 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Instance Dictionary Learning using Functions of Multiple Instances
Aug 03, 2016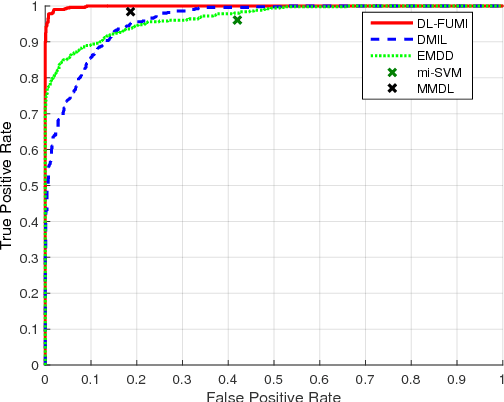

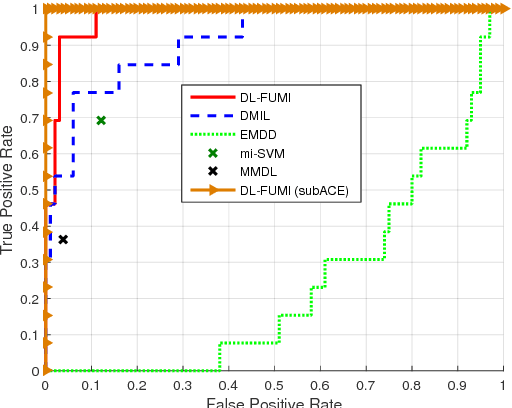

A multiple instance dictionary learning method using functions of multiple instances (DL-FUMI) is proposed to address target detection and two-class classification problems with inaccurate training labels. Given inaccurate training labels, DL-FUMI learns a set of target dictionary atoms that describe the most distinctive and representative features of the true positive class as well as a set of nontarget dictionary atoms that account for the shared information found in both the positive and negative instances. Experimental results show that the estimated target dictionary atoms found by DL-FUMI are more representative prototypes and identify better discriminative features of the true positive class than existing methods in the literature. DL-FUMI is shown to have significantly better performance on several target detection and classification problems as compared to other multiple instance learning (MIL) dictionary learning algorithms on a variety of MIL problems.
Heart Beat Characterization from Ballistocardiogram Signals using Extended Functions of Multiple Instances
May 16, 2016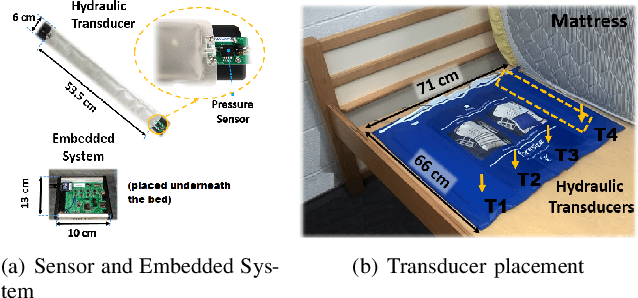
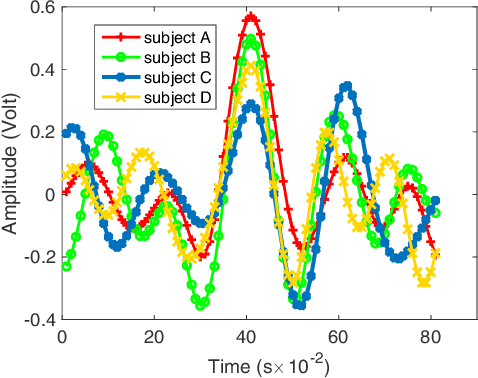
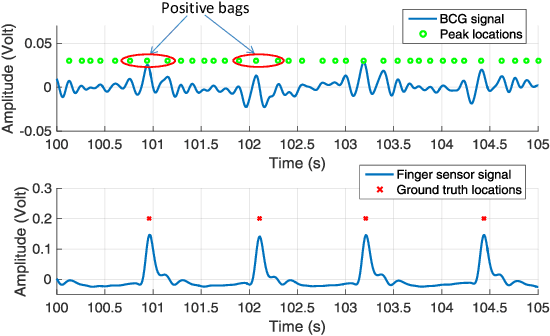
A multiple instance learning (MIL) method, extended Function of Multiple Instances ($e$FUMI), is applied to ballistocardiogram (BCG) signals produced by a hydraulic bed sensor. The goal of this approach is to learn a personalized heartbeat "concept" for an individual. This heartbeat concept is a prototype (or "signature") that characterizes the heartbeat pattern for an individual in ballistocardiogram data. The $e$FUMI method models the problem of learning a heartbeat concept from a BCG signal as a MIL problem. This approach elegantly addresses the uncertainty inherent in a BCG signal e. g., misalignment between training data and ground truth, mis-collection of heartbeat by some transducers, etc. Given a BCG training signal coupled with a ground truth signal (e.g., a pulse finger sensor), training "bags" labeled with only binary labels denoting if a training bag