 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairest of Them All: Establishing a Strong Baseline for Cross-Domain Person ReID
Jul 28, 2019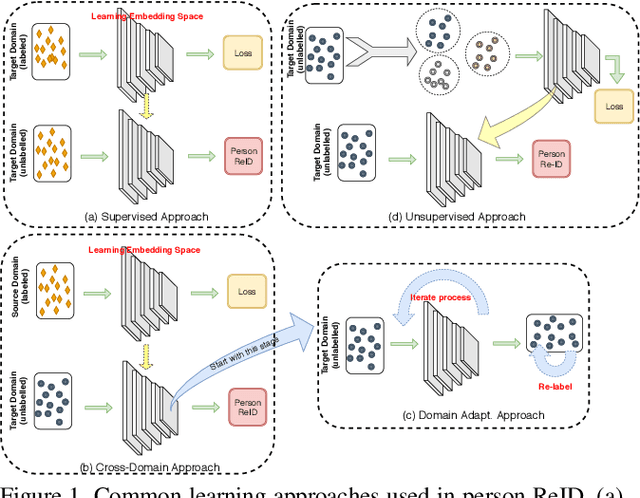
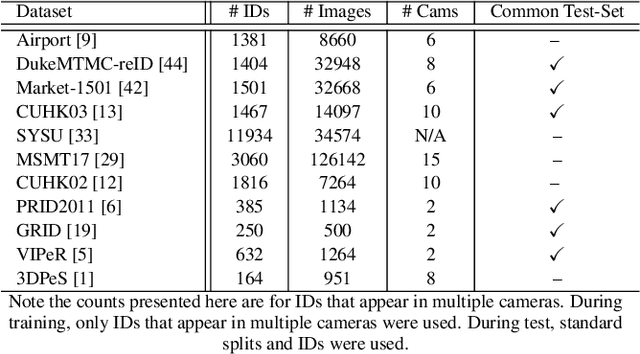

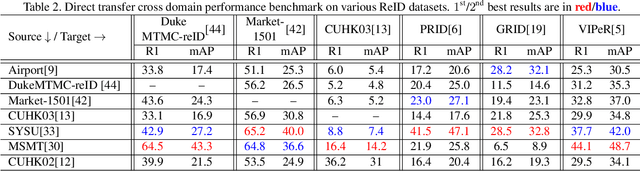
Person re-identification (ReID) remains a very difficult challenge in computer vision, and critical for large-scale video surveillance scenarios where an individual could appear in different camera views at different times. There has been recent interest in tackling this challenge using cross-domain approaches, which leverages data from source domains that are different than the target domain. Such approaches are more practical for real-world widespread deployment given that they don't require on-site training (as with unsupervised or domain transfer approaches) or on-site manual annotation and training (as with supervised approaches). In this study, we take a systematic approach to establishing a large baseline source domain and target domain for cross-domain person ReID. We accomplish this by conducting a comprehensive analysis to study the similarities between source domains proposed in literature, and studying the effects of incrementally increasing the size of the source domain. This allows us to establish a balanced source domain and target domain split that promotes variety in both source and target domains. Furthermore, using lessons learned from the state-of-the-art supervised person re-identification methods, we establish a strong baseline method for cross-domain person ReID. Experiments show that a source domain composed of two of the largest person ReID domains (SYSU and MSMT) performs well across six commonly-used target domains. Furthermore, we show that, surprisingly, two of the recent commonly-used domains (PRID and GRID) have too few query images to provide meaningful insights. As such, based on our findings, we propose the following balanced baseline for cross-domain person ReID consisting of: i) a fixed multi-source domain consisting of SYSU, MSMT, Airport and 3DPeS, and ii) a multi-target domain consisting of Market-1501, DukeMTMC-reID, CUHK03, PRID, GRID and VIPeR.
