 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Partial Label Learning via Dual Bipartite Graph Autoencoder
Jan 05, 2020
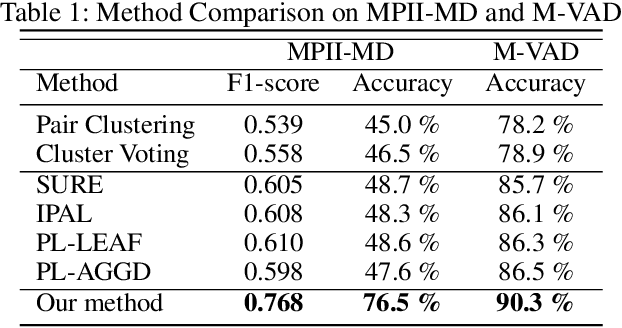
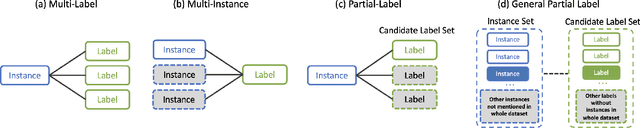
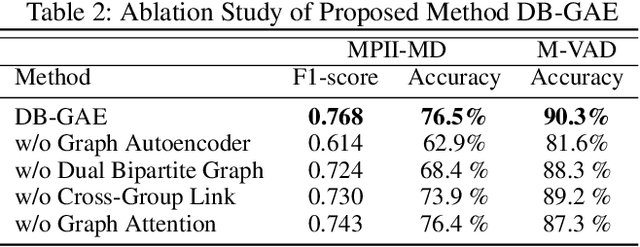
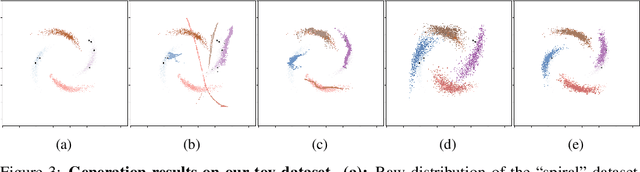
We formulate a practical yet challenging problem: General Partial Label Learning (GPLL). Compared to the traditional Partial Label Learning (PLL) problem, GPLL relaxes the supervision assumption from instance-level --- a label set partially labels an instance --- to group-level: 1) a label set partially labels a group of instances, where the within-group instance-label link annotations are missing, and 2) cross-group links are allowed --- instances in a group may be partially linked to the label set from another group. Such ambiguous group-level supervision is more practical in real-world scenarios as additional annotation on the instance-level is no longer required, e.g., face-naming in videos where the group consists of faces in a frame, labeled by a name set in the corresponding caption. In this paper, we propose a novel graph convolutional network (GCN) called Dual Bipartite Graph Autoencoder (DB-GAE) to tackle the label ambiguity challenge of GPLL. First, we exploit the cross-group correlations to represent the instance groups as dual bipartite graphs: within-group and cross-group, which reciprocally complements each other to resolve the linking ambiguities. Second, we design a GCN autoencoder to encode and decode them, where the decodings are considered as the refined results. It is worth noting that DB-GAE is self-supervised and transductive, as it only uses the group-level supervision without a separate offline training stage. Extensive experiments on two real-world datasets demonstrate that DB-GAE significantly outperforms the best baseline over absolute 0.159 F1-score and 24.8% accuracy. We further offer analysis on various levels of label ambiguities.
