 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation in Person re-ID via k-Reciprocal Clustering and Large-Scale Heterogeneous Environment Synthesis
Jan 14, 2020
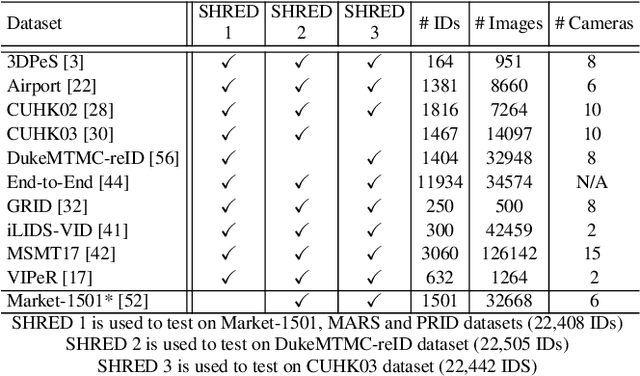
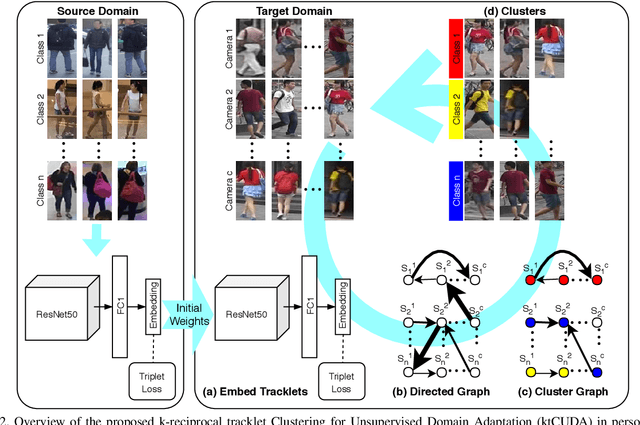
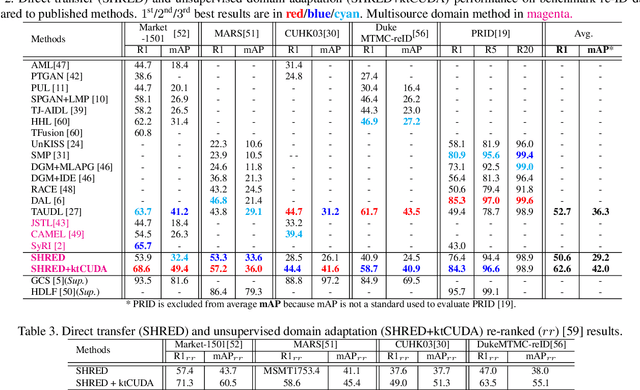
An ongoing major challenge in computer vision is the task of person re-identification, where the goal is to match individuals across different, non-overlapping camera views. While recent success has been achieved via supervised learning using deep neural networks, such methods have limited widespread adoption due to the need for large-scale, customized data annotation. As such, there has been a recent focus on unsupervised learning approaches to mitigate the data annotation issue; however, current approaches in literature have limited performance compared to supervised learning approaches as well as limited applicability for adoption in new environments. In this paper, we address the aforementioned challenges faced in person re-identification for real-world, practical scenarios by introducing a novel, unsupervised domain adaptation approach for person re-identification. This is accomplished through the introduction of: i) k-reciprocal tracklet Clustering for Unsupervised Domain Adaptation (ktCUDA) (for pseudo-label generation on target domain), and ii) Synthesized Heterogeneous RE-id Domain (SHRED) composed of large-scale heterogeneous independent source environments (for improving robustness and adaptability to a wide diversity of target environments). Experimental results across four different image and video benchmark datasets show that the proposed ktCUDA and SHRED approach achieves an average improvement of +5.7 mAP in re-identification performance when compared to existing state-of-the-art methods, as well as demonstrate better adaptability to different types of environments.
