 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Follow Me? Testing Situational Understanding in ChatGPT
Oct 24, 2023



Understanding sentence meanings and updating information states appropriately across time -- what we call "situational understanding" (SU) -- is a critical ability for human-like AI agents. SU is essential in particular for chat models, such as ChatGPT, to enable consistent, coherent, and effective dialogue between humans and AI. Previous works have identified certain SU limitations in non-chatbot Large Language models (LLMs), but the extent and causes of these limitations are not well understood, and capabilities of current chat-based models in this domain have not been explored. In this work we tackle these questions, proposing a novel synthetic environment for SU testing which allows us to do controlled and systematic testing of SU in chat-oriented models, through assessment of models' ability to track and enumerate environment states. Our environment also allows for close analysis of dynamics of model performance, to better understand underlying causes for performance patterns. We apply our test to ChatGPT, the state-of-the-art chatbot, and find that despite the fundamental simplicity of the task, the model's performance reflects an inability to retain correct environment states across time. Our follow-up analyses suggest that performance degradation is largely because ChatGPT has non-persistent in-context memory (although it can access the full dialogue history) and it is susceptible to hallucinated updates -- including updates that artificially inflate accuracies. Our findings suggest overall that ChatGPT is not currently equipped for robust tracking of situation states, and that trust in the impressive dialogue performance of ChatGPT comes with risks. We release the codebase for reproducing our test environment, as well as all prompts and API responses from ChatGPT, at https://github.com/yangalan123/SituationalTesting.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.
Counterfactual reasoning: Testing language models' understanding of hypothetical scenarios
May 26, 2023Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on the understanding of real world. We tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from five pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
Counterfactual reasoning: Do language models need world knowledge for causal understanding?
Dec 06, 2022Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on understanding of the real world. In this paper we tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests drawn from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from a variety of popular pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
COMPS: Conceptual Minimal Pair Sentences for testing Property Knowledge and Inheritance in Pre-trained Language Models
Oct 06, 2022
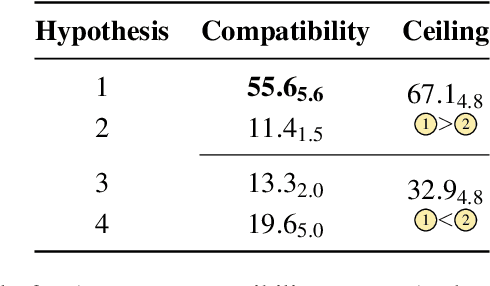

A characteristic feature of human semantic memory is its ability to not only store and retrieve the properties of concepts observed through experience, but to also facilitate the inheritance of properties (can breathe) from superordinate concepts (animal) to their subordinates (dog) -- i.e. demonstrate property inheritance. In this paper, we present COMPS, a collection of minimal pair sentences that jointly tests pre-trained language models (PLMs) on their ability to attribute properties to concepts and their ability to demonstrate property inheritance behavior. Analyses of 22 different PLMs on COMPS reveal that they can easily distinguish between concepts on the basis of a property when they are trivially different, but find it relatively difficult when concepts are related on the basis of nuanced knowledge representations. Furthermore, we find that PLMs can demonstrate behavior consistent with property inheritance to a great extent, but fail in the presence of distracting information, which decreases the performance of many models, sometimes even below chance. This lack of robustness in demonstrating simple reasoning raises important questions about PLMs' capacity to make correct inferences even when they appear to possess the prerequisite knowledge.
"No, they did not": Dialogue response dynamics in pre-trained language models
Oct 05, 2022

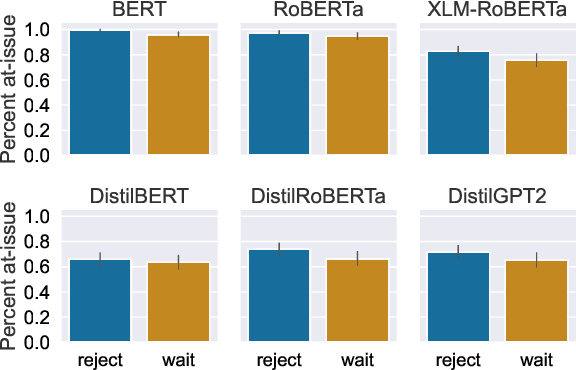
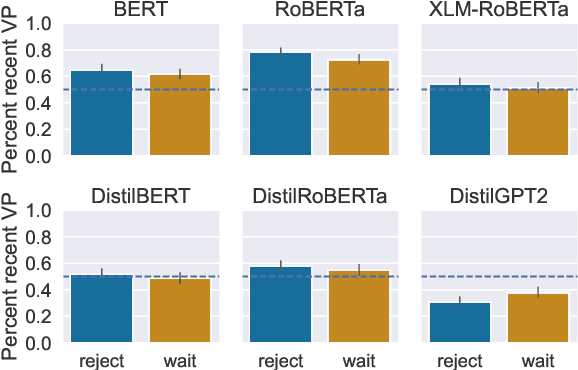
A critical component of competence in language is being able to identify relevant components of an utterance and reply appropriately. In this paper we examine the extent of such dialogue response sensitivity in pre-trained language models, conducting a series of experiments with a particular focus on sensitivity to dynamics involving phenomena of at-issueness and ellipsis. We find that models show clear sensitivity to a distinctive role of embedded clauses, and a general preference for responses that target main clause content of prior utterances. However, the results indicate mixed and generally weak trends with respect to capturing the full range of dynamics involved in targeting at-issue versus not-at-issue content. Additionally, models show fundamental limitations in grasp of the dynamics governing ellipsis, and response selections show clear interference from superficial factors that outweigh the influence of principled discourse constraints.