Auditing ImageNet: Towards a Model-driven Framework for Annotating Demographic Attributes of Large-Scale Image Datasets
Jun 04, 2019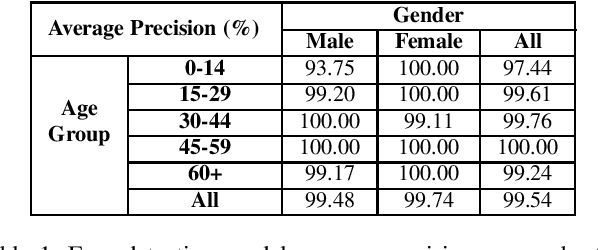
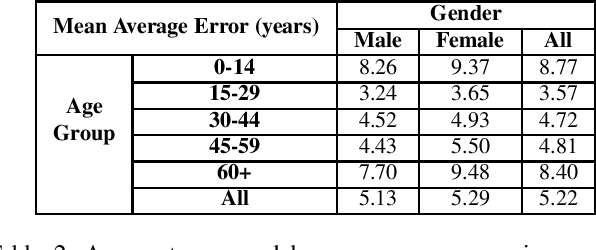
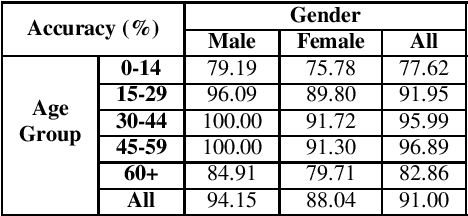
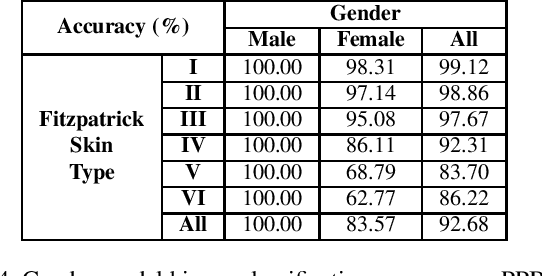
The ImageNet dataset ushered in a flood of academic and industry interest in deep learning for computer vision applications. Despite its significant impact, there has not been a comprehensive investigation into the demographic attributes of images contained within the dataset. Such a study could lead to new insights on inherent biases within ImageNet, particularly important given it is frequently used to pretrain models for a wide variety of computer vision tasks. In this work, we introduce a model-driven framework for the automatic annotation of apparent age and gender attributes in large-scale image datasets. Using this framework, we conduct the first demographic audit of the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) subset of ImageNet and the "person" hierarchical category of ImageNet. We find that 41.62% of faces in ILSVRC appear as female, 1.71% appear as individuals above the age of 60, and males aged 15 to 29 account for the largest subgroup with 27.11%. We note that the presented model-driven framework is not fair for all intersectional groups, so annotation are subject to bias. We present this work as the starting point for future development of unbiased annotation models and for the study of downstream effects of imbalances in the demographics of ImageNet. Code and annotations are available at: http://bit.ly/ImageNetDemoAudit
Food for thought: Ethical considerations of user trust in computer vision
May 29, 2019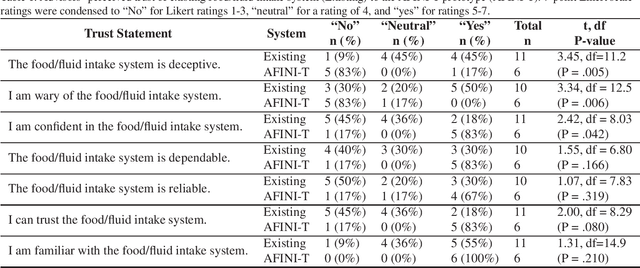
In computer vision research, especially when novel applications of tools are developed, ethical implications around user perceptions of trust in the underlying technology should be considered and supported. Here, we describe an example of the incorporation of such considerations within the long-term care sector for tracking resident food and fluid intake. We highlight our recent user study conducted to develop a Goldilocks quality horizontal prototype designed to support trust cues in which perceived trust in our horizontal prototype was higher than the existing system in place. We discuss the importance and need for user engagement as part of ongoing computer vision-driven technology development and describe several important factors related to trust that are relevant to developing decision-making tools.
