 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlierNets: Highly Compact Deep Autoencoder Network Architectures for On-Device Acoustic Anomaly Detection
Apr 19, 2021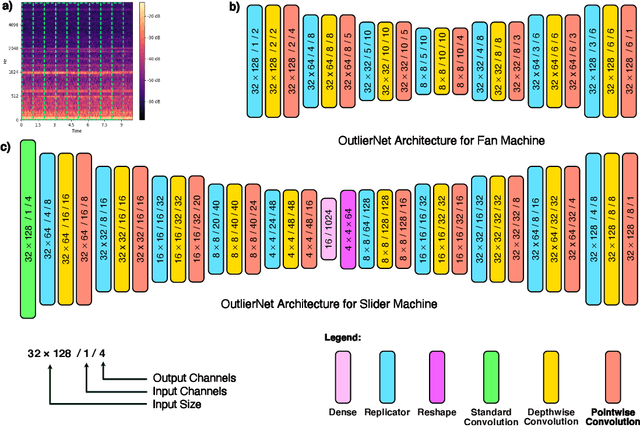
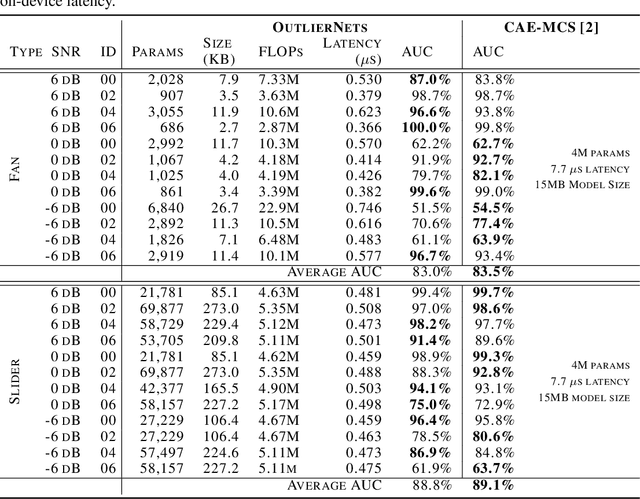
Human operators often diagnose industrial machinery via anomalous sounds. Automated acoustic anomaly detection can lead to reliable maintenance of machinery. However, deep learning-driven anomaly detection methods often require an extensive amount of computational resources which prohibits their deployment in factories. Here we explore a machine-driven design exploration strategy to create OutlierNets, a family of highly compact deep convolutional autoencoder network architectures featuring as few as 686 parameters, model sizes as small as 2.7 KB, and as low as 2.8 million FLOPs, with a detection accuracy matching or exceeding published architectures with as many as 4 million parameters. Furthermore, CPU-accelerated latency experiments show that the OutlierNet architectures can achieve as much as 21x lower latency than published networks.