Investigating the Impact of Inclusion in Face Recognition Training Data on Individual Face Identification
Jan 10, 2020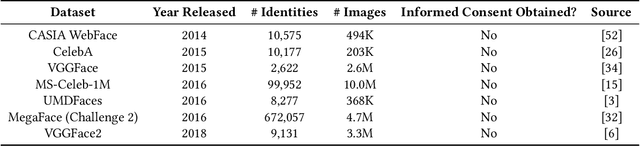
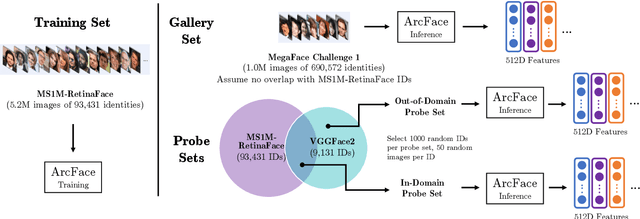
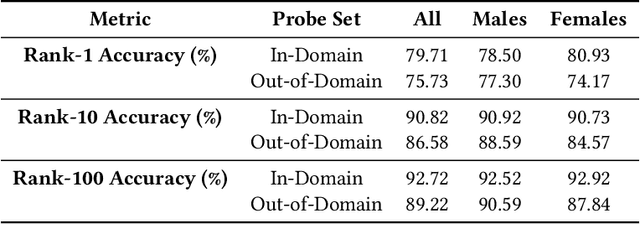
Modern face recognition systems leverage datasets containing images of hundreds of thousands of specific individuals' faces to train deep convolutional neural networks to learn an embedding space that maps an arbitrary individual's face to a vector representation of their identity. The performance of a face recognition system in face verification (1:1) and face identification (1:N) tasks is directly related to the ability of an embedding space to discriminate between identities. Recently, there has been significant public scrutiny into the source and privacy implications of large-scale face recognition training datasets such as MS-Celeb-1M and MegaFace, as many people are uncomfortable with their face being used to train dual-use technologies that can enable mass surveillance. However, the impact of an individual's inclusion in training data on a derived system's ability to recognize them has not previously been studied. In this work, we audit ArcFace, a state-of-the-art, open source face recognition system, in a large-scale face identification experiment with more than one million distractor images. We find a Rank-1 face identification accuracy of 79.71% for individuals present in the model's training data and an accuracy of 75.73% for those not present. This modest difference in accuracy demonstrates that face recognition systems using deep learning work better for individuals they are trained on, which has serious privacy implications when one considers all major open source face recognition training datasets do not obtain informed consent from individuals during their collection.
Taking a Stance on Fake News: Towards Automatic Disinformation Assessment via Deep Bidirectional Transformer Language Models for Stance Detection
Nov 27, 2019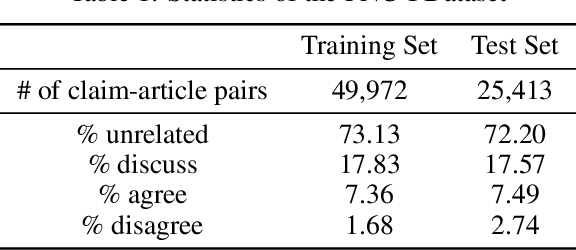
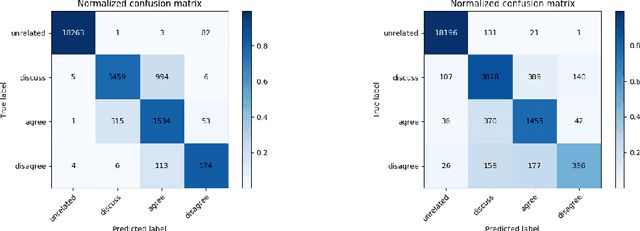
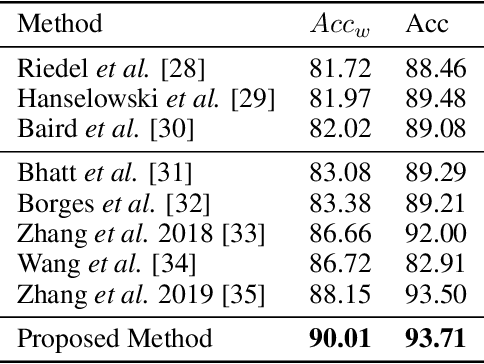
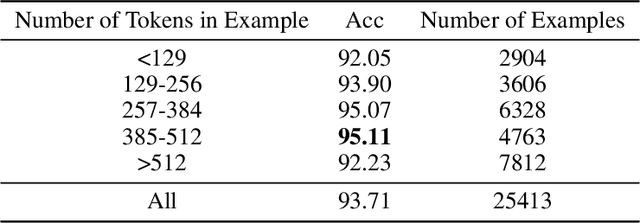
The exponential rise of social media and digital news in the past decade has had the unfortunate consequence of escalating what the United Nations has called a global topic of concern: the growing prevalence of disinformation. Given the complexity and time-consuming nature of combating disinformation through human assessment, one is motivated to explore harnessing AI solutions to automatically assess news articles for the presence of disinformation. A valuable first step towards automatic identification of disinformation is stance detection, where