A Property Induction Framework for Neural Language Models
May 13, 2022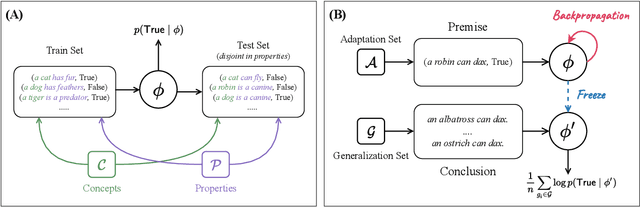
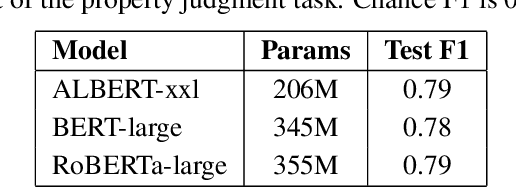
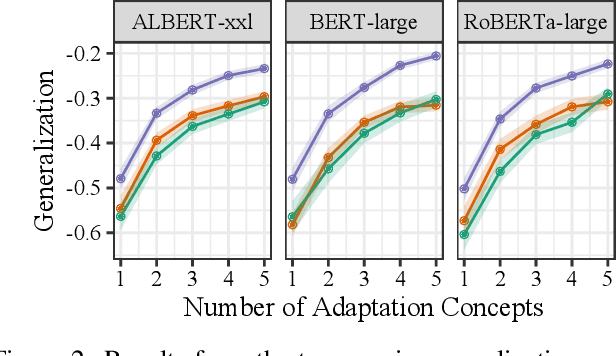
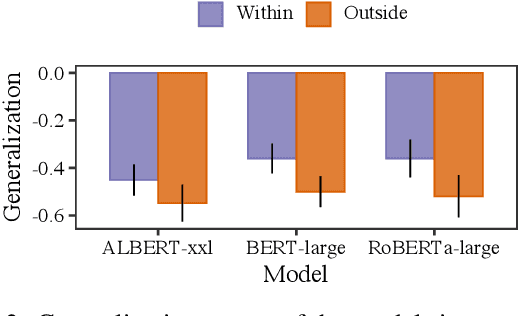
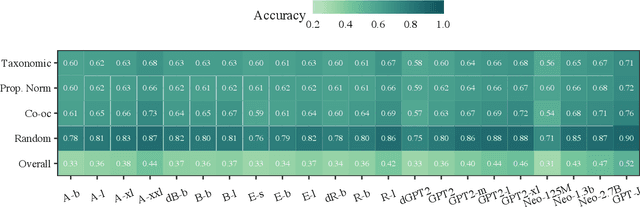
To what extent can experience from language contribute to our conceptual knowledge? Computational explorations of this question have shed light on the ability of powerful neural language models (LMs) -- informed solely through text input -- to encode and elicit information about concepts and properties. To extend this line of research, we present a framework that uses neural-network language models (LMs) to perform property induction -- a task in which humans generalize novel property knowledge (has sesamoid bones) from one or more concepts (robins) to others (sparrows, canaries). Patterns of property induction observed in humans have shed considerable light on the nature and organization of human conceptual knowledge. Inspired by this insight, we use our framework to explore the property inductions of LMs, and find that they show an inductive preference to generalize novel properties on the basis of category membership, suggesting the presence of a taxonomic bias in their representations.