Seeing Convolution Through the Eyes of Finite Transformation Semigroup Theory: An Abstract Algebraic Interpretation of Convolutional Neural Networks
May 26, 2019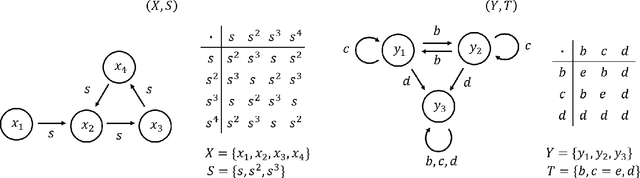

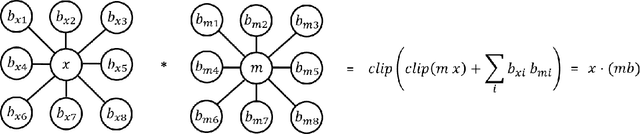
Researchers are actively trying to gain better insights into the representational properties of convolutional neural networks for guiding better network designs and for interpreting a network's computational nature. Gaining such insights can be an arduous task due to the number of parameters in a network and the complexity of a network's architecture. Current approaches of neural network interpretation include Bayesian probabilistic interpretations and information theoretic interpretations. In this study, we take a different approach to studying convolutional neural networks by proposing an abstract algebraic interpretation using finite transformation semigroup theory. Specifically, convolutional layers are broken up and mapped to a finite space. The state space of the proposed finite transformation semigroup is then defined as a single element within the convolutional layer, with the acting elements defined by surrounding state elements combined with convolution kernel elements. Generators of the finite transformation semigroup are defined to complete the interpretation. We leverage this approach to analyze the basic properties of the resulting finite transformation semigroup to gain insights on the representational properties of convolutional neural networks, including insights into quantized network representation. Such a finite transformation semigroup interpretation can also enable better understanding outside of the confines of fixed lattice data structures, thus useful for handling data that lie on irregular lattices. Furthermore, the proposed abstract algebraic interpretation is shown to be viable for interpreting convolutional operations within a variety of convolutional neural network architectures.
Implications of Computer Vision Driven Assistive Technologies Towards Individuals with Visual Impairment
May 20, 2019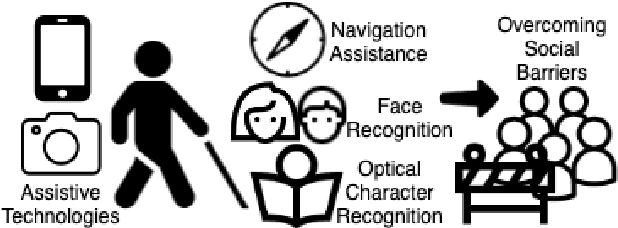
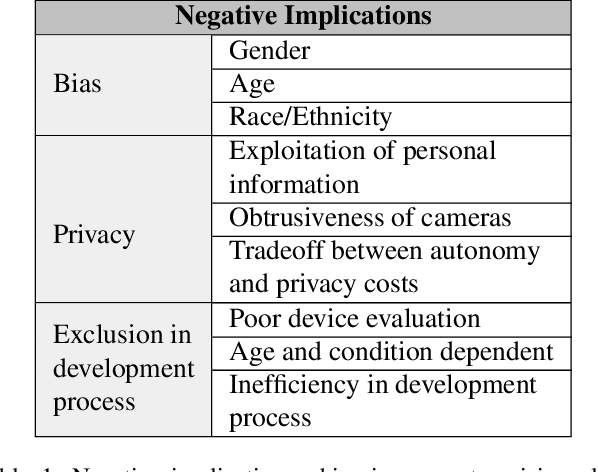
Computer vision based technology is becoming ubiquitous in society. One application area that has seen an increase in computer vision is assistive technologies, specifically for those with visual impairment. Research has shown the ability of computer vision models to achieve tasks such provide scene captions, detect objects and recognize faces. Although assisting individuals with visual impairment with these tasks increases their independence and autonomy, concerns over bias, privacy and potential usefulness arise. This paper addresses the positive and negative implications computer vision based assistive technologies have on individuals with visual impairment, as well as considerations for computer vision researchers and developers in order to mitigate the amount of negative implications.