given a claim and a news article, the aim is to predict if the article agrees, disagrees, takes no position, or is unrelated to the claim. Existing approaches in literature have largely relied on hand-engineered features or shallow learned representations (e.g., word embeddings) to encode the claim-article pairs, which can limit the level of representational expressiveness needed to tackle the high complexity of disinformation identification. In this work, we explore the notion of harnessing large-scale deep bidirectional transformer language models for encoding claim-article pairs in an effort to construct state-of-the-art stance detection geared for identifying disinformation. Taking advantage of bidirectional cross-attention between claim-article pairs via pair encoding with self-attention, we construct a large-scale language model for stance detection by performing transfer learning on a RoBERTa deep bidirectional transformer language model, and were able to achieve state-of-the-art performance (weighted accuracy of 90.01%) on the Fake News Challenge Stage 1 (FNC-I) benchmark. These promising results serve as motivation for harnessing such large-scale language models as powerful building blocks for creating effective AI solutions to combat disinformation.
DeepLABNet: End-to-end Learning of Deep Radial Basis Networks with Fully Learnable Basis Functions
Nov 21, 2019
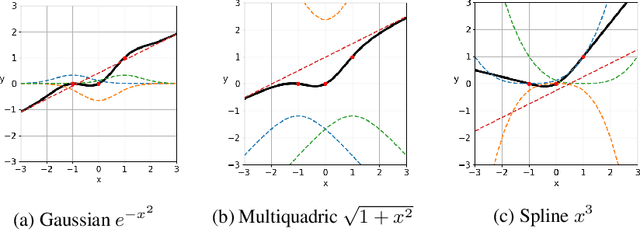

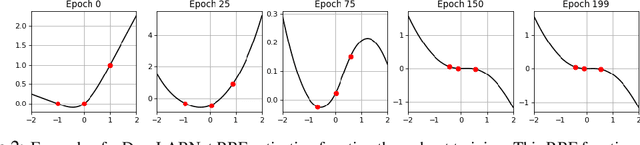
From fully connected neural networks to convolutional neural networks, the learned parameters within a neural network have been primarily relegated to the linear parameters (e.g., convolutional filters). The non-linear functions (e.g., activation functions) have largely remained, with few exceptions in recent years, parameter-less, static throughout training, and seen limited variation in design. Largely ignored by the deep learning community, radial basis function (RBF) networks provide an interesting mechanism for learning more complex non-linear activation functions in addition to the linear parameters in a network. However, the interest in RBF networks has waned over time due to the difficulty of integrating RBFs into more complex deep neural network architectures in a tractable and stable manner. In this work, we present a novel approach that enables end-to-end learning of deep RBF networks with fully learnable activation basis functions in an automatic and tractable manner. We demonstrate that our approach for enabling the use of learnable activation basis functions in deep neural networks, which we will refer to as DeepLABNet, is an effective tool for automated activation function learning within complex network architectures.
