 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictability Shapes Adaptation: An Evolutionary Perspective on Modes of Learning in Transformers
May 14, 2025Transformer models learn in two distinct modes: in-weights learning (IWL), encoding knowledge into model weights, and in-context learning (ICL), adapting flexibly to context without weight modification. To better understand the interplay between these learning modes, we draw inspiration from evolutionary biology's analogous adaptive strategies: genetic encoding (akin to IWL, adapting over generations and fixed within an individual's lifetime) and phenotypic plasticity (akin to ICL, enabling flexible behavioral responses to environmental cues). In evolutionary biology, environmental predictability dictates the balance between these strategies: stability favors genetic encoding, while reliable predictive cues promote phenotypic plasticity. We experimentally operationalize these dimensions of predictability and systematically investigate their influence on the ICL/IWL balance in Transformers. Using regression and classification tasks, we show that high environmental stability decisively favors IWL, as predicted, with a sharp transition at maximal stability. Conversely, high cue reliability enhances ICL efficacy, particularly when stability is low. Furthermore, learning dynamics reveal task-contingent temporal evolution: while a canonical ICL-to-IWL shift occurs in some settings (e.g., classification with many classes), we demonstrate that scenarios with easier IWL (e.g., fewer classes) or slower ICL acquisition (e.g., regression) can exhibit an initial IWL phase later yielding to ICL dominance. These findings support a relative-cost hypothesis for explaining these learning mode transitions, establishing predictability as a critical factor governing adaptive strategies in Transformers, and offering novel insights for understanding ICL and guiding training methodologies.
Capturing human category representations by sampling in deep feature spaces
May 19, 2018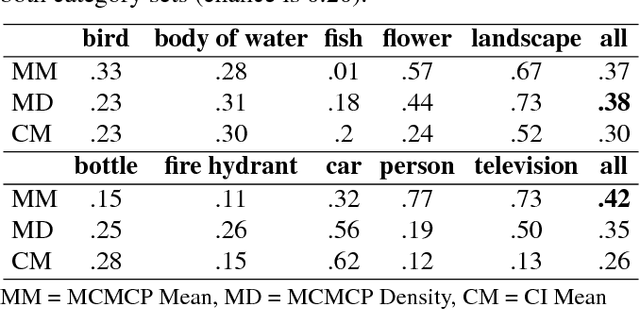
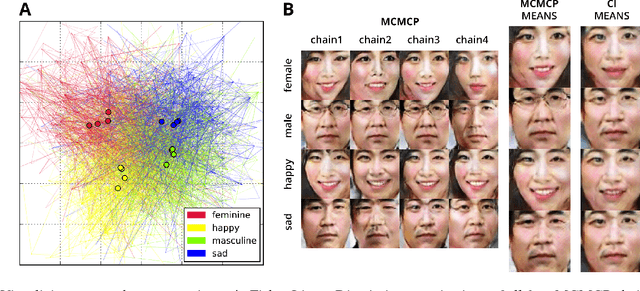
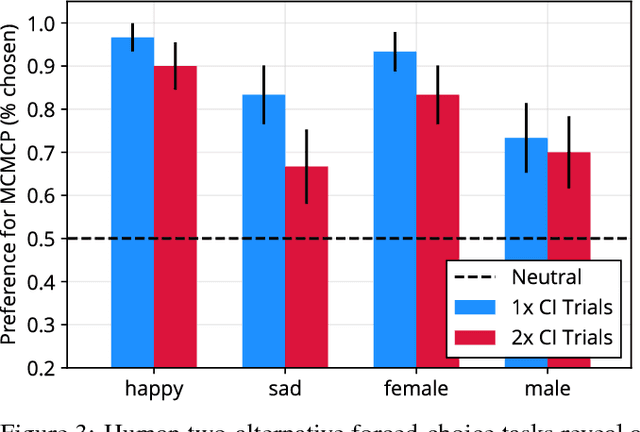

Understanding how people represent categories is a core problem in cognitive science. Decades of research have yielded a variety of formal theories of categories, but validating them with naturalistic stimuli is difficult. The challenge is that human category representations cannot be directly observed and running informative experiments with naturalistic stimuli such as images requires a workable representation of these stimuli. Deep neural networks have recently been successful in solving a range of computer vision tasks and provide a way to compactly represent image features. Here, we introduce a method to estimate the structure of human categories that combines ideas from cognitive science and machine learning, blending human-based algorithms with state-of-the-art deep image generators. We provide qualitative and quantitative results as a proof-of-concept for the method's feasibility. Samples drawn from human distributions rival those from state-of-the-art generative models in quality and outperform alternative methods for estimating the structure of human categories.