 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing the Biomechanics-Function Relationship in Glaucoma: Improved Visual Field Loss Predictions from intraocular pressure-induced Neural Tissue Strains
Jun 21, 2024

Objective. (1) To assess whether neural tissue structure and biomechanics could predict functional loss in glaucoma; (2) To evaluate the importance of biomechanics in making such predictions. Design, Setting and Participants. We recruited 238 glaucoma subjects. For one eye of each subject, we imaged the optic nerve head (ONH) using spectral-domain OCT under the following conditions: (1) primary gaze and (2) primary gaze with acute IOP elevation. Main Outcomes: We utilized automatic segmentation of optic nerve head (ONH) tissues and digital volume correlation (DVC) analysis to compute intraocular pressure (IOP)-induced neural tissue strains. A robust geometric deep learning approach, known as Point-Net, was employed to predict the full Humphrey 24-2 pattern standard deviation (PSD) maps from ONH structural and biomechanical information. For each point in each PSD map, we predicted whether it exhibited no defect or a PSD value of less than 5%. Predictive performance was evaluated using 5-fold cross-validation and the F1-score. We compared the model's performance with and without the inclusion of IOP-induced strains to assess the impact of biomechanics on prediction accuracy. Results: Integrating biomechanical (IOP-induced neural tissue strains) and structural (tissue morphology and neural tissues thickness) information yielded a significantly better predictive model (F1-score: 0.76+-0.02) across validation subjects, as opposed to relying only on structural information, which resulted in a significantly lower F1-score of 0.71+-0.02 (p < 0.05). Conclusion: Our study has shown that the integration of biomechanical data can significantly improve the accuracy of visual field loss predictions. This highlights the importance of the biomechanics-function relationship in glaucoma, and suggests that biomechanics may serve as a crucial indicator for the development and progression of glaucoma.
Are Macula or Optic Nerve Head Structures better at Diagnosing Glaucoma? An Answer using AI and Wide-Field Optical Coherence Tomography
Oct 13, 2022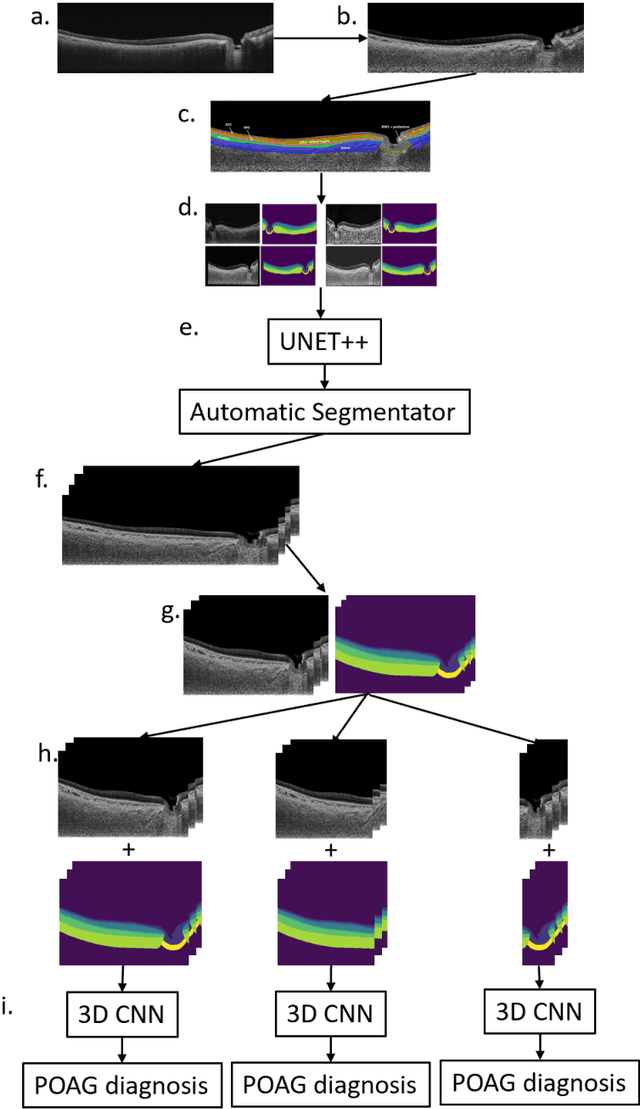
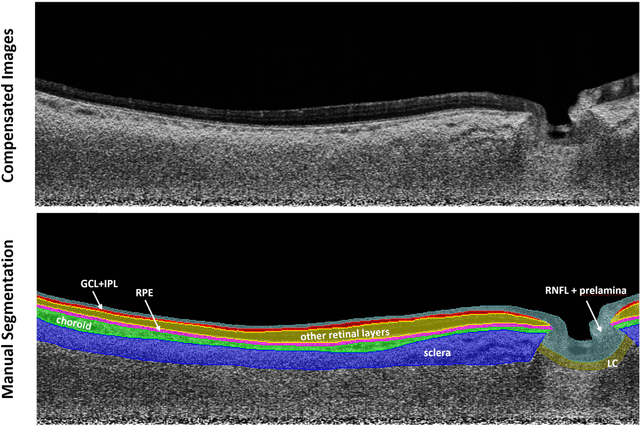
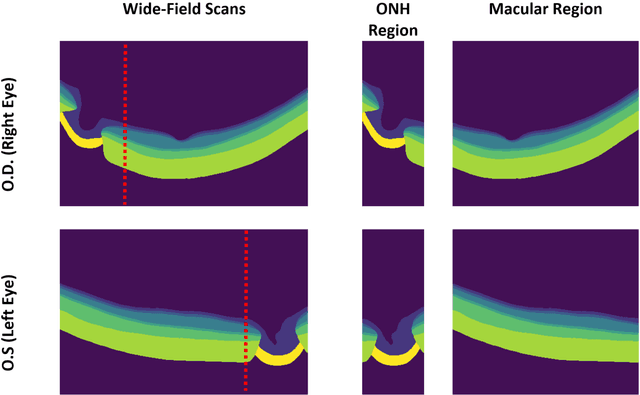
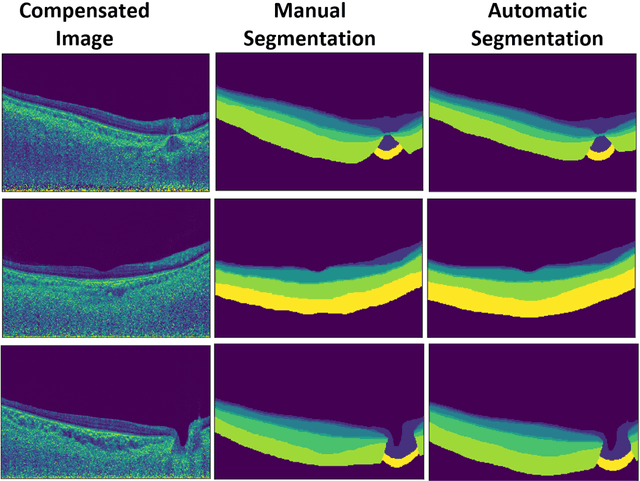
