarchical model for human action recognition using body joint locations. Our model can categorize complex actions in videos, and perform spatio-temporal annotations of the atomic actions that compose the complex action being performed.That is, for each atomic action, the model generates temporal action annotations by estimating its starting and ending times, as well as, spatial annotations by inferring the human body parts that are involved in executing the action. our model includes three key novel properties: (i) it can be trained with no spatial supervision, as it can automatically discover active body parts from temporal action annotations only; (ii) it jointly learns flexible representations for motion poselets and actionlets that encode the visual variability of body parts and atomic actions; (iii) a mechanism to discard idle or non-informative body parts which increases its robustness to common pose estimation errors. We evaluate the performance of our method using multiple action recognition benchmarks. Our model consistently outperforms baselines and state-of-the-art action recognition methods.
Action Recognition in Video Using Sparse Coding and Relative Features
May 10, 2016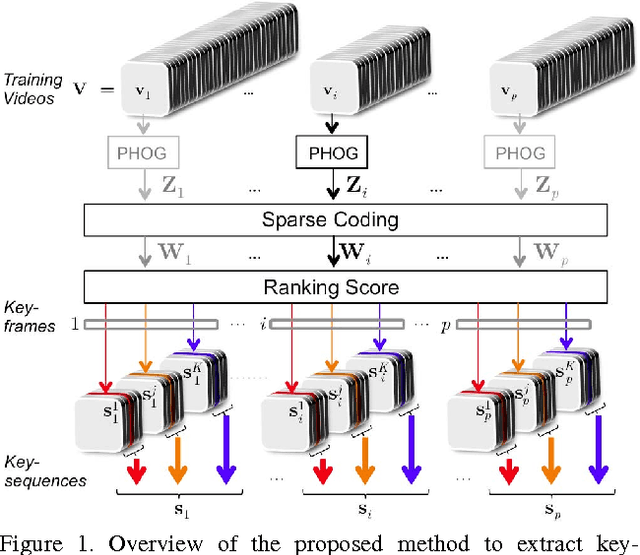

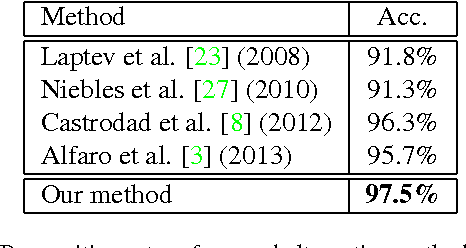
This work presents an approach to category-based action recognition in video using sparse coding techniques. The proposed approach includes two main contributions: i) A new method to handle intra-class variations by decomposing each video into a reduced set of representative atomic action acts or key-sequences, and ii) A new video descriptor, ITRA: Inter-Temporal Relational Act Descriptor, that exploits the power of comparative reasoning to capture relative similarity relations among key-sequences. In terms of the method to obtain key-sequences, we introduce a loss function that, for each video, leads to the identification of a sparse set of representative key-frames capturing both, relevant particularities arising in the input video, as well as relevant generalities arising in the complete class collection. In terms of the method to obtain the ITRA descriptor, we introduce a novel scheme to quantify relative intra and inter-class similarities among local temporal patterns arising in the videos. The resulting ITRA descriptor demonstrates to be highly effective to discriminate among action categories. As a result, the proposed approach reaches remarkable action recognition performance on several popular benchmark datasets, outperforming alternative state-of-the-art techniques by a large margin.