Do Explanations Reflect Decisions? A Machine-centric Strategy to Quantify the Performance of Explainability Algorithms
Oct 29, 2019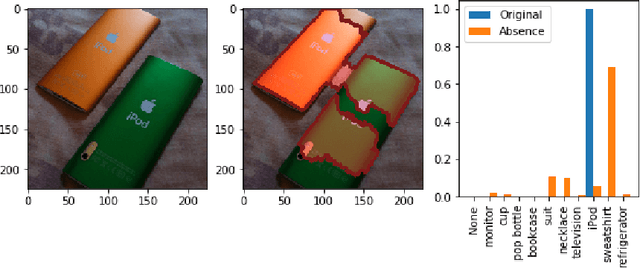
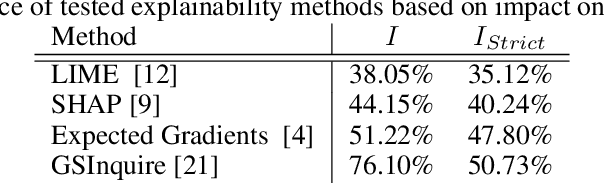
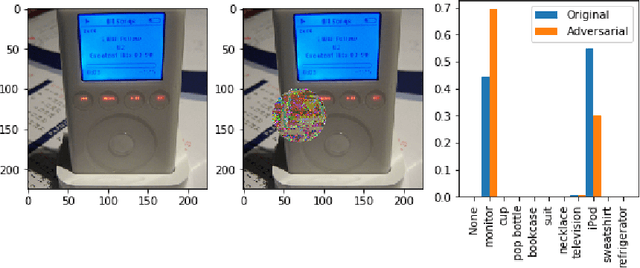

There has been a significant surge of interest recently around the concept of explainable artificial intelligence (XAI), where the goal is to produce an interpretation for a decision made by a machine learning algorithm. Of particular interest is the interpretation of how deep neural networks make decisions, given the complexity and `black box' nature of such networks. Given the infancy of the field, there has been very limited exploration into the assessment of the performance of explainability methods, with most evaluations centered around subjective visual interpretation of the produced interpretations. In this study, we explore a more machine-centric strategy for quantifying the performance of explainability methods on deep neural networks via the notion of decision-making impact analysis. We introduce two quantitative performance metrics: i) Impact Score, which assesses the percentage of critical factors with either strong confidence reduction impact or decision changing impact, and ii) Impact Coverage, which assesses the percentage coverage of adversarially impacted factors in the input. A comprehensive analysis using this approach was conducted on several state-of-the-art explainability methods (LIME, SHAP, Expected Gradients, GSInquire) on a ResNet-50 deep convolutional neural network using a subset of ImageNet for the task of image classification. Experimental results show that the critical regions identified by LIME within the tested images had the lowest impact on the decision-making process of the network (~38%), with progressive increase in decision-making impact for SHAP (~44%), Expected Gradients (~51%), and GSInquire (~76%). While by no means perfect, the hope is that the proposed machine-centric strategy helps push the conversation forward towards better metrics for evaluating explainability methods and improve trust in deep neural networks.
Fully-Automatic Semantic Segmentation for Food Intake Tracking in Long-Term Care Homes
Oct 24, 2019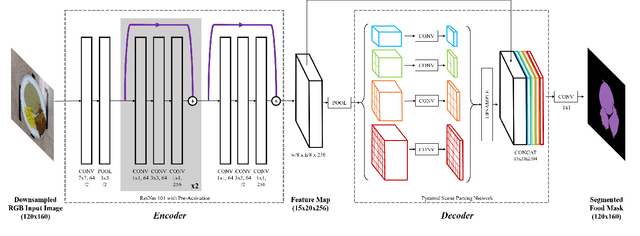
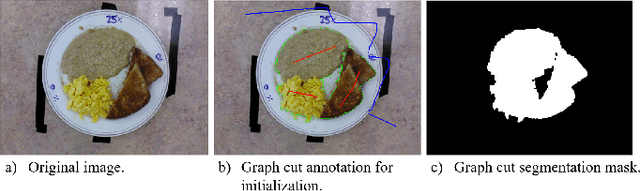

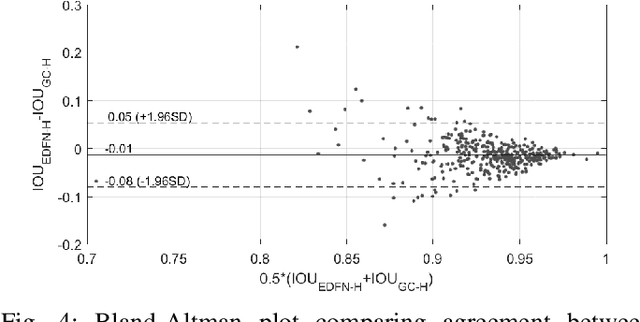
Malnutrition impacts quality of life and places annually-recurring burden on the health care system. Half of older adults are at risk for malnutrition in long-term care (LTC). Monitoring and measuring nutritional intake is paramount yet involves time-consuming and subjective visual assessment, limiting current methods' reliability. The opportunity for automatic image-based estimation exists. Some progress outside LTC has been made (e.g., calories consumed, food classification), however, these methods have not been implemented in LTC, potentially due to a lack of ability to independently evaluate automatic segmentation methods within the intake estimation pipeline. Here, we propose and evaluate a novel fully-automatic