 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models
Jul 22, 2024



We formalize the problem of prompt compression for large language models (LLMs) and present a framework to unify token-level prompt compression methods which create hard prompts for black-box models. We derive the distortion-rate function for this setup as a linear program, and provide an efficient algorithm to compute this fundamental limit via the dual of the linear program. Using the distortion-rate function as the baseline, we study the performance of existing compression schemes on a synthetic dataset consisting of prompts generated from a Markov chain, natural language queries, and their respective answers. Our empirical analysis demonstrates the criticality of query-aware prompt compression, where the compressor has knowledge of the downstream task/query for the black-box LLM. We show that there is a large gap between the performance of current prompt compression methods and the optimal strategy, and propose a query-aware, variable-rate adaptation of a prior work to close the gap. We extend our experiments to a small natural language dataset to further confirm our findings on our synthetic dataset.
Local to Global: Learning Dynamics and Effect of Initialization for Transformers
Jun 05, 2024



In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of transformer parameters and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: \url{https://anonymous.4open.science/r/Local-to-Global-C70B/}.
Attention with Markov: A Framework for Principled Analysis of Transformers via Markov Chains
Feb 06, 2024



In recent years, attention-based transformers have achieved tremendous success across a variety of disciplines including natural languages. A key ingredient behind their success is the generative pretraining procedure, during which these models are trained on a large text corpus in an auto-regressive manner. To shed light on this phenomenon, we propose a new framework that allows both theory and systematic experiments to study the sequential modeling capabilities of transformers through the lens of Markov chains. Inspired by the Markovianity of natural languages, we model the data as a Markovian source and utilize this framework to systematically study the interplay between the data-distributional properties, the transformer architecture, the learnt distribution, and the final model performance. In particular, we theoretically characterize the loss landscape of single-layer transformers and show the existence of global minima and bad local minima contingent upon the specific data characteristics and the transformer architecture. Backed by experiments, we demonstrate that our theoretical findings are in congruence with the empirical results. We further investigate these findings in the broader context of higher order Markov chains and deeper architectures, and outline open problems in this arena. Code is available at \url{https://github.com/Bond1995/Markov}.
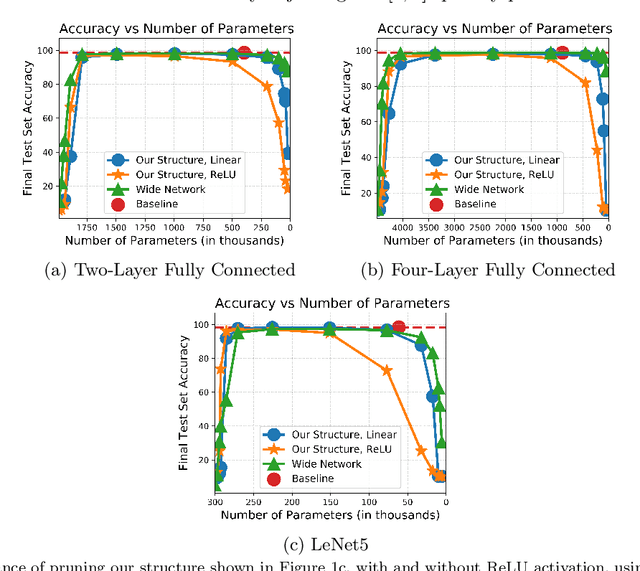
Rare Gems: Finding Lottery Tickets at Initialization
Feb 24, 2022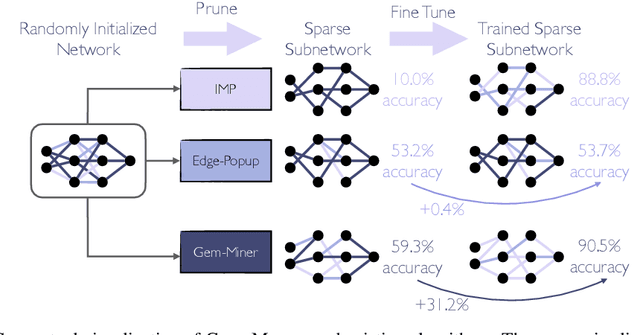