CDSA: Cross-Dimensional Self-Attention for Multivariate, Geo-tagged Time Series Imputation
May 23, 2019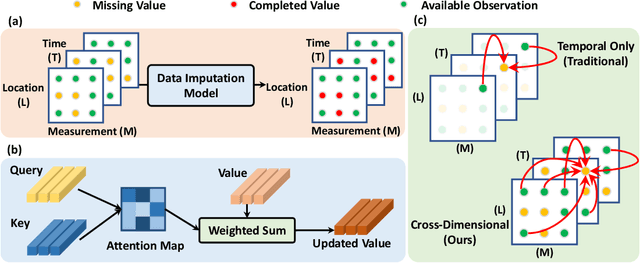

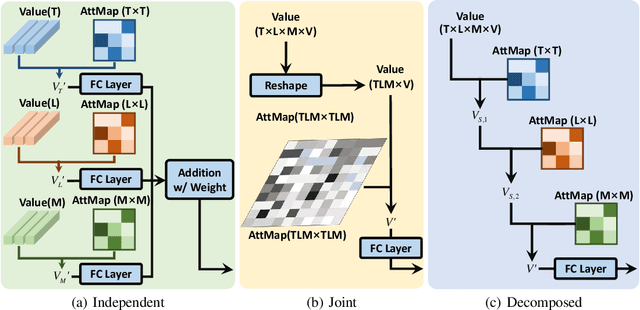
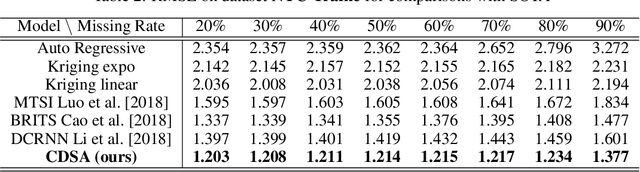
Many real-world applications involve multivariate, geo-tagged time series data: at each location, multiple sensors record corresponding measurements. For example, air quality monitoring system records PM2.5, CO, etc. The resulting time-series data often has missing values due to device outages or communication errors. In order to impute the missing values, state-of-the-art methods are built on Recurrent Neural Networks (RNN), which process each time stamp sequentially, prohibiting the direct modeling of the relationship between distant time stamps. Recently, the self-attention mechanism has been proposed for sequence modeling tasks such as machine translation, significantly outperforming RNN because the relationship between each two time stamps can be modeled explicitly. In this paper, we are the first to adapt the self-attention mechanism for multivariate, geo-tagged time series data. In order to jointly capture the self-attention across multiple dimensions, including time, location and the sensor measurements, while maintain low computational complexity, we propose a novel approach called Cross-Dimensional Self-Attention (CDSA) to process each dimension sequentially, yet in an order-independent manner. Our extensive experiments on four real-world datasets, including three standard benchmarks and our newly collected NYC-traffic dataset, demonstrate that our approach outperforms the state-of-the-art imputation and forecasting methods. A detailed systematic analysis confirms the effectiveness of our design choices.
Low-shot Learning via Covariance-Preserving Adversarial Augmentation Networks
Oct 30, 2018
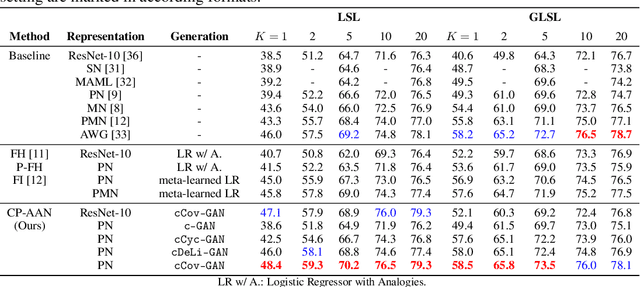
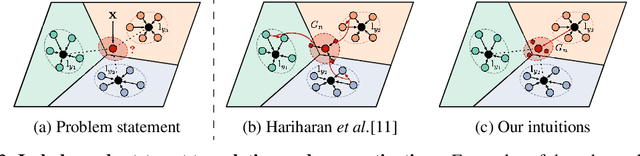
Deep neural networks suffer from over-fitting and catastrophic forgetting when trained with small data. One natural remedy for this problem is data augmentation, which has been recently shown to be effective. However, previous works either assume that intra-class variances can always be generalized to new classes, or employ naive generation methods to hallucinate finite examples without modeling their latent distributions. In this work, we propose Covariance-Preserving Adversarial Augmentation Networks to overcome existing limits of low-shot learning. Specifically, a novel Generative Adversarial Network is designed to model the latent distribution of each novel class given its related base counterparts. Since direct estimation on novel classes can be inductively biased, we explicitly preserve covariance information as the "variability" of base examples during the generation process. Empirical results show that our model can generate realistic yet diverse examples, leading to substantial improvements on the ImageNet benchmark over the state of the art.
CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos
Jun 13, 2017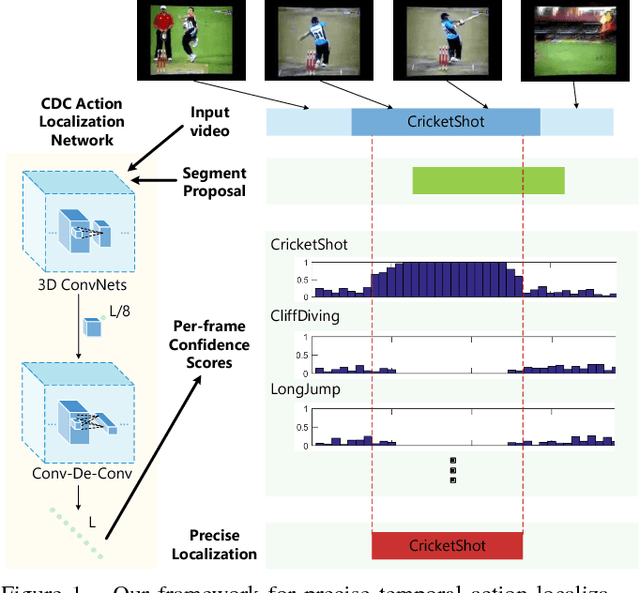
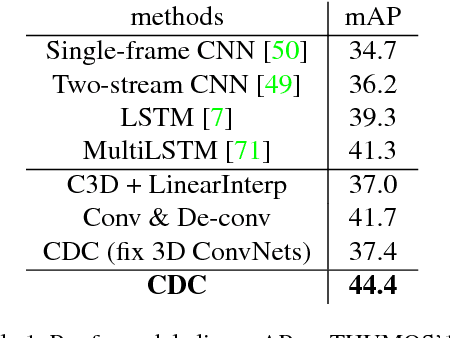
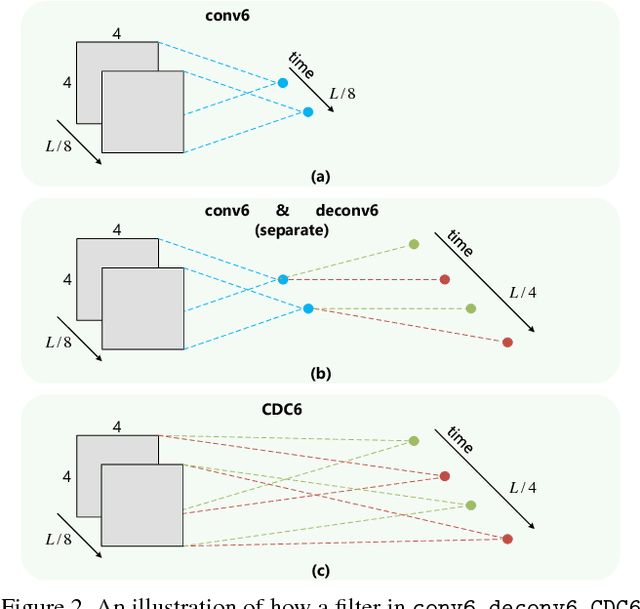
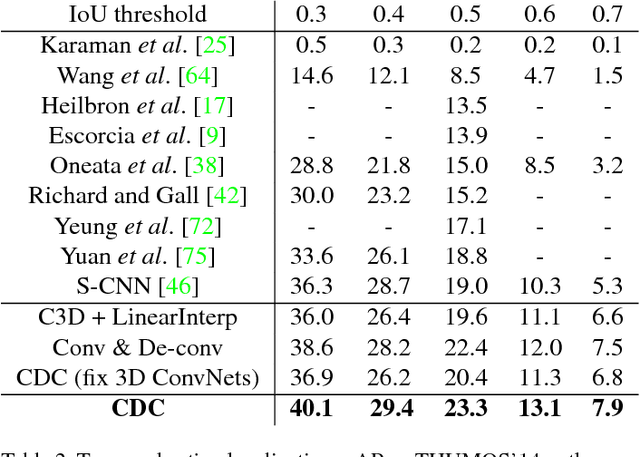
Temporal action localization is an important yet challenging problem. Given a long, untrimmed video consisting of multiple action instances and complex background contents, we need not only to recognize their action categories, but also to localize the start time and end time of each instance. Many state-of-the-art systems use segment-level classifiers to select and rank proposal segments of pre-determined boundaries. However, a desirable model should move beyond segment-level and make dense predictions at a fine granularity in time to determine precise temporal boundaries. To this end, we design a novel Convolutional-De-Convolutional (CDC) network that places CDC filters on top of 3D ConvNets, which have been shown to be effective for abstracting action semantics but reduce the temporal length of the input data. The proposed CDC filter performs the required temporal upsampling and spatial downsampling operations simultaneously to predict actions at the frame-level granularity. It is unique in jointly modeling action semantics in space-time and fine-grained temporal dynamics. We train the CDC network in an end-to-end manner efficiently. Our model not only achieves superior performance in detecting actions in every frame, but also significantly boosts the precision of localizing temporal boundaries. Finally, the CDC network demonstrates a very high efficiency with the ability to process 500 frames per second on a single GPU server. We will update the camera-ready version and publish the source codes online soon.