 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Architecture for Endpoint Position Prediction in Team-based Multiplayer Games
Jul 28, 2025Understanding and predicting player movement in multiplayer games is crucial for achieving use cases such as player-mimicking bot navigation, preemptive bot control, strategy recommendation, and real-time player behavior analytics. However, the complex environments allow for a high degree of navigational freedom, and the interactions and team-play between players require models that make effective use of the available heterogeneous input data. This paper presents a multimodal architecture for predicting future player locations on a dynamic time horizon, using a U-Net-based approach for calculating endpoint location probability heatmaps, conditioned using a multimodal feature encoder. The application of a multi-head attention mechanism for different groups of features allows for communication between agents. In doing so, the architecture makes efficient use of the multimodal game state including image inputs, numerical and categorical features, as well as dynamic game data. Consequently, the presented technique lays the foundation for various downstream tasks that rely on future player positions such as the creation of player-predictive bot behavior or player anomaly detection.
Deep Ordinal Reinforcement Learning
May 06, 2019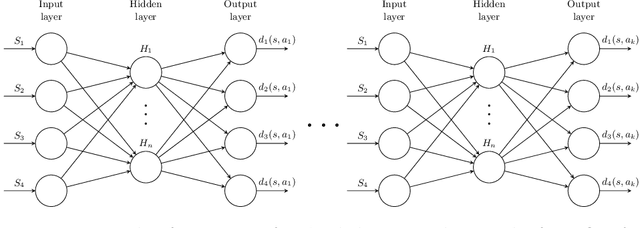



Reinforcement learning usually makes use of numerical rewards, which have nice properties but also come with drawbacks and difficulties. Using rewards on an ordinal scale (ordinal rewards) is an alternative to numerical rewards that has received more attention in recent years. In this paper, a general approach to adapting reinforcement learning problems to the use of ordinal rewards is presented and motivated. We show how to convert common reinforcement learning algorithms to an ordinal variation by the example of Q-learning and introduce Ordinal Deep Q-Networks, which adapt deep reinforcement learning to ordinal rewards. Additionally, we run evaluations on problems provided by the OpenAI Gym framework, showing that our ordinal variants exhibit a performance that is comparable to the numerical variations for a number of problems. We also give first evidence that our ordinal variant is able to produce better results for problems with less engineered and simpler-to-design reward signals.