TB-Net: A Tailored, Self-Attention Deep Convolutional Neural Network Design for Detection of Tuberculosis Cases from Chest X-ray Images
Apr 14, 2021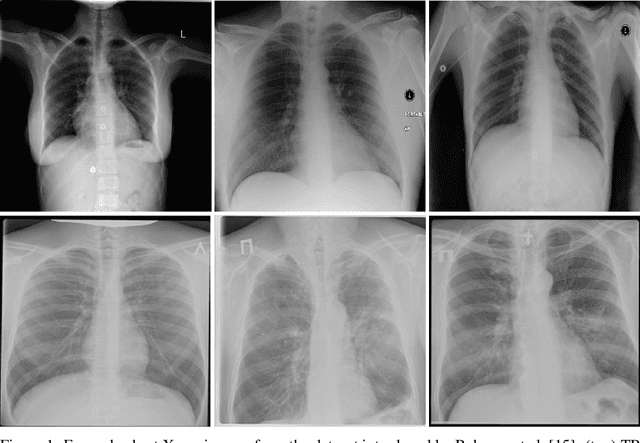
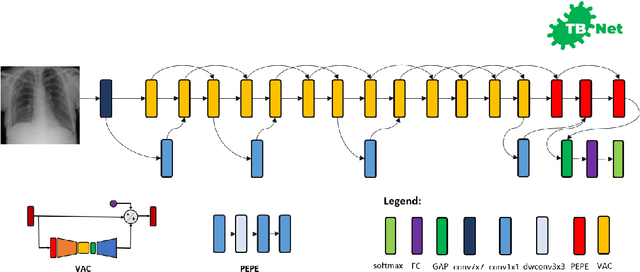
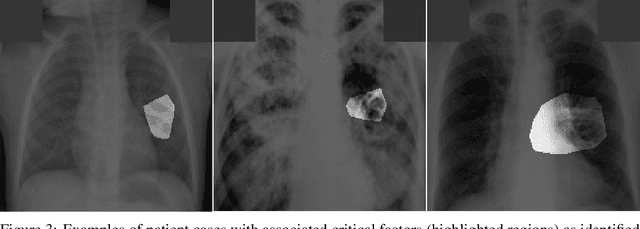
Tuberculosis (TB) remains a global health problem, and is the leading cause of death from an infectious disease. A crucial step in the treatment of tuberculosis is screening high risk populations and the early detection of the disease, with chest x-ray (CXR) imaging being the most widely-used imaging modality. As such, there has been significant recent interest in artificial intelligence-based TB screening solutions for use in resource-limited scenarios where there is a lack of trained healthcare workers with expertise in CXR interpretation. Motivated by this pressing need and the recent recommendation by the World Health Organization (WHO) for the use of computer-aided diagnosis of TB, we introduce TB-Net, a self-attention deep convolutional neural network tailored for TB case screening. More specifically, we leveraged machine-driven design exploration to build a highly customized deep neural network architecture with attention condensers. We conducted an explainability-driven performance validation process to validate TB-Net's decision-making behaviour. Experiments on CXR data from a multi-national patient cohort showed that the proposed TB-Net is able to achieve accuracy/sensitivity/specificity of 99.86%/100.0%/99.71%. Radiologist validation was conducted on select cases by two board-certified radiologists with over 10 and 19 years of experience, respectively, and showed consistency between radiologist interpretation and critical factors leveraged by TB-Net for TB case detection for the case where