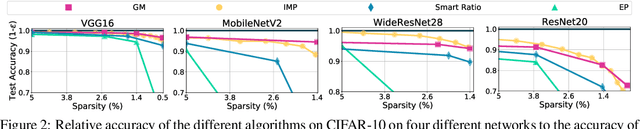

It has been widely observed that large neural networks can be pruned to a small fraction of their original size, with little loss in accuracy, by typically following a time-consuming "train, prune, re-train" approach. Frankle & Carbin (2018) conjecture that we can avoid this by training lottery tickets, i.e., special sparse subnetworks found at initialization, that can be trained to high accuracy. However, a subsequent line of work presents concrete evidence that current algorithms for finding trainable networks at initialization, fail simple baseline comparisons, e.g., against training random sparse subnetworks. Finding lottery tickets that train to better accuracy compared to simple baselines remains an open problem. In this work, we partially resolve this open problem by discovering rare gems: subnetworks at initialization that attain considerable accuracy, even before training. Refining these rare gems - "by means of fine-tuning" - beats current baselines and leads to accuracy competitive or better than magnitude pruning methods.
Optimal Lottery Tickets via SubsetSum: Logarithmic Over-Parameterization is Sufficient
Jun 14, 2020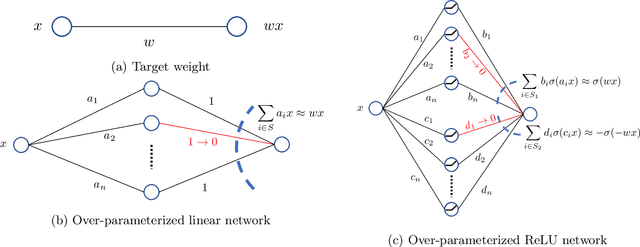
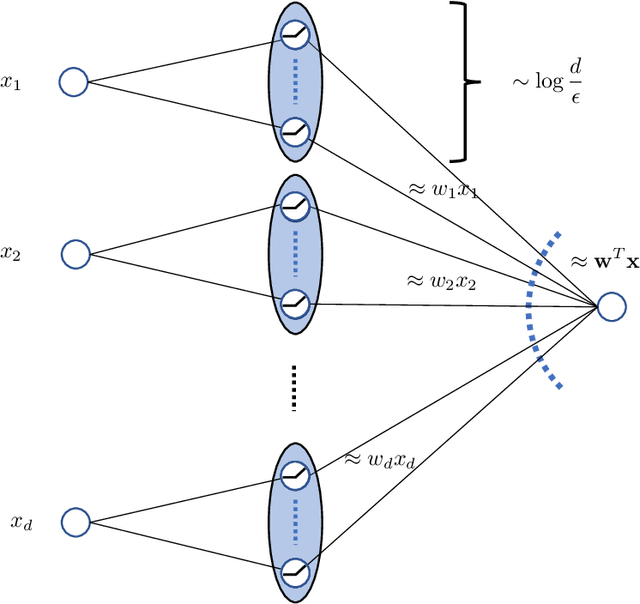
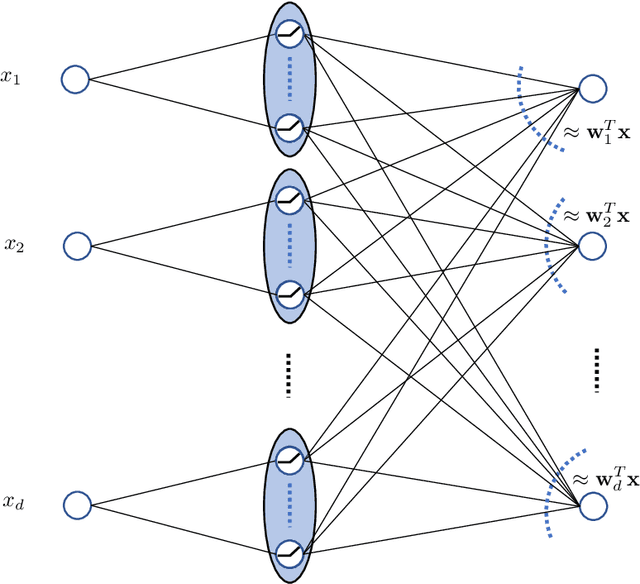
The strong {\it lottery ticket hypothesis} (LTH) postulates that one can approximate any target neural network by only pruning the weights of a sufficiently over-parameterized random network. A recent work by Malach et al.~\cite{MalachEtAl20} establishes the first theoretical analysis for the strong LTH: one can provably approximate a neural network of width $d$ and depth $l$, by pruning a random one that is a factor $O(d^4l^2)$ wider and twice as deep. This polynomial over-parameterization requirement is at odds with recent experimental research that achieves good approximation with networks that are a small factor wider than the target. In this work, we close the gap and offer an exponential improvement to the over-parameterization requirement for the existence of lottery tickets. We show that any target network of width $d$ and depth $l$ can be approximated by pruning a random network that is a factor $O(\log(dl))$ wider and twice as deep. Our analysis heavily relies on connecting pruning random ReLU networks to random instances of the \textsc{SubsetSum} problem. We then show that this logarithmic over-parameterization is essentially optimal for constant depth networks. Finally, we verify several of our theoretical insights with experiments.