 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Explainability: Leveraging Interpretability for Improved Adversarial Learning
Apr 21, 2019
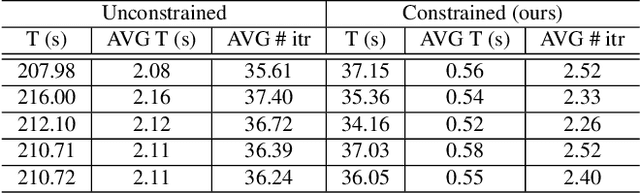

In this study, we propose the leveraging of interpretability for tasks beyond purely the purpose of explainability. In particular, this study puts forward a novel strategy for leveraging gradient-based interpretability in the realm of adversarial examples, where we use insights gained to aid adversarial learning. More specifically, we introduce the concept of spatially constrained one-pixel adversarial perturbations, where we guide the learning of such adversarial perturbations towards more susceptible areas identified via gradient-based interpretability. Experimental results using different benchmark datasets show that such a spatially constrained one-pixel adversarial perturbation strategy can noticeably improve the speed of convergence as well as produce successful attacks that were also visually difficult to perceive, thus illustrating an effective use of interpretability methods for tasks outside of the purpose of purely explainability.
Assessing Architectural Similarity in Populations of Deep Neural Networks
Apr 19, 2019
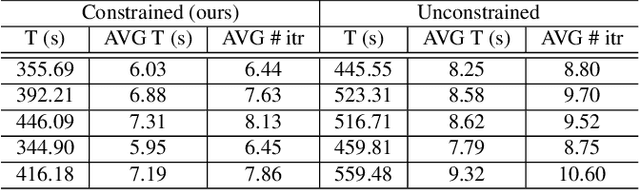
Evolutionary deep intelligence has recently shown great promise for producing small, powerful deep neural network models via the synthesis of increasingly efficient architectures over successive generations. Despite recent research showing the efficacy of multi-parent evolutionary synthesis, little has been done to directly assess architectural similarity between networks during the synthesis process for improved parent network selection. In this work, we present a preliminary study into quantifying architectural similarity via the percentage overlap of architectural clusters. Results show that networks synthesized using architectural alignment (via gene tagging) maintain higher architectural similarities within each generation, potentially restricting the search space of highly efficient network architectures.
AttoNets: Compact and Efficient Deep Neural Networks for the Edge via Human-Machine Collaborative Design
Apr 15, 2019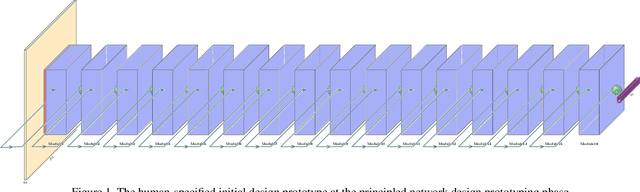
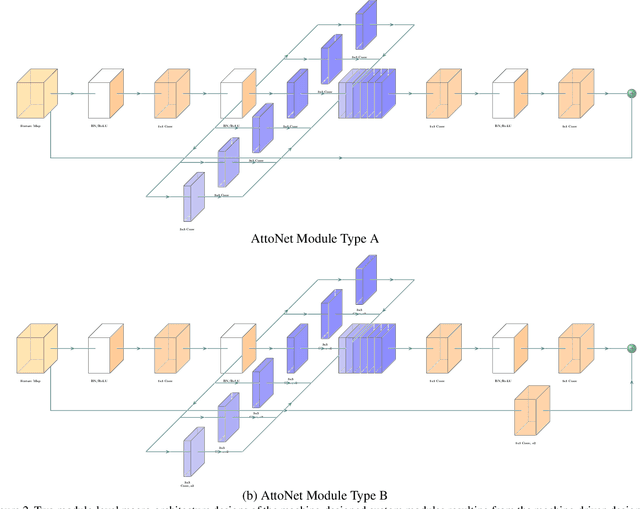
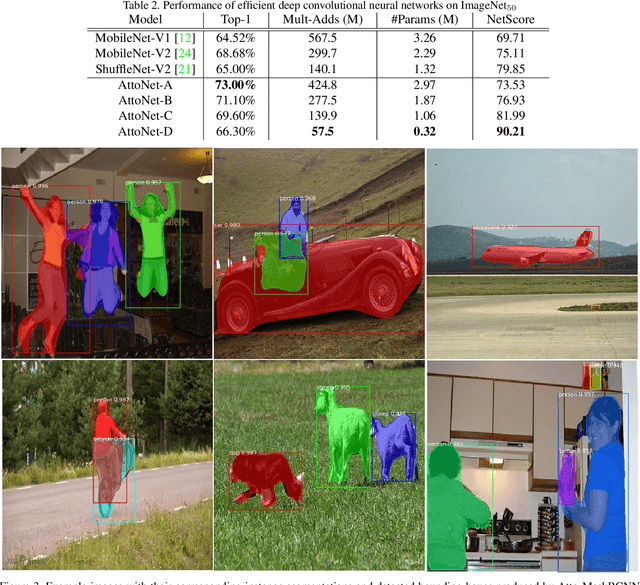