semantic segmentation method for pixel-level classification of food on a plate using a deep convolutional neural network (DCNN). The macroarchitecture of the DCNN is a multi-scale encoder-decoder food network (EDFN) architecture comprising a residual encoder microarchitecture, a pyramid scene parsing decoder microarchitecture, and a specialized per-pixel food/no-food classification layer. The network was trained and validated on the pre-labelled UNIMIB 2016 food dataset (1027 tray images, 73 categories), and tested on our novel LTC plate dataset (390 plate images, 9 categories). Our fully-automatic segmentation method attained similar intersection over union to the semi-automatic graph cuts (91.2% vs. 93.7%). Advantages of our proposed system include: testing on a novel dataset, decoupled error analysis, no user-initiated annotations, with similar segmentation accuracy and enhanced reliability in terms of types of segmentation errors. This may address several short-comings currently limiting utility of automated food intake tracking in time-constrained LTC and hospital settings.
State of Compact Architecture Search For Deep Neural Networks
Oct 15, 2019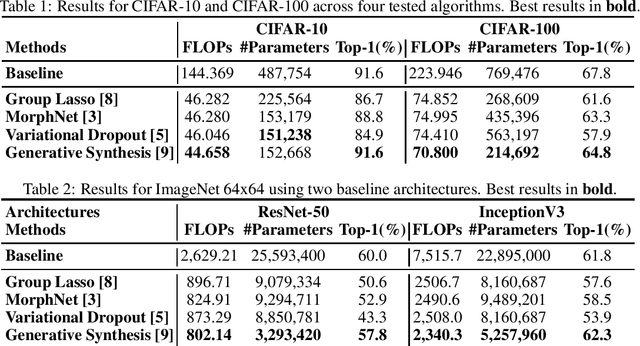
The design of compact deep neural networks is a crucial task to enable widespread adoption of deep neural networks in the real-world, particularly for edge and mobile scenarios. Due to the time-consuming and challenging nature of manually designing compact deep neural networks, there has been significant recent research interest into algorithms that automatically search for compact network architectures. A particularly interesting class of compact architecture search algorithms are those that are guided by baseline network architectures. Such algorithms have been shown to be significantly more computationally efficient than unguided methods. In this study, we explore the current state of compact architecture search for deep neural networks through both theoretical and empirical analysis of four different state-of-the-art compact architecture search algorithms: i) group lasso regularization, ii) variational dropout, iii) MorphNet, and iv) Generative Synthesis. We examine these methods in detail based on a number of different factors such as efficiency, effectiveness, and scalability. Furthermore, empirical evaluations are conducted to compare the efficacy of these compact architecture search algorithms across three well-known benchmark datasets. While by no means an exhaustive exploration, we hope that this study helps provide insights into the interesting state of this relatively new area of research in terms of diversity and real, tangible gains already achieved in architecture design improvements. Furthermore, the hope is that this study would help in pushing the conversation forward towards a deeper theoretical and empirical understanding where the research community currently stands in the landscape of compact architecture search for deep neural networks, and the practical challenges and considerations in leveraging such approaches for operational usage.