Variation and generality in encoding of syntactic anomaly information in sentence embeddings
Nov 12, 2021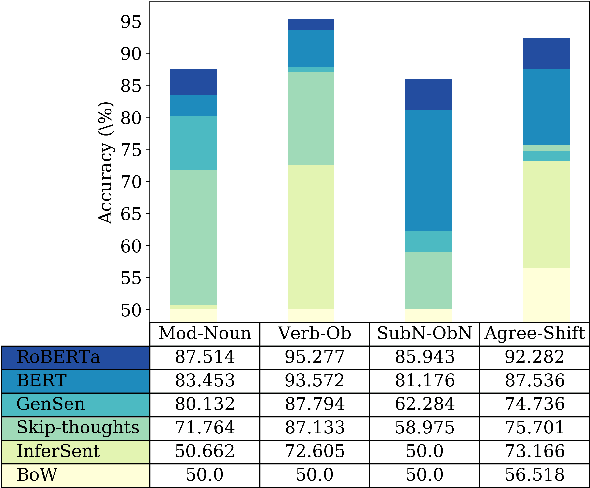

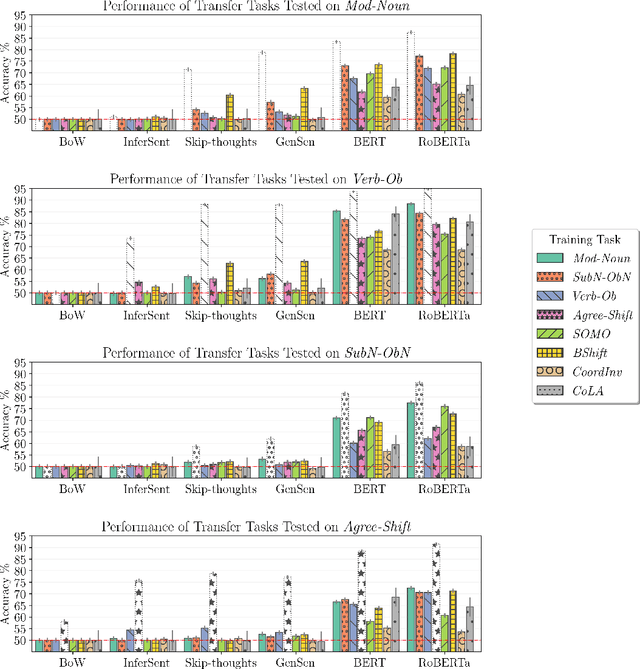

While sentence anomalies have been applied periodically for testing in NLP, we have yet to establish a picture of the precise status of anomaly information in representations from NLP models. In this paper we aim to fill two primary gaps, focusing on the domain of syntactic anomalies. First, we explore fine-grained differences in anomaly encoding by designing probing tasks that vary the hierarchical level at which anomalies occur in a sentence. Second, we test not only models' ability to detect a given anomaly, but also the generality of the detected anomaly signal, by examining transfer between distinct anomaly types. Results suggest that all models encode some information supporting anomaly detection, but detection performance varies between anomalies, and only representations from more recent transformer models show signs of generalized knowledge of anomalies. Follow-up analyses support the notion that these models pick up on a legitimate, general notion of sentence oddity, while coarser-grained word position information is likely also a contributor to the observed anomaly detection.
Pragmatic competence of pre-trained language models through the lens of discourse connectives
Sep 27, 2021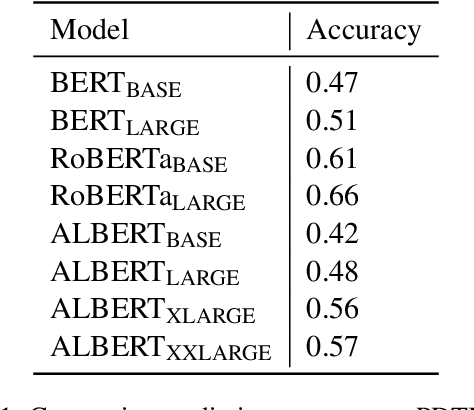
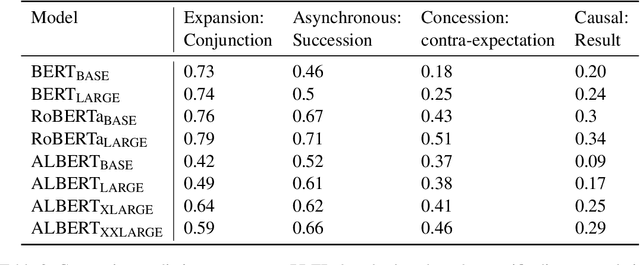

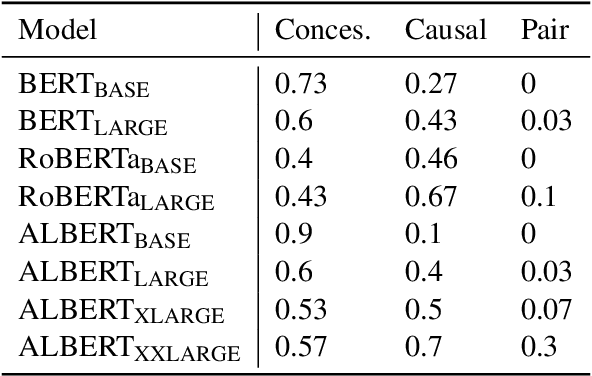
As pre-trained language models (LMs) continue to dominate NLP, it is increasingly important that we understand the depth of language capabilities in these models. In this paper, we target pre-trained LMs' competence in pragmatics, with a focus on pragmatics relating to discourse connectives. We formulate cloze-style tests using a combination of naturally-occurring data and controlled inputs drawn from psycholinguistics. We focus on testing models' ability to use pragmatic cues to predict discourse connectives, models' ability to understand implicatures relating to connectives, and the extent to which models show humanlike preferences regarding temporal dynamics of connectives. We find that although models predict connectives reasonably well in the context of naturally-occurring data, when we control contexts to isolate high-level pragmatic cues, model sensitivity is much lower. Models also do not show substantial humanlike temporal preferences. Overall, the findings suggest that at present, dominant pre-training paradigms do not result in substantial pragmatic competence in our models.