Purpose: (1) To develop a deep learning algorithm to automatically segment structures of the optic nerve head (ONH) and macula in 3D wide-field optical coherence tomography (OCT) scans; (2) To assess whether 3D macula or ONH structures (or the combination of both) provide the best diagnostic power for glaucoma. Methods: A cross-sectional comparative study was performed which included wide-field swept-source OCT scans from 319 glaucoma subjects and 298 non-glaucoma subjects. All scans were compensated to improve deep-tissue visibility. We developed a deep learning algorithm to automatically label all major ONH tissue structures by using 270 manually annotated B-scans for training. The performance of our algorithm was assessed using the Dice coefficient (DC). A glaucoma classification algorithm (3D CNN) was then designed using a combination of 500 OCT volumes and their corresponding automatically segmented masks. This algorithm was trained and tested on 3 datasets: OCT scans cropped to contain the macular tissues only, those to contain the ONH tissues only, and the full wide-field OCT scans. The classification performance for each dataset was reported using the AUC. Results: Our segmentation algorithm was able to segment ONH and macular tissues with a DC of 0.94 $\pm$ 0.003. The classification algorithm was best able to diagnose glaucoma using wide-field 3D-OCT volumes with an AUC of 0.99 $\pm$ 0.01, followed by ONH volumes with an AUC of 0.93 $\pm$ 0.06, and finally macular volumes with an AUC of 0.91 $\pm$ 0.11. Conclusions: this study showed that using wide-field OCT as compared to the typical OCT images containing just the ONH or macular may allow for a significantly improved glaucoma diagnosis. This may encourage the mainstream adoption of 3D wide-field OCT scans. For clinical AI studies that use traditional machines, we would recommend the use of ONH scans as opposed to macula scans.
A Generalized & Robust Framework For Timestamp Supervision in Temporal Action Segmentation
Jul 20, 2022
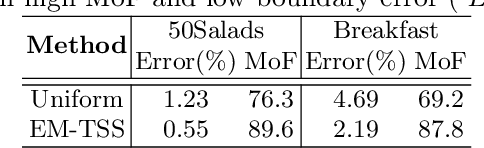
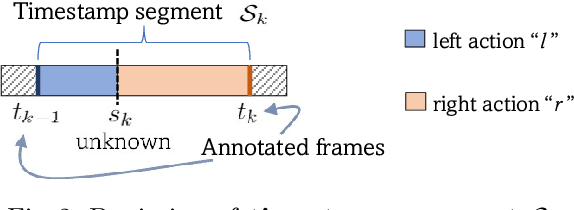
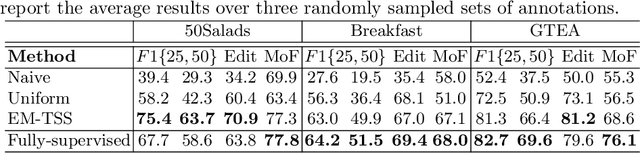
In temporal action segmentation, Timestamp supervision requires only a handful of labelled frames per video sequence. For unlabelled frames, previous works rely on assigning hard labels, and performance rapidly collapses under subtle violations of the annotation assumptions. We propose a novel Expectation-Maximization (EM) based approach that leverages the label uncertainty of unlabelled frames and is robust enough to accommodate possible annotation errors. With accurate timestamp annotations, our proposed method produces SOTA results and even exceeds the fully-supervised setup in several metrics and datasets. When applied to timestamp annotations with missing action segments, our method presents stable performance. To further test our formulation's robustness, we introduce the new challenging annotation setup of Skip-tag supervision. This setup relaxes constraints and requires annotations of any fixed number of random frames in a video, making it more flexible than Timestamp supervision while remaining competitive.