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019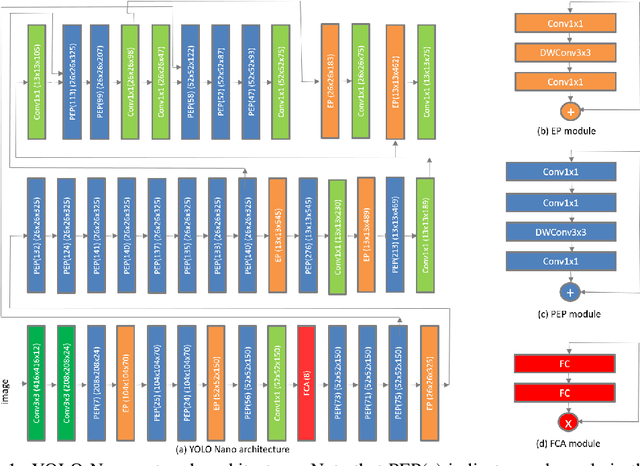
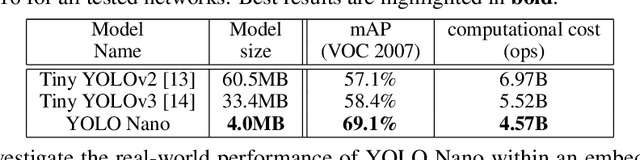
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
Human-Machine Collaborative Design for Accelerated Design of Compact Deep Neural Networks for Autonomous Driving
Sep 12, 2019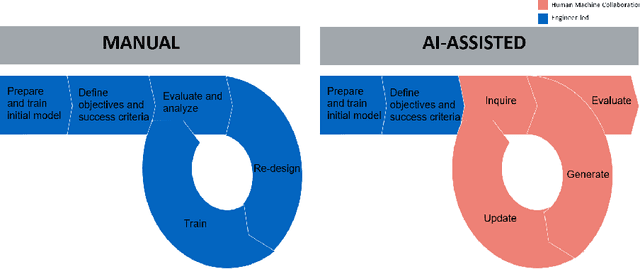

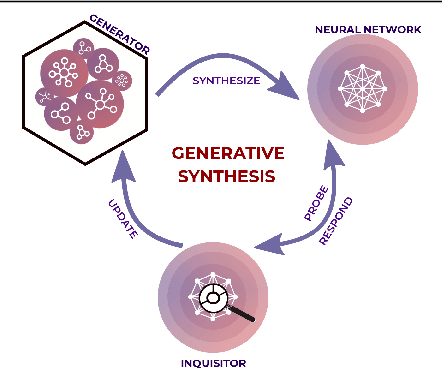
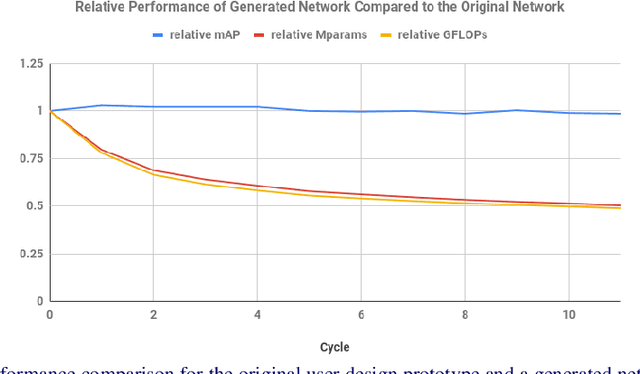
An effective deep learning development process is critical for widespread industrial adoption, particularly in the automotive sector. A typical industrial deep learning development cycle involves customizing and re-designing an off-the-shelf network architecture to meet the operational requirements of the target application, leading to considerable trial and error work by a machine learning practitioner. This approach greatly impedes development with a long turnaround time and the unsatisfactory quality of the created models. As a result, a development platform that can aid engineers in greatly accelerating the design and production of compact, optimized deep neural networks is highly desirable. In this joint industrial case study, we study the efficacy of the GenSynth AI-assisted AI design platform for accelerating the design of custom, optimized deep neural networks for autonomous driving through human-machine collaborative design. We perform a quantitative examination by evaluating 10 different compact deep neural networks produced by GenSynth for the purpose of object detection via a NASNet-based user network prototype design, targeted at a low-cost GPU-based accelerated embedded system. Furthermore, we quantitatively assess the talent hours and GPU processing hours used by the GenSynth process and three other approaches based on the typical industrial development process. In addition, we quantify the annual cloud cost savings for comprehensive testing using networks produced by GenSynth. Finally, we assess the usability and merits of the GenSynth process through user feedback. The findings of this case study showed that GenSynth is easy to use and can be effective at accelerating the design and production of compact, customized deep neural network.