Sorting through the noise: Testing robustness of information processing in pre-trained language models
Sep 25, 2021
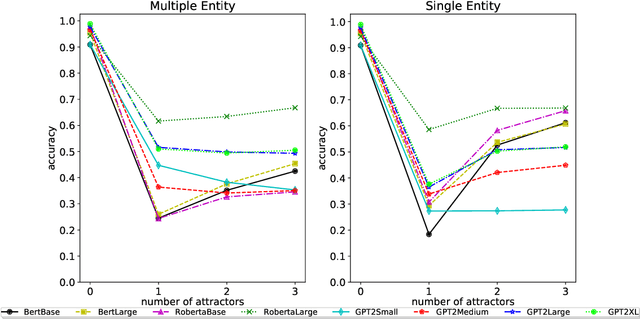
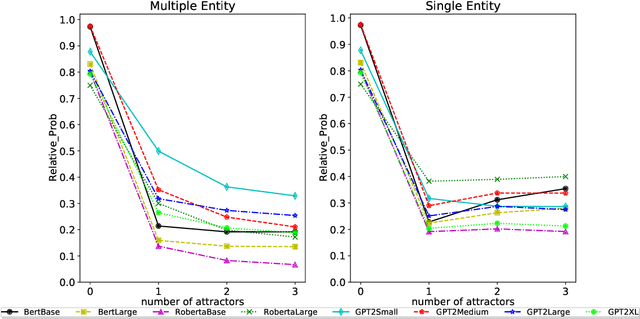
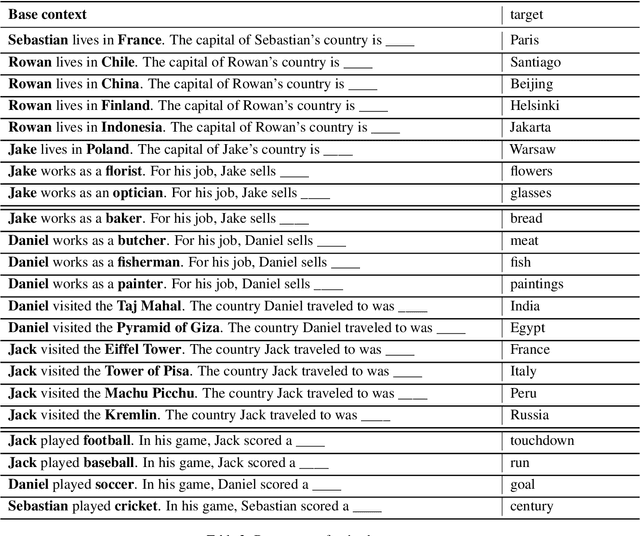
Pre-trained LMs have shown impressive performance on downstream NLP tasks, but we have yet to establish a clear understanding of their sophistication when it comes to processing, retaining, and applying information presented in their input. In this paper we tackle a component of this question by examining robustness of models' ability to deploy relevant context information in the face of distracting content. We present models with cloze tasks requiring use of critical context information, and introduce distracting content to test how robustly the models retain and use that critical information for prediction. We also systematically manipulate the nature of these distractors, to shed light on dynamics of models' use of contextual cues. We find that although models appear in simple contexts to make predictions based on understanding and applying relevant facts from prior context, the presence of distracting but irrelevant content has clear impact in confusing model predictions. In particular, models appear particularly susceptible to factors of semantic similarity and word position. The findings are consistent with the conclusion that LM predictions are driven in large part by superficial contextual cues, rather than by robust representations of context meaning.