Enabling Computer Vision Driven Assistive Devices for the Visually Impaired via Micro-architecture Design Exploration
May 20, 2019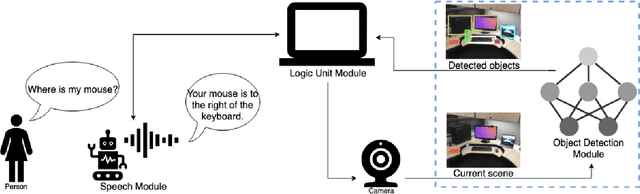
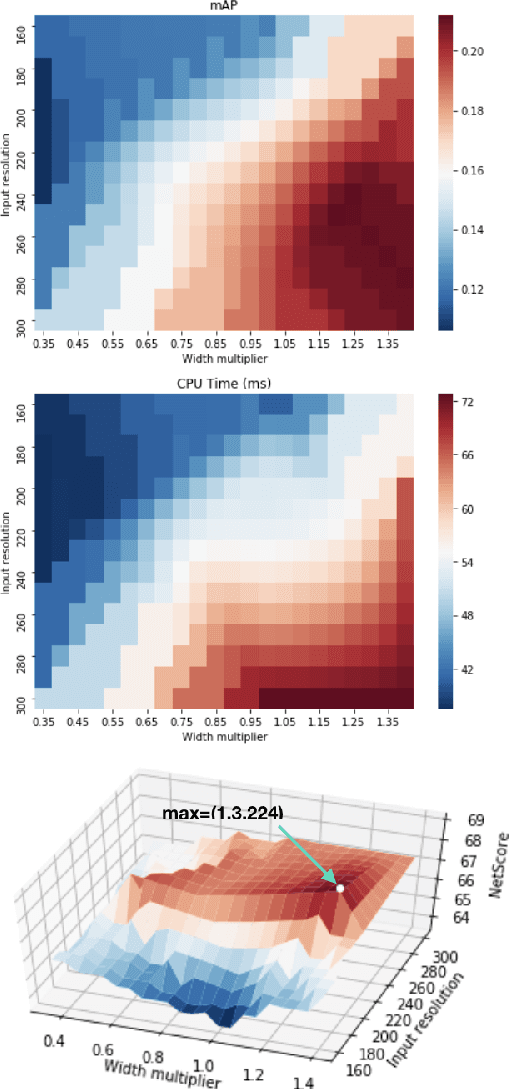
Recent improvements in object detection have shown potential to aid in tasks where previous solutions were not able to achieve. A particular area is assistive devices for individuals with visual impairment. While state-of-the-art deep neural networks have been shown to achieve superior object detection performance, their high computational and memory requirements make them cost prohibitive for on-device operation. Alternatively, cloud-based operation leads to privacy concerns, both not attractive to potential users. To address these challenges, this study investigates creating an efficient object detection network specifically for OLIV, an AI-powered assistant for object localization for the visually impaired, via micro-architecture design exploration. In particular, we formulate the problem of finding an optimal network micro-architecture as an numerical optimization problem, where we find the set of hyperparameters controlling the MobileNetV2-SSD network micro-architecture that maximizes a modified NetScore objective function for the MSCOCO-OLIV dataset of indoor objects. Experimental results show that such a micro-architecture design exploration strategy leads to a compact deep neural network with a balanced trade-off between accuracy, size, and speed, making it well-suited for enabling on-device computer vision driven assistive devices for the visually impaired.