contains a heartbeat signal or not can be generated. Then, using these bags, $e$FUMI learns a personalized concept of heartbeat for a subject as well as several non-heartbeat background concepts. After learning the heartbeat concept, heartbeat detection and heart rate estimation can be applied to test data. Experimental results show that the estimated heartbeat concept found by $e$FUMI is more representative and a more discriminative prototype of the heartbeat signals than those found by comparison MIL methods in the literature.
* IEEE EMBC 2016, pp. 1-5
Adaptive coherence estimator (ACE) for explosive hazard detection using wideband electromagnetic induction (WEMI)
May 05, 2016The adaptive coherence estimator (ACE) estimates the squared cosine of the angle between a known target vector and a sample vector in a whitened coordinate space. The space is whitened according to an estimation of the background statistics, which directly effects the performance of the statistic as a target detector. In this paper, the ACE detection statistic is used to detect buried explosive hazards with data from a Wideband Electromagnetic Induction (WEMI) sensor. Target signatures are based on a dictionary defined using a Discrete Spectrum of Relaxation Frequencies (DSRF) model. Results are summarized as a receiver operator curve (ROC) and compared to other leading methods.
Partial Membership Latent Dirichlet Allocation
Apr 05, 2016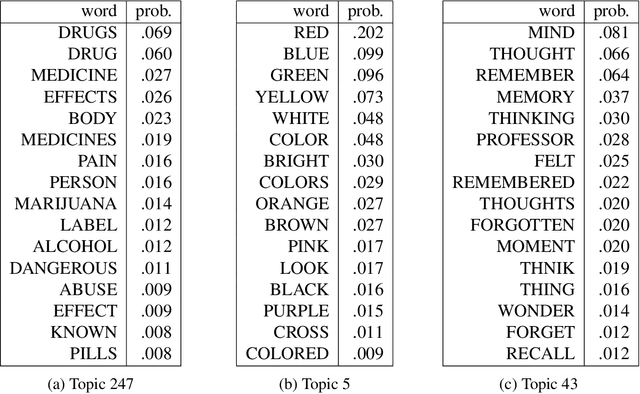

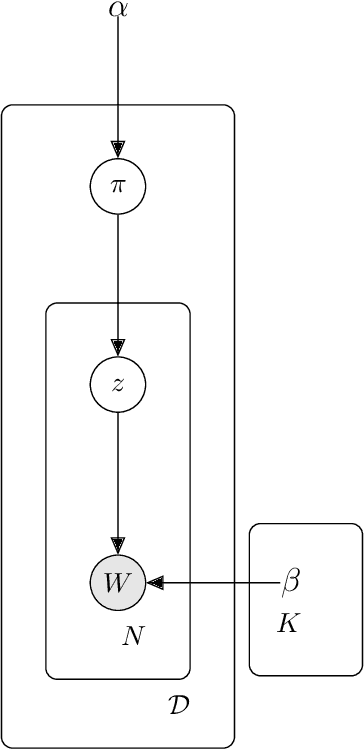
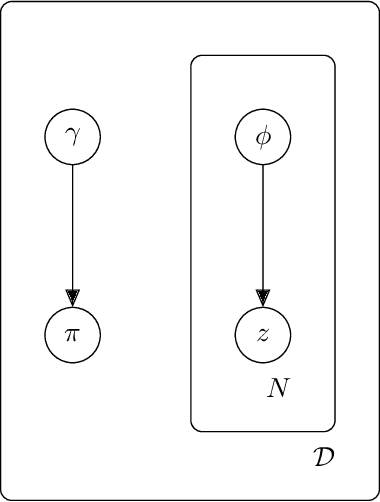
Topic models (e.g., pLSA, LDA, SLDA) have been widely used for segmenting imagery. These models are confined to crisp segmentation. Yet, there are many images in which some regions cannot be assigned a crisp label (e.g., transition regions between a foggy sky and the ground or between sand and water at a beach). In these cases, a visual word is best represented with partial memberships across multiple topics. To address this, we present a partial membership latent Dirichlet allocation (PM-LDA) model and associated parameter estimation algorithms. Experimental results on two natural image datasets and one SONAR image dataset show that PM-LDA can produce both crisp and soft semantic image segmentations; a capability existing methods do not have.