Squeeze-and-Attention Networks for Semantic Segmentation
Sep 10, 2019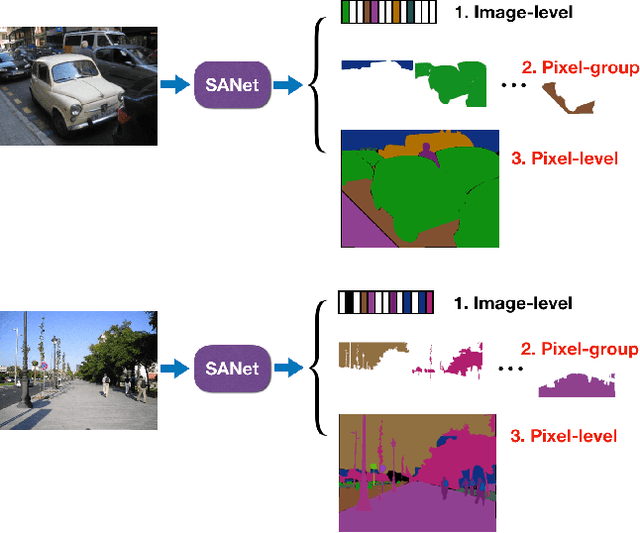
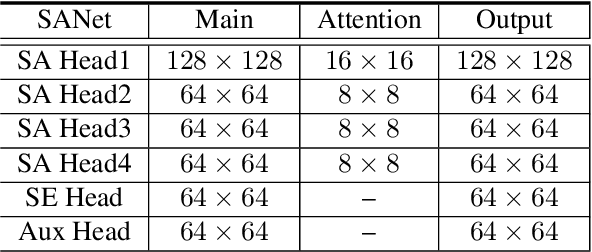

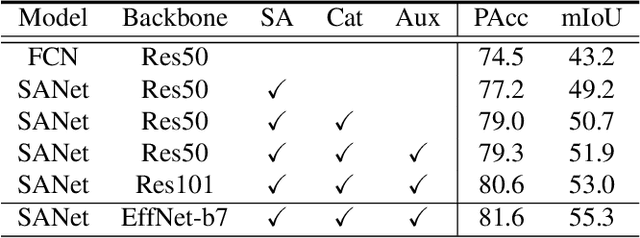
Squeeze-and-excitation (SE) module enhances the representational power of convolution layers by adaptively re-calibrating channel-wise feature responses. However, the limitation of SE in terms of attention characterization lies in the loss of spatial information cues, making it less well suited for perception tasks with very high spatial inter-dependencies such as semantic segmentation. In this paper, we propose a novel squeeze-and-attention network (SANet) architecture that leverages a simple but effective squeeze-and-attention (SA) module to account for two distinctive characteristics of segmentation: i) pixel-group attention, and ii) pixel-wise prediction. Specifically, the proposed SA modules impose pixel-group attention on conventional convolution by introducing an 'attention' convolutional channel, thus taking into account spatial-channel inter-dependencies in an efficient manner. The final segmentation results are produced by merging outputs from four hierarchical stages of a SANet to integrate multi-scale contexts for obtaining enhanced pixel-wise prediction. Empirical experiments using two challenging public datasets validate the effectiveness of the proposed SANets, which achieved 83.2% mIoU (without COCO pre-training) on PASCAL VOC and a state-of-the-art mIoU of 54.4% on PASCAL Context.