Affine Variational Autoencoders: An Efficient Approach for Improving Generalization and Robustness to Distribution Shift
May 13, 2019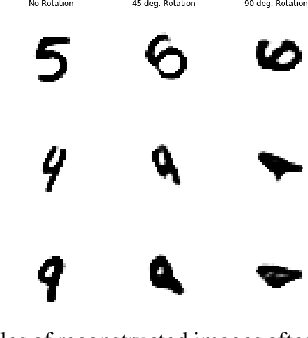

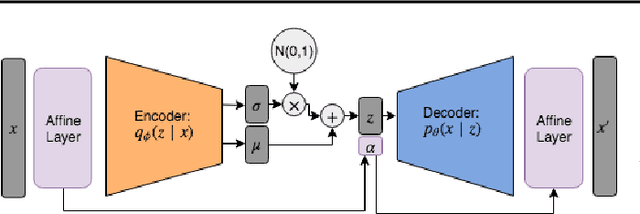
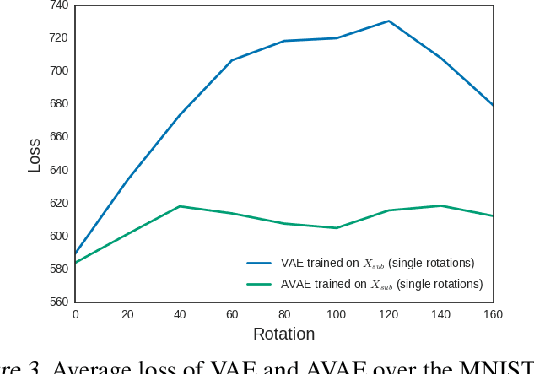
In this study, we propose the Affine Variational Autoencoder (AVAE), a variant of Variational Autoencoder (VAE) designed to improve robustness by overcoming the inability of VAEs to generalize to distributional shifts in the form of affine perturbations. By optimizing an affine transform to maximize ELBO, the proposed AVAE transforms an input to the training distribution without the need to increase model complexity to model the full distribution of affine transforms. In addition, we introduce a training procedure to create an efficient model by learning a subset of the training distribution, and using the AVAE to improve generalization and robustness to distributional shift at test time. Experiments on affine perturbations demonstrate that the proposed AVAE significantly improves generalization and robustness to distributional shift in the form of affine perturbations without an increase in model complexity.
Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification
May 12, 2019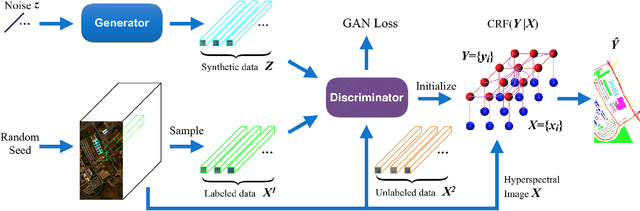
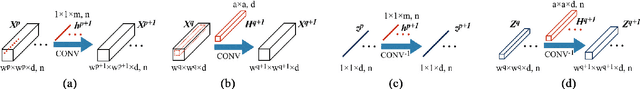
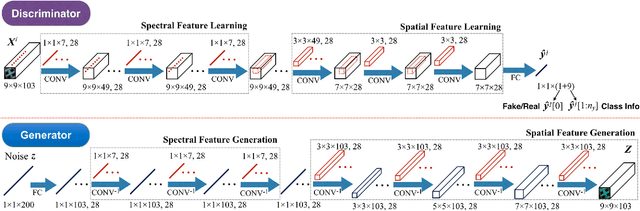
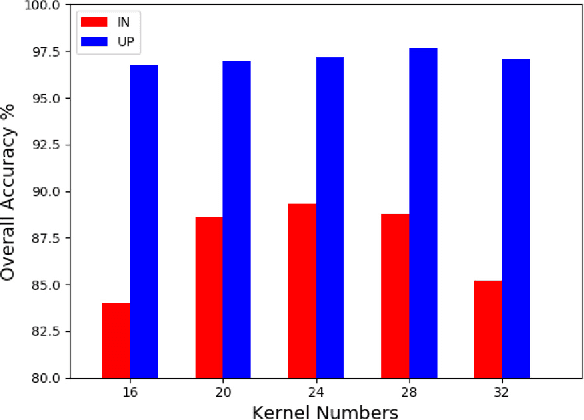
In this paper, we address the hyperspectral image (HSI) classification task with a generative adversarial network and conditional random field (GAN-CRF) -based framework, which integrates a semi-supervised deep learning and a probabilistic graphical model, and make three contributions. First, we design four types of convolutional and transposed convolutional layers that consider the characteristics of HSIs to help with extracting discriminative features from limited numbers of labeled HSI samples. Second, we construct semi-supervised GANs to alleviate the shortage of training samples by adding labels to them and implicitly reconstructing real HSI data distribution through adversarial training. Third, we build dense conditional random fields (CRFs) on top of the random variables that are initialized to the softmax predictions of the trained GANs and are conditioned on HSIs to refine classification maps. This semi-supervised framework leverages the merits of discriminative and generative models through a game-theoretical approach. Moreover, even though we used very small numbers of labeled training HSI samples from the two most challenging and extensively studied datasets, the experimental results demonstrated that spectral-spatial GAN-CRF (SS-GAN-CRF) models achieved top-ranking accuracy for semi-supervised HSI classification.