Instance Influence Estimation for Hyperspectral Target Signature Characterization using Extended Functions of Multiple Instances
Mar 21, 2016The Extended Functions of Multiple Instances (eFUMI) algorithm is a generalization of Multiple Instance Learning (MIL). In eFUMI, only bag level (i.e. set level) labels are needed to estimate target signatures from mixed data. The training bags in eFUMI are labeled positive if any data point in a bag contains or represents any proportion of the target signature and are labeled as a negative bag if all data points in the bag do not represent any target. From these imprecise labels, eFUMI has been shown to be effective at estimating target signatures in hyperspectral subpixel target detection problems. One motivating scenario for the use of eFUMI is where an analyst circles objects/regions of interest in a hyperspectral scene such that the target signatures of these objects can be estimated and be used to determine whether other instances of the object appear elsewhere in the image collection. The regions highlighted by the analyst serve as the imprecise labels for eFUMI. Often, an analyst may want to iteratively refine their imprecise labels. In this paper, we present an approach for estimating the influence on the estimated target signature if the label for a particular input data point is modified. This "instance influence estimation" guides an analyst to focus on (re-)labeling the data points that provide the largest change in the resulting estimated target signature and, thus, reduce the amount of time an analyst needs to spend refining the labels for a hyperspectral scene. Results are shown on real hyperspectral sub-pixel target detection data sets.
Buried object detection using handheld WEMI with task-driven extended functions of multiple instances
Mar 19, 2016Many effective supervised discriminative dictionary learning methods have been developed in the literature. However, when training these algorithms, precise ground-truth of the training data is required to provide very accurate point-wise labels. Yet, in many applications, accurate labels are not always feasible. This is especially true in the case of buried object detection in which the size of the objects are not consistent. In this paper, a new multiple instance dictionary learning algorithm for detecting buried objects using a handheld WEMI sensor is detailed. The new algorithm, Task Driven Extended Functions of Multiple Instances, can overcome data that does not have very precise point-wise labels and still learn a highly discriminative dictionary. Results are presented and discussed on measured WEMI data.
Estimating Target Signatures with Diverse Density
Oct 30, 2015
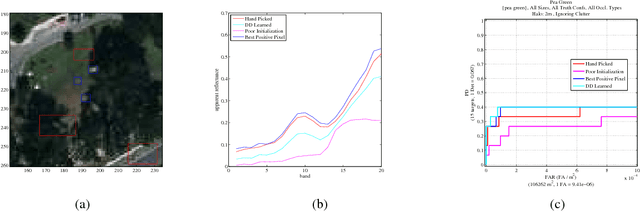
Hyperspectral target detection algorithms rely on knowing the desired target signature in advance. However, obtaining an effective target signature can be difficult; signatures obtained from laboratory measurements or hand-spectrometers in the field may not transfer to airborne imagery effectively. One approach to dealing with this difficulty is to learn an effective target signature from training data. An approach for learning target signatures from training data is presented. The proposed approach addresses uncertainty and imprecision in groundtruth in the training data using a multiple instance learning, diverse density (DD) based objective function. After learning the target signature given data with uncertain and imprecise groundtruth, target detection can be applied on test data. Results are shown on simulated and real data.