radiologists identified anomalies. While not a production-ready solution, we hope that the open-source release of TB-Net as part of the COVID-Net initiative will support researchers, clinicians, and citizen data scientists in advancing this field in the fight against this global public health crisis.
COVIDx-US -- An open-access benchmark dataset of ultrasound imaging data for AI-driven COVID-19 analytics
Mar 18, 2021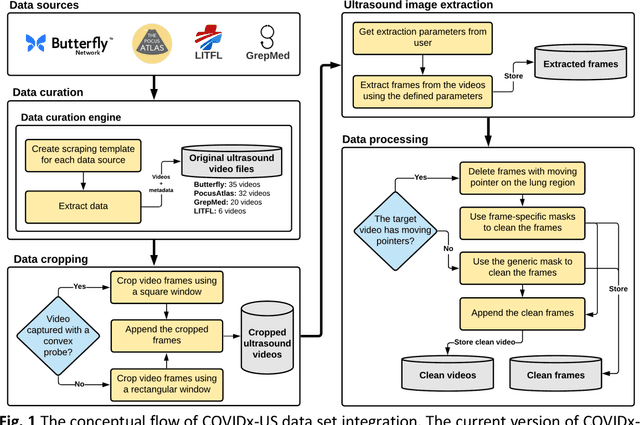
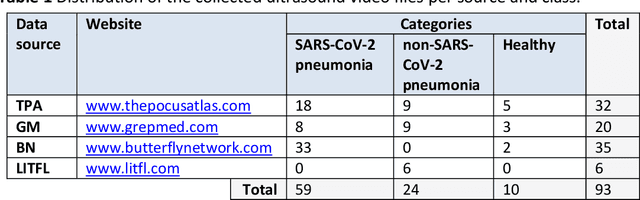
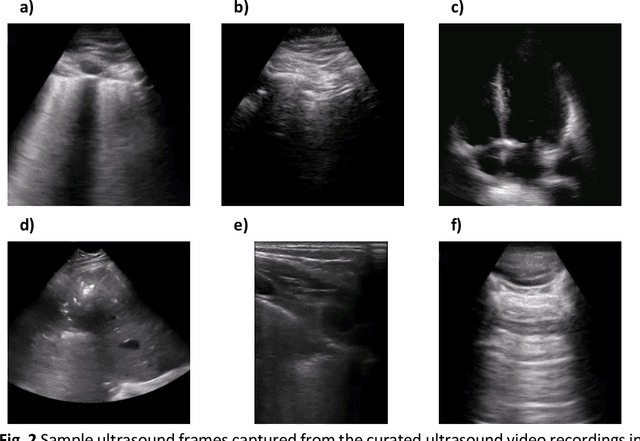
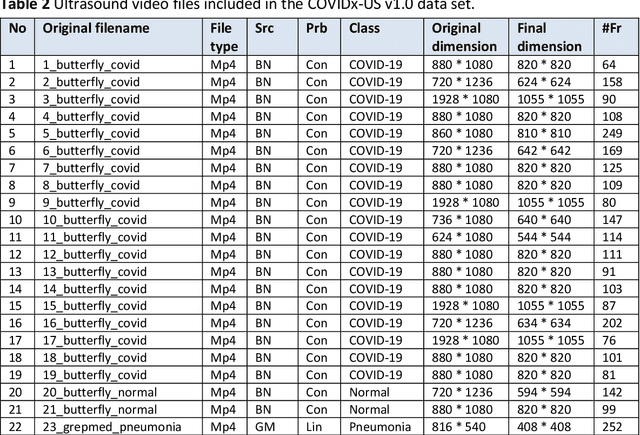
The COVID-19 pandemic continues to have a devastating effect on the health and well-being of the global population. Apart from the global health crises, the pandemic has also caused significant economic and financial difficulties and socio-physiological implications. Effective screening, triage, treatment planning, and prognostication of outcome plays a key role in controlling the pandemic. Recent studies have highlighted the role of point-of-care ultrasound imaging for COVID-19 screening and prognosis, particularly given that it is non-invasive, globally available, and easy-to-sanitize. Motivated by these attributes and the promise of artificial intelligence tools to aid clinicians, we introduce COVIDx-US, an open-access benchmark dataset of COVID-19 related ultrasound imaging data that is the largest of its kind. The COVIDx-US dataset was curated from multiple sources and consists of 93 lung ultrasound videos and 10,774 processed images of patients infected with SARS-CoV-2 pneumonia, non-SARS-CoV-2 pneumonia, as well as healthy control cases. The dataset was systematically processed and validated specifically for the purpose of building and evaluating artificial intelligence algorithms and models.