EdgeSegNet: A Compact Network for Semantic Segmentation
May 10, 2019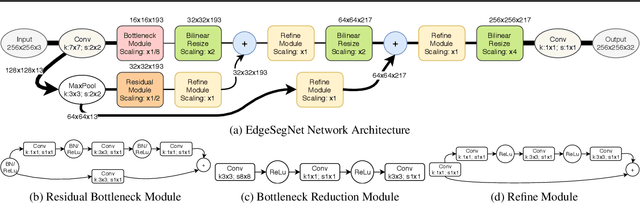

In this study, we introduce EdgeSegNet, a compact deep convolutional neural network for the task of semantic segmentation. A human-machine collaborative design strategy is leveraged to create EdgeSegNet, where principled network design prototyping is coupled with machine-driven design exploration to create networks with customized module-level macroarchitecture and microarchitecture designs tailored for the task. Experimental results showed that EdgeSegNet can achieve semantic segmentation accuracy comparable with much larger and computationally complex networks (>20x} smaller model size than RefineNet) as well as achieving an inference speed of ~38.5 FPS on an NVidia Jetson AGX Xavier. As such, the proposed EdgeSegNet is well-suited for low-power edge scenarios.
Towards computer vision powered color-nutrient assessment of pureed food
May 01, 2019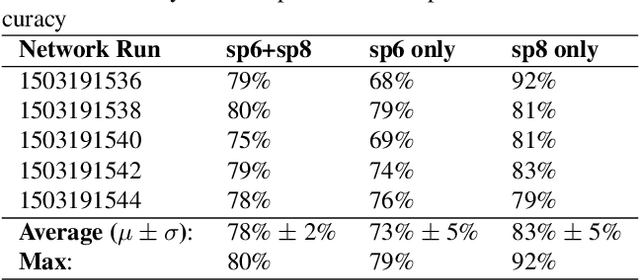
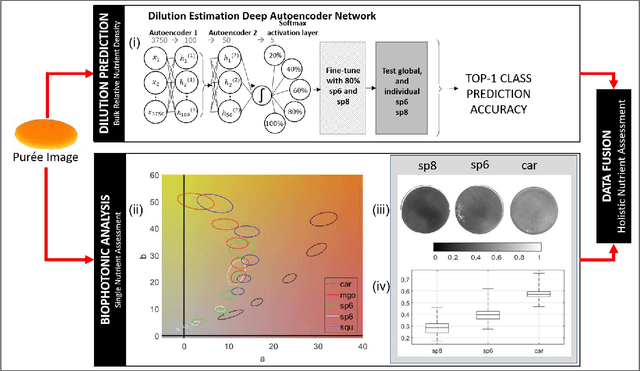
With one in four individuals afflicted with malnutrition, computer vision may provide a way of introducing a new level of automation in the nutrition field to reliably monitor food and nutrient intake. In this study, we present a novel approach to modeling the link between color and vitamin A content using transmittance imaging of a pureed foods dilution series in a computer vision powered nutrient sensing system via a fine-tuned deep autoencoder network, which in this case was trained to predict the relative concentration of sweet potato purees. Experimental results show the deep autoencoder network can achieve an accuracy of 80% across beginner (6 month) and intermediate (8 month) commercially prepared pureed sweet potato samples. Prediction errors may be explained by fundamental differences in optical properties which are further discussed.