 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin--Driven Adaptive Wavelet Strategy for Efficient 6G Backbone Network Telemetry
Feb 23, 2026Classical orthogonal wavelets guarantee perfect reconstruction but rely on fixed bases optimized for polynomial smoothness, achieving suboptimal compression on signals with fractal spectral signatures. Conversely, learned methods offer adaptivity but typically enforce orthogonality via soft penalties, sacrificing structural guarantees. This work establishes a rigorous equivalence between Multiscale Entanglement Renormalization Ansatz (MERA) tensor networks and paraunitary filter banks. The resulting framework learns adaptive wavelets while enforcing exact orthogonality through manifold-constrained optimization, guaranteeing perfect reconstruction and energy conservation throughout training. Validation on Long-Range Dependent (LRD) network traffic demonstrates that learned filters outperform classical wavelets by 0.5--3.8~dB PSNR on six MAWI backbone traces (2020--2025, 314~Mbps--1.75~Gbps) while preserving the Hurst exponent within estimation uncertainty ($|ΔH| \le 0.03$). These results establish MERA-inspired wavelets as a principled approach for telemetry compression in 6G digital twin synchronization.
Structure-Informed Estimation for Pilot-Limited MIMO Channels via Tensor Decomposition
Feb 03, 2026Channel estimation in wideband multiple-input multiple-output (MIMO) systems faces fundamental pilot overhead limitations in high-dimensional beyond-5G and sixth-generation (6G) scenarios. This paper presents a hybrid tensor-neural architecture that formulates pilot-limited channel estimation as low-rank tensor completion from sparse observations -- a fundamentally different setting from prior tensor methods that assume fully observed received signal tensors. A canonical polyadic (CP) baseline implemented via a projection-based scheme (Tucker completion under partial observations) and Tucker decompositions are compared under varying signal-to-noise ratio (SNR) and scattering conditions: CP performs well for specular channels matching the multipath model, while Tucker provides greater robustness under model mismatch. A lightweight three-dimensional (3D) U-Net learns residual components beyond the low-rank structure, bridging algebraic models and realistic propagation effects. Empirical recovery threshold analysis shows that sample complexity scales approximately with intrinsic model dimensionality $L(N_r + N_t + N_f)$ rather than ambient tensor size $N_r N_t N_f$, where $L$ denotes the number of dominant propagation paths. Experiments on synthetic channels demonstrate 10-20\,dB normalized mean-square error (NMSE) improvement over least-squares (LS) and orthogonal matching pursuit (OMP) baselines at 5-10\% pilot density, while evaluations on DeepMIMO ray-tracing channels show 24-44\% additional NMSE reduction over pure tensor-based methods.
State-of-Charge Estimation of a Li-Ion Battery using Deep Forward Neural Networks
Sep 20, 2020

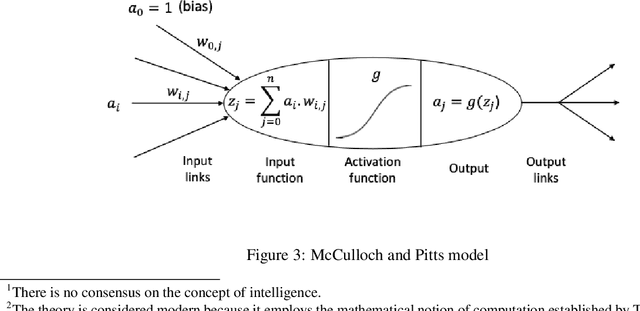
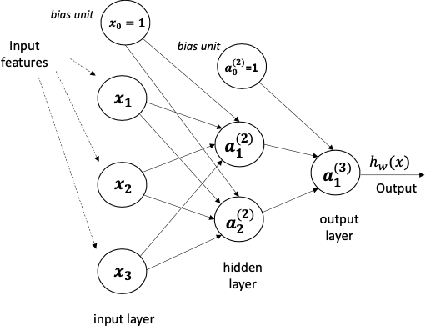
This article presents two Deep Forward Networks with two and four hidden layers, respectively, that model the drive cycle of a Panasonic 18650PF lithium-ion (Li-ion) battery at a given temperature using the K-fold cross-validation method, in order to estimate the State of Charge (SOC) of the cell. The drive cycle power profile is calculated for an electric truck with a 35kWh battery pack scaled for a single 18650PF cell. We propose a machine learning workflow which is able to fight overfitting when developing deep learning models for SOC estimation. The contribution of this work is to present a methodology of building a Deep Forward Network for a lithium-ion battery and its performance assessment, which follows the best practices in machine learning.