Fibrosis-Net: A Tailored Deep Convolutional Neural Network Design for Prediction of Pulmonary Fibrosis Progression from Chest CT Images
Mar 06, 2021
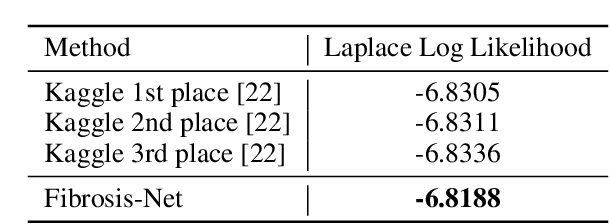
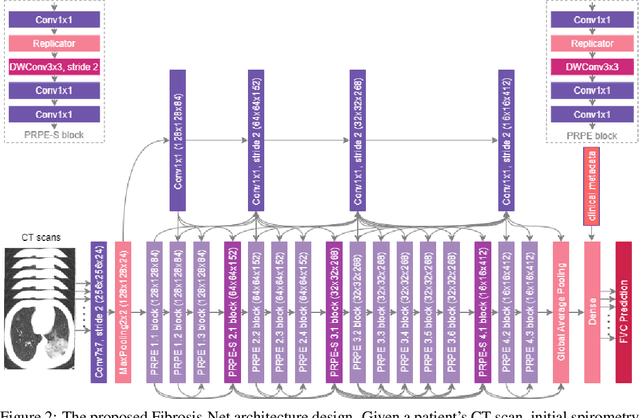
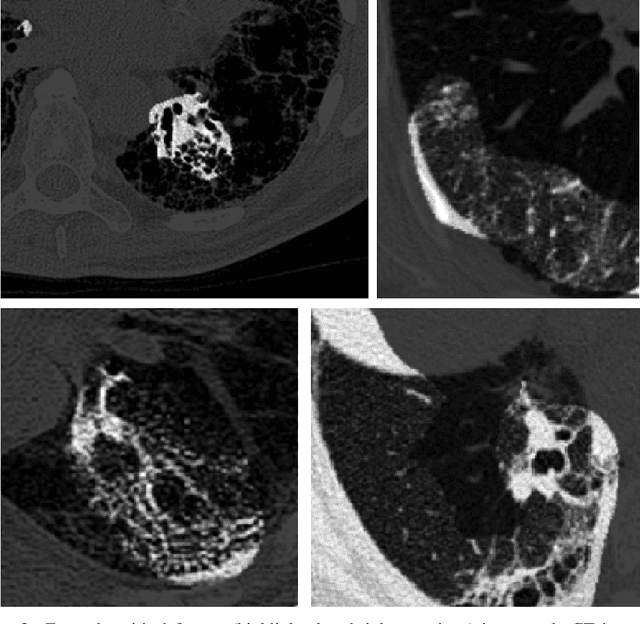
Pulmonary fibrosis is a devastating chronic lung disease that causes irreparable lung tissue scarring and damage, resulting in progressive loss in lung capacity and has no known cure. A critical step in the treatment and management of pulmonary fibrosis is the assessment of lung function decline, with computed tomography (CT) imaging being a particularly effective method for determining the extent of lung damage caused by pulmonary fibrosis. Motivated by this, we introduce Fibrosis-Net, a deep convolutional neural network design tailored for the prediction of pulmonary fibrosis progression from chest CT images. More specifically, machine-driven design exploration was leveraged to determine a strong architectural design for CT lung analysis, upon which we build a customized network design tailored for predicting forced vital capacity (FVC) based on a patient's CT scan, initial spirometry measurement, and clinical metadata. Finally, we leverage an explainability-driven performance validation strategy to study the decision-making behaviour of Fibrosis-Net as to verify that predictions are based on relevant visual indicators in CT images. Experiments using the OSIC Pulmonary Fibrosis Progression Challenge benchmark dataset showed that the proposed Fibrosis-Net is able to achieve a significantly higher modified Laplace Log Likelihood score than the winning solutions on the challenge leaderboard. Furthermore, explainability-driven performance validation demonstrated that the proposed Fibrosis-Net exhibits correct decision-making behaviour by leveraging clinically-relevant visual indicators in CT images when making predictions on pulmonary fibrosis progress. While Fibrosis-Net is not yet a production-ready clinical assessment solution, we hope that releasing the model in open source manner will encourage researchers, clinicians, and citizen data scientists alike to leverage and build upon it.
COVID-Net CT-2: Enhanced Deep Neural Networks for Detection of COVID-19 from Chest CT Images Through Bigger, More Diverse Learning
Jan 26, 2021

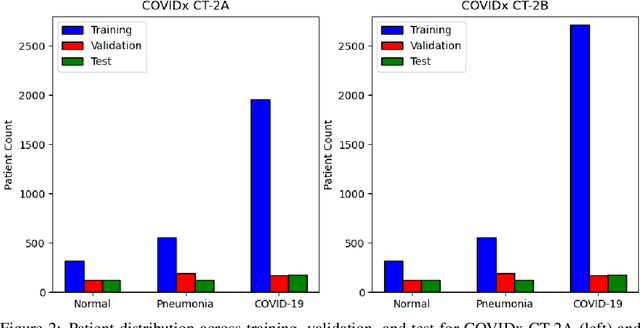
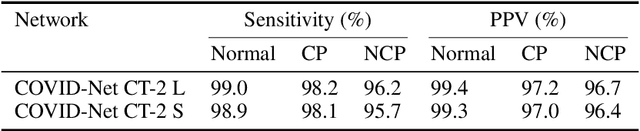
The COVID-19 pandemic continues to rage on, with multiple waves causing substantial harm to health and economies around the world. Motivated by the use of CT imaging at clinical institutes around the world as an effective complementary screening method to RT-PCR testing, we introduced COVID-Net CT, a neural network tailored for detection of COVID-19 cases from chest CT images as part of the open source COVID-Net initiative. However, one potential limiting factor is restricted quantity and diversity given the single nation patient cohort used. In this study, we introduce COVID-Net CT-2, enhanced deep neural networks for COVID-19 detection from chest CT images trained on the largest quantity and diversity of multinational patient cases in research literature. We introduce two new CT benchmark datasets, the largest comprising a multinational cohort of 4,501 patients from at least 15 countries. We leverage explainability to investigate the decision-making behaviour of COVID-Net CT-2, with the results for select cases reviewed and reported on by two board-certified radiologists with over 10 and 30 years of experience, respectively. The COVID-Net CT-2 neural networks achieved accuracy, COVID-19 sensitivity, PPV, specificity, and NPV of 98.1%/96.2%/96.7%/99%/98.8% and 97.9%/95.7%/96.4%/98.9%/98.7%, respectively. Explainability-driven performance validation shows that COVID-Net CT-2's decision-making behaviour is consistent with radiologist interpretation by leveraging correct, clinically relevant critical factors. The results are promising and suggest the strong potential of deep neural networks as an effective tool for computer-aided COVID-19 assessment. While not a production-ready solution, we hope the open-source, open-access release of COVID-Net CT-2 and benchmark datasets will continue to enable researchers, clinicians, and citizen data scientists alike to build upon them.
A Simple Fine-tuning Is All You Need: Towards Robust Deep Learning Via Adversarial Fine-tuning
Dec 25, 2020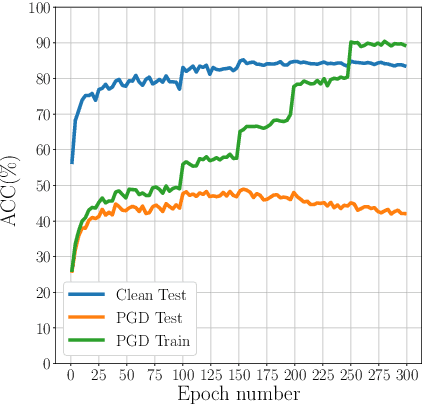
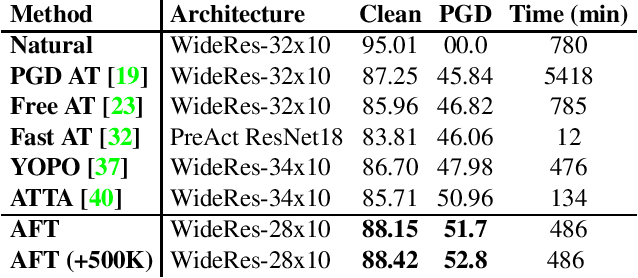
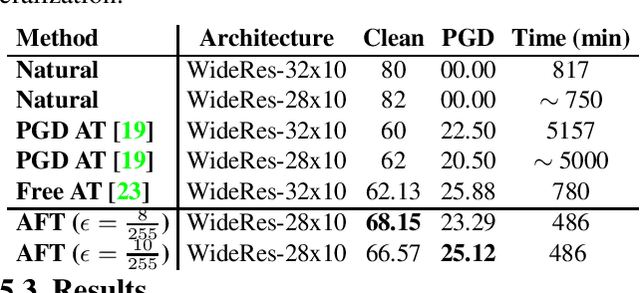
Adversarial Training (AT) with Projected Gradient Descent (PGD) is an effective approach for improving the robustness of the deep neural networks. However, PGD AT has been shown to suffer from two main limitations: i) high computational cost, and ii) extreme overfitting during training that leads to reduction in model generalization. While the effect of factors such as model capacity and scale of training data on adversarial robustness have been extensively studied, little attention has been paid to the effect of a very important parameter in every network optimization on adversarial robustness: the learning rate. In particular, we hypothesize that effective learning rate scheduling during adversarial training can significantly reduce the overfitting issue, to a degree where one does not even need to adversarially train a model from scratch but can instead simply adversarially fine-tune a pre-trained model. Motivated by this hypothesis, we propose a simple yet very effective adversarial fine-tuning approach based on a $\textit{slow start, fast decay}$ learning rate scheduling strategy which not only significantly decreases computational cost required, but also greatly improves the accuracy and robustness of a deep neural network. Experimental results show that the proposed adversarial fine-tuning approach outperforms the state-of-the-art methods on CIFAR-10, CIFAR-100 and ImageNet datasets in both test accuracy and the robustness, while reducing the computational cost by 8-10$\times$. Furthermore, a very important benefit of the proposed adversarial fine-tuning approach is that it enables the ability to improve the robustness of any pre-trained deep neural network without needing to train the model from scratch, which to the best of the authors' knowledge has not been previously demonstrated in research literature.
Inter-layer Information Similarity Assessment of Deep Neural Networks Via Topological Similarity and Persistence Analysis of Data Neighbour Dynamics
Dec 07, 2020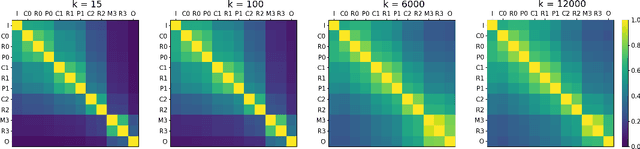
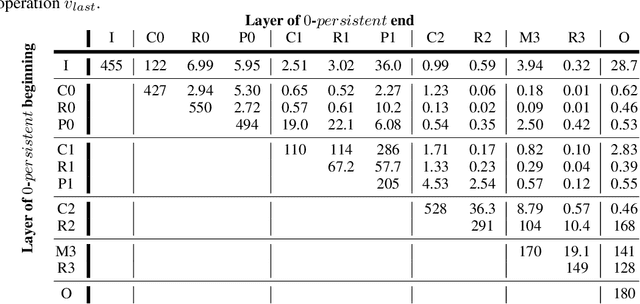
The quantitative analysis of information structure through a deep neural network (DNN) can unveil new insights into the theoretical performance of DNN architectures. Two very promising avenues of research towards quantitative information structure analysis are: 1) layer similarity (LS) strategies focused on the inter-layer feature similarity, and 2) intrinsic dimensionality (ID) strategies focused on layer-wise data dimensionality using pairwise information. Inspired by both LS and ID strategies for quantitative information structure analysis, we introduce two novel complimentary methods for inter-layer information similarity assessment premised on the interesting idea of studying a data sample's neighbourhood dynamics as it traverses through a DNN. More specifically, we introduce the concept of Nearest Neighbour Topological Similarity (NNTS) for quantifying the information topology similarity between layers of a DNN. Furthermore, we introduce the concept of Nearest Neighbour Topological Persistence (NNTP) for quantifying the inter-layer persistence of data neighbourhood relationships throughout a DNN. The proposed strategies facilitate the efficient inter-layer information similarity assessment by leveraging only local topological information, and we demonstrate their efficacy in this study by performing analysis on a deep convolutional neural network architecture on image data to study the insights that can be gained with respect to the theoretical performance of a DNN.
FactorizeNet: Progressive Depth Factorization for Efficient Network Architecture Exploration Under Quantization Constraints
Nov 30, 2020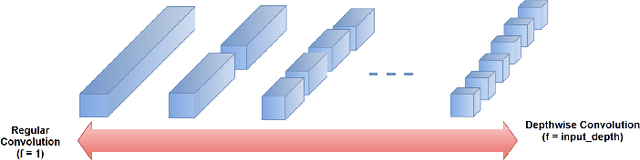
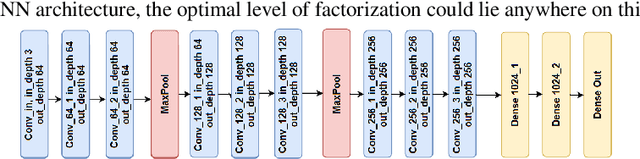
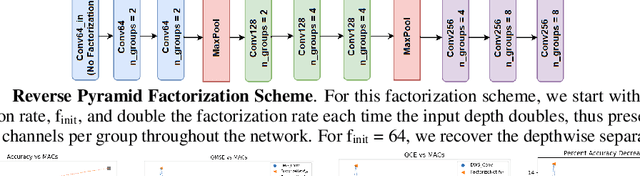
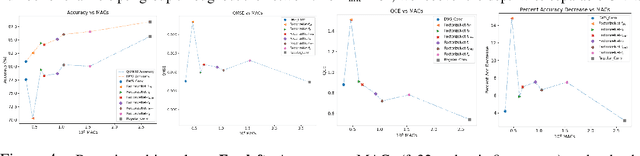
Depth factorization and quantization have emerged as two of the principal strategies for designing efficient deep convolutional neural network (CNN) architectures tailored for low-power inference on the edge. However, there is still little detailed understanding of how different depth factorization choices affect the final, trained distributions of each layer in a CNN, particularly in the situation of quantized weights and activations. In this study, we introduce a progressive depth factorization strategy for efficient CNN architecture exploration under quantization constraints. By algorithmically increasing the granularity of depth factorization in a progressive manner, the proposed strategy enables a fine-grained, low-level analysis of layer-wise distributions. Thus enabling the gain of in-depth, layer-level insights on efficiency-accuracy tradeoffs under fixed-precision quantization. Such a progressive depth factorization strategy also enables efficient identification of the optimal depth-factorized macroarchitecture design (which we will refer to here as FactorizeNet) based on the desired efficiency-accuracy requirements.
Where Should We Begin? A Low-Level Exploration of Weight Initialization Impact on Quantized Behaviour of Deep Neural Networks
Nov 30, 2020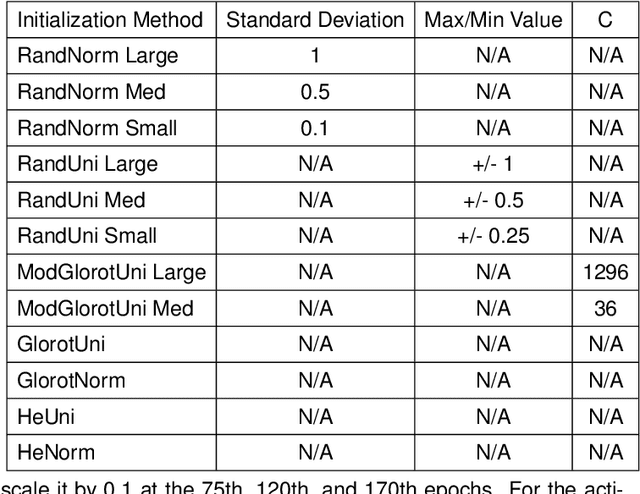
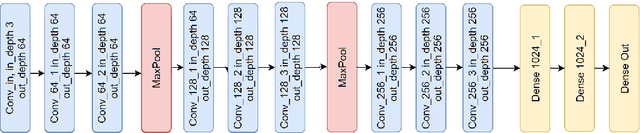
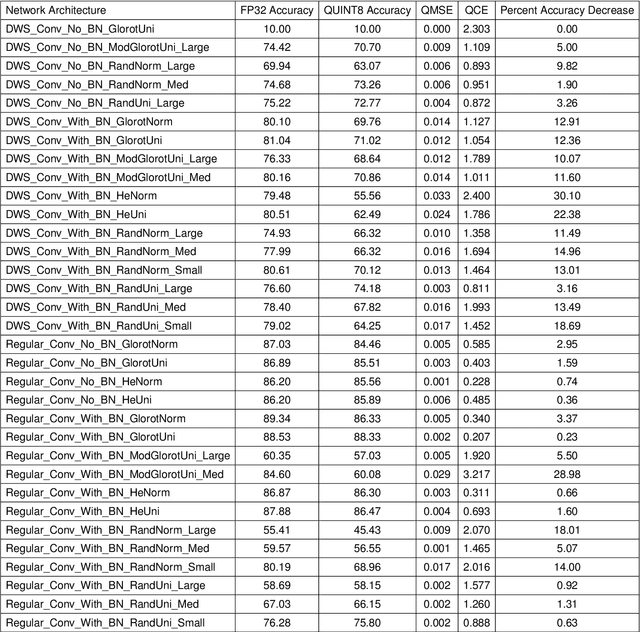
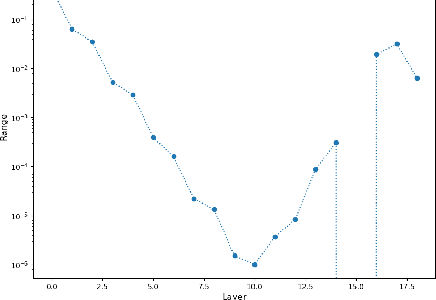
With the proliferation of deep convolutional neural network (CNN) algorithms for mobile processing, limited precision quantization has become an essential tool for CNN efficiency. Consequently, various works have sought to design fixed precision quantization algorithms and quantization-focused optimization techniques that minimize quantization induced performance degradation. However, there is little concrete understanding of how various CNN design decisions/best practices affect quantized inference behaviour. Weight initialization strategies are often associated with solving issues such as vanishing/exploding gradients but an often-overlooked aspect is their impact on the final trained distributions of each layer. We present an in-depth, fine-grained ablation study of the effect of different weights initializations on the final distributions of weights and activations of different CNN architectures. The fine-grained, layerwise analysis enables us to gain deep insights on how initial weights distributions will affect final accuracy and quantized behaviour. To our best knowledge, we are the first to perform such a low-level, in-depth quantitative analysis of weights initialization and its effect on quantized behaviour.
CancerNet-SCa: Tailored Deep Neural Network Designs for Detection of Skin Cancer from Dermoscopy Images
Nov 21, 2020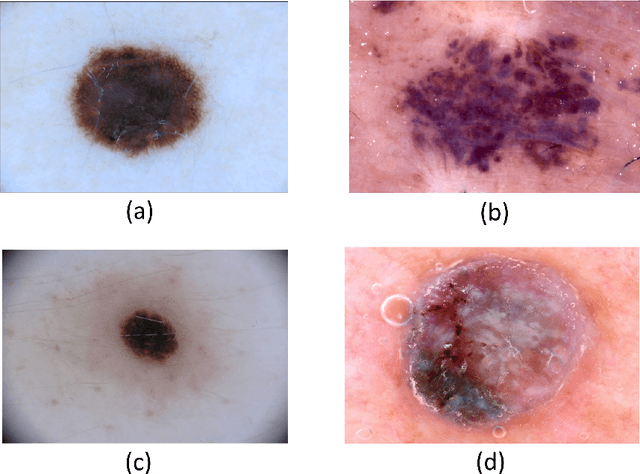
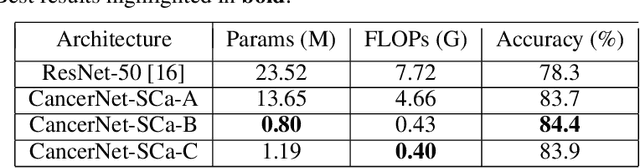