While deep neural networks have achieved state-of-the-art performance across a large number of complex tasks, it remains a big challenge to deploy such networks for practical, on-device edge scenarios such as on mobile devices, consumer devices, drones, and vehicles. In this study, we take a deeper exploration into a human-machine collaborative design approach for creating highly efficient deep neural networks through a synergy between principled network design prototyping and machine-driven design exploration. The efficacy of human-machine collaborative design is demonstrated through the creation of AttoNets, a family of highly efficient deep neural networks for on-device edge deep learning. Each AttoNet possesses a human-specified network-level macro-architecture comprising of custom modules with unique machine-designed module-level macro-architecture and micro-architecture designs, all driven by human-specified design requirements. Experimental results for the task of object recognition showed that the AttoNets created via human-machine collaborative design has significantly fewer parameters and computational costs than state-of-the-art networks designed for efficiency while achieving noticeably higher accuracy (with the smallest AttoNet achieving ~1.8% higher accuracy while requiring ~10x fewer multiply-add operations and parameters than MobileNet-V1). Furthermore, the efficacy of the AttoNets is demonstrated for the task of instance-level object segmentation and object detection, where an AttoNet-based Mask R-CNN network was constructed with significantly fewer parameters and computational costs (~5x fewer multiply-add operations and ~2x fewer parameters) than a ResNet-50 based Mask R-CNN network.
KPTransfer: improved performance and faster convergence from keypoint subset-wise domain transfer in human pose estimation
Mar 24, 2019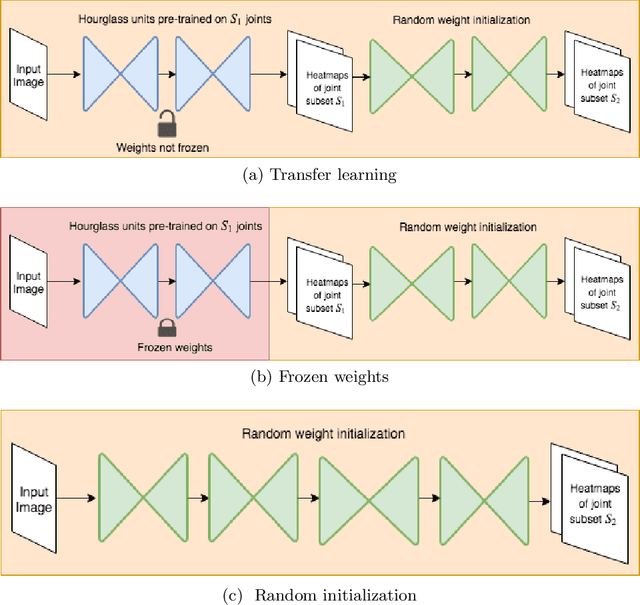

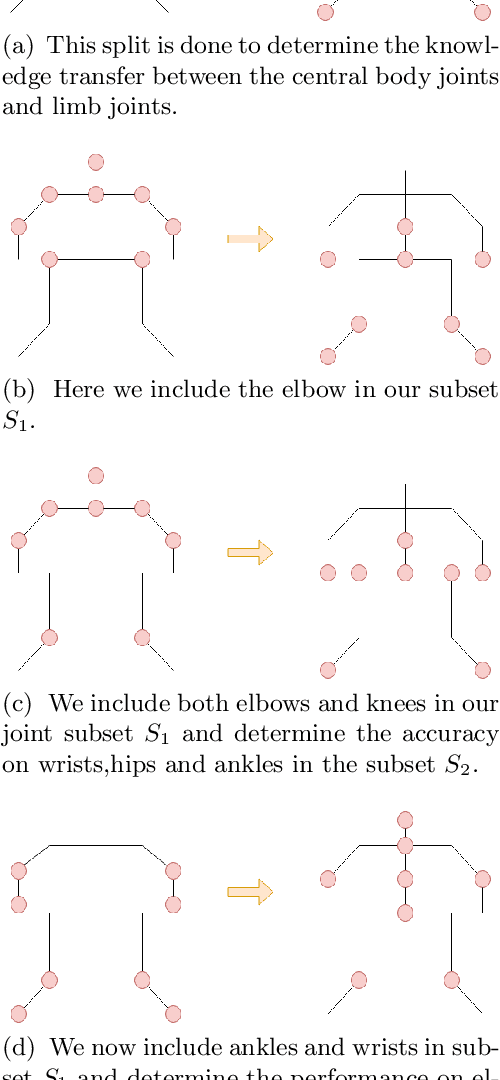
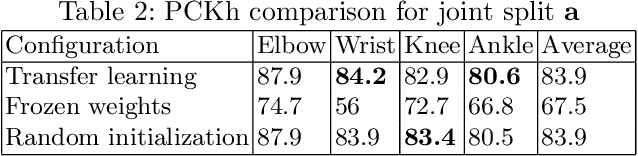
In this paper, we present a novel approach called KPTransfer for improving modeling performance for keypoint detection deep neural networks via domain transfer between different keypoint subsets. This approach is motivated by the notion that rich contextual knowledge can be transferred between different keypoint subsets representing separate domains. In particular, the proposed method takes into account various keypoint subsets/domains by sequentially adding and removing keypoints. Contextual knowledge is transferred between two separate domains via domain transfer. Experiments to demonstrate the efficacy of the proposed KPTransfer approach were performed for the task of human pose estimation on the MPII dataset, with comparisons against random initialization and frozen weight extraction configurations. Experimental results demonstrate the efficacy of performing domain transfer between two different joint subsets resulting in a PCKh improvement of up to 1.1 over random initialization on joints such as wrists and knee in certain joint splits with an overall PCKh improvement of 0.5. Domain transfer from a different set of joints not only results in improved accuracy but also results in faster convergence because of mutual co-adaptations of weights resulting from the contextual knowledge of the pose from a different set of joints.
GolfDB: A Video Database for Golf Swing Sequencing
Mar 15, 2019
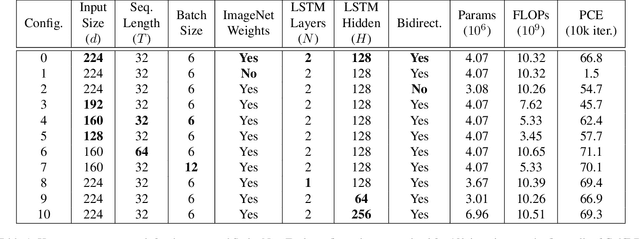


The golf swing is a complex movement requiring considerable full-body coordination to execute proficiently. As such, it is the subject of frequent scrutiny and extensive biomechanical analyses. In this paper, we introduce the notion of golf swing sequencing for detecting key events in the golf swing and facilitating golf swing analysis. To enable consistent evaluation of golf swing sequencing performance, we also introduce the benchmark database GolfDB, consisting of 1400 high-quality golf swing videos, each labeled with event frames, bounding box, player name and sex, club type, and view type. Furthermore, to act as a reference baseline for evaluating golf swing sequencing performance on GolfDB, we propose a lightweight deep neural network called SwingNet, which possesses a hybrid deep convolutional and recurrent neural network architecture. SwingNet correctly detects eight golf swing events at an average rate of 76.1%, and six out of eight events at a rate of 91.8%. In line with the proposed baseline SwingNet, we advocate the use of computationally efficient models in future research to promote in-the-field analysis via deployment on readily-available mobile devices.
STAR-Net: Action Recognition using Spatio-Temporal Activation Reprojection
Feb 26, 2019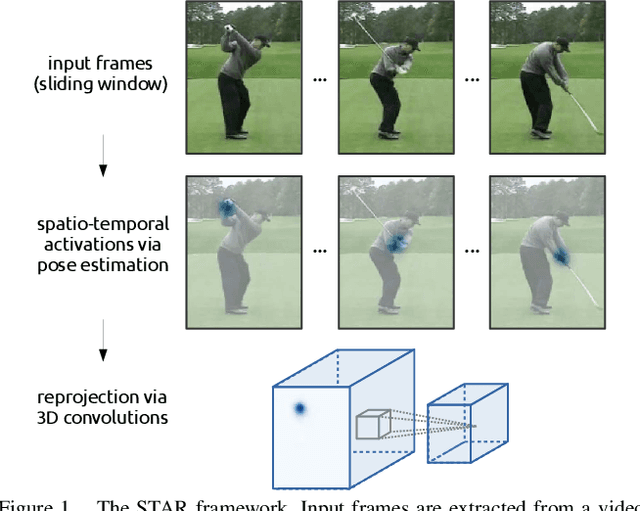
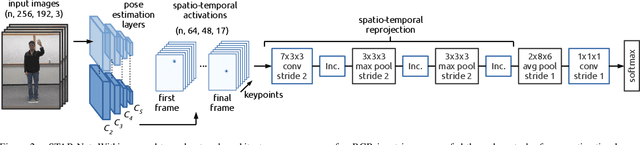


While depth cameras and inertial sensors have been frequently leveraged for human action recognition, these sensing modalities are impractical in many scenarios where cost or environmental constraints prohibit their use. As such, there has been recent interest on human action recognition using low-cost, readily-available RGB cameras via deep convolutional neural networks. However, many of the deep convolutional neural networks proposed for action recognition thus far have relied heavily on learning global appearance cues directly from imaging data, resulting in highly complex network architectures that are computationally expensive and difficult to train. Motivated to reduce network complexity and achieve higher performance, we introduce the concept of spatio-temporal activation reprojection (STAR). More specifically, we reproject the spatio-temporal activations generated by human pose estimation layers in space and time using a stack of 3D convolutions. Experimental results on UTD-MHAD and J-HMDB demonstrate that an end-to-end architecture based on the proposed STAR framework (which we nickname STAR-Net) is proficient in single-environment and small-scale applications. On UTD-MHAD, STAR-Net outperforms several methods using richer data modalities such as depth and inertial sensors.
Democratisation of Usable Machine Learning in Computer Vision
Feb 18, 2019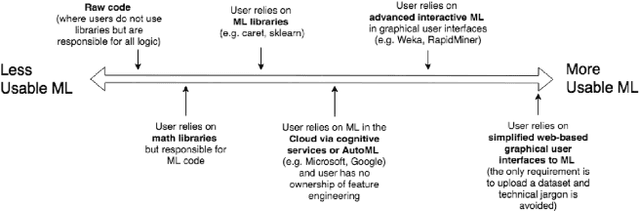

Many industries are now investing heavily in data science and automation to replace manual tasks and/or to help with decision making, especially in the realm of leveraging computer vision to automate many monitoring, inspection, and surveillance tasks. This has resulted in the emergence of the 'data scientist' who is conversant in statistical thinking, machine learning (ML), computer vision, and computer programming. However, as ML becomes more accessible to the general public and more aspects of ML become automated, applications leveraging computer vision are increasingly being created by non-experts with less opportunity for regulatory oversight. This points to the overall need for more educated responsibility for these lay-users of usable ML tools in order to mitigate potentially unethical ramifications. In this paper, we undertake a SWOT analysis to study the strengths, weaknesses, opportunities, and threats of building usable ML tools for mass adoption for important areas leveraging ML such as computer vision. The paper proposes a set of data science literacy criteria for educating and supporting lay-users in the responsible development and deployment of ML applications.
Progressive Label Distillation: Learning Input-Efficient Deep Neural Networks
Jan 26, 2019
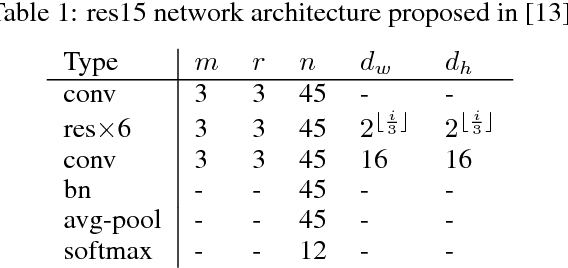
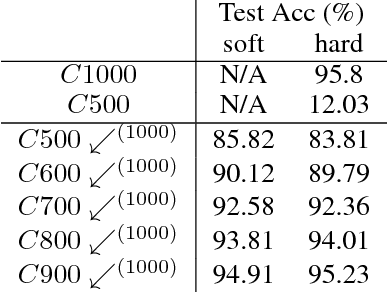
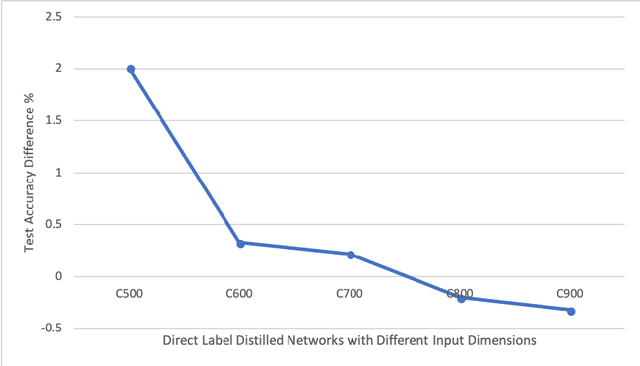
Much of the focus in the area of knowledge distillation has been on distilling knowledge from a larger teacher network to a smaller student network. However, there has been little research on how the concept of distillation can be leveraged to distill the knowledge encapsulated in the training data itself into a reduced form. In this study, we explore the concept of progressive label distillation, where we leverage a series of teacher-student network pairs to progressively generate distilled training data for learning deep neural networks with greatly reduced input dimensions. To investigate the efficacy of the proposed progressive label distillation approach, we experimented with learning a deep limited vocabulary speech recognition network based on generated 500ms input utterances distilled progressively from 1000ms source training data, and demonstrated a significant increase in test accuracy of almost 78% compared to direct learning.
SISC: End-to-end Interpretable Discovery Radiomics-Driven Lung Cancer Prediction via Stacked Interpretable Sequencing Cells
Jan 15, 2019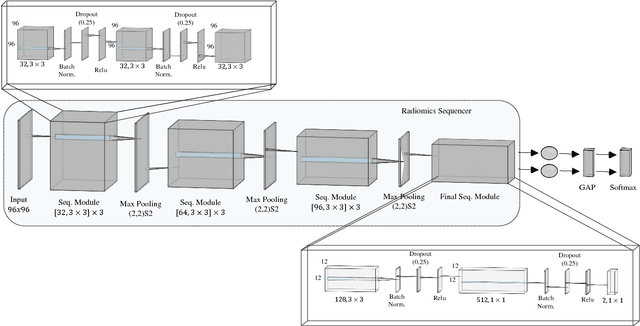
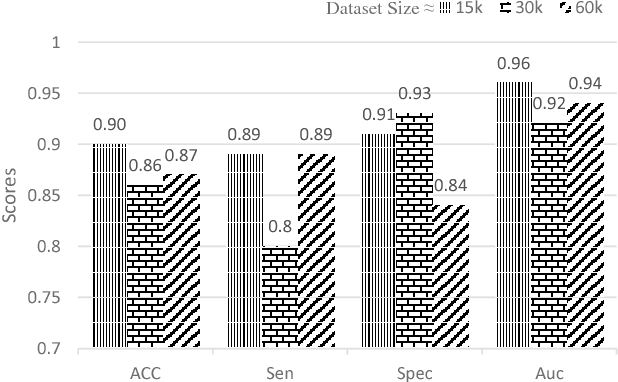
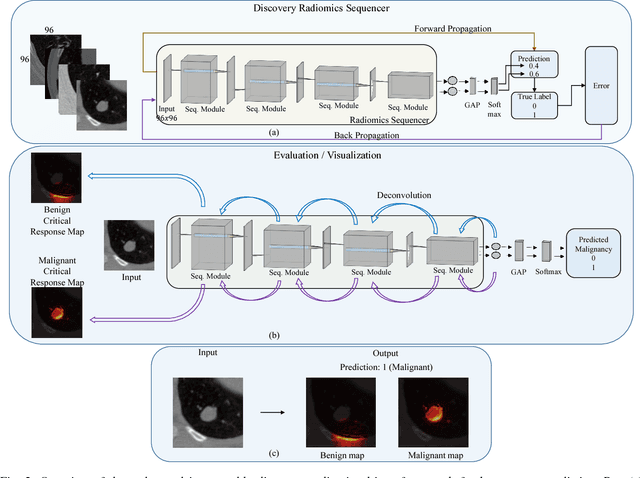
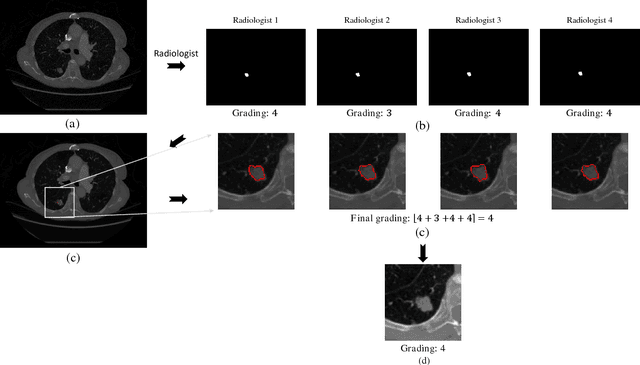
Objective: Lung cancer is the leading cause of cancer-related death worldwide. Computer-aided diagnosis (CAD) systems have shown significant promise in recent years for facilitating the effective detection and classification of abnormal lung nodules in computed tomography (CT) scans. While hand-engineered radiomic features have been traditionally used for lung cancer prediction, there have been significant recent successes achieving state-of-the-art results in the area of discovery radiomics. Here, radiomic sequencers comprising of highly discriminative radiomic features are discovered directly from archival medical data. However, the interpretation of predictions made using such radiomic sequencers remains a challenge. Method: A novel end-to-end interpretable discovery radiomics-driven lung cancer prediction pipeline has been designed, build, and tested. The radiomic sequencer being discovered possesses a deep architecture comprised of stacked interpretable sequencing cells (SISC). Results: The SISC architecture is shown to outperform previous approaches while providing more insight in to its decision making process. Conclusion: The SISC radiomic sequencer is able to achieve state-of-the-art results in lung cancer prediction, and also offers prediction interpretability in the form of critical response maps. Significance: The critical response maps are useful for not only validating the predictions of the proposed SISC radiomic sequencer, but also provide improved radiologist-machine collaboration for effective diagnosis.
ProstateGAN: Mitigating Data Bias via Prostate Diffusion Imaging Synthesis with Generative Adversarial Networks
Nov 21, 2018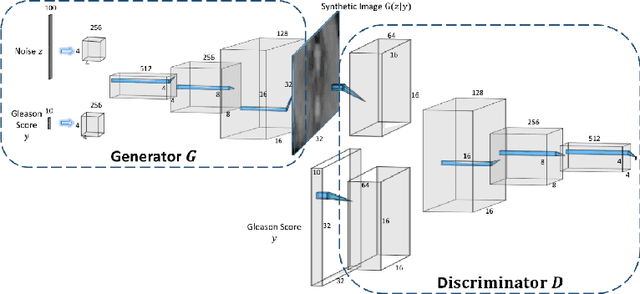

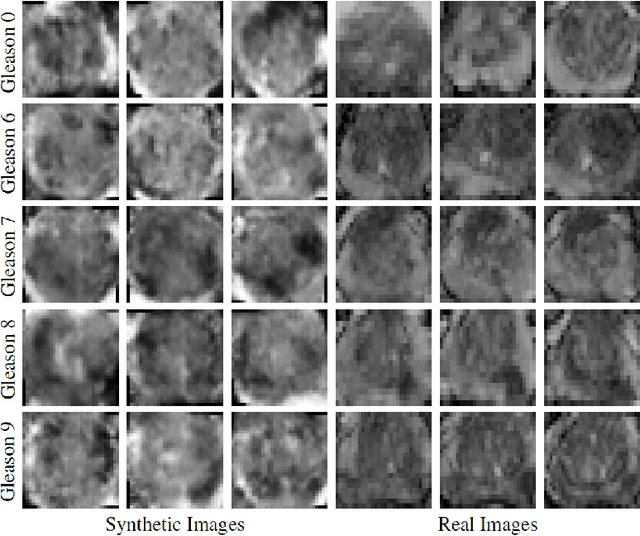
Generative Adversarial Networks (GANs) have shown considerable promise for mitigating the challenge of data scarcity when building machine learning-driven analysis algorithms. Specifically, a number of studies have shown that GAN-based image synthesis for data augmentation can aid in improving classification accuracy in a number of medical image analysis tasks, such as brain and liver image analysis. However, the efficacy of leveraging GANs for tackling prostate cancer analysis has not been previously explored. Motivated by this, in this study we introduce ProstateGAN, a GAN-based model for synthesizing realistic prostate diffusion imaging data. More specifically, in order to generate new diffusion imaging data corresponding to a particular cancer grade (Gleason score), we propose a conditional deep convolutional GAN architecture that takes Gleason scores into consideration during the training process. Experimental results show that high-quality synthetic prostate diffusion imaging data can be generated using the proposed ProstateGAN for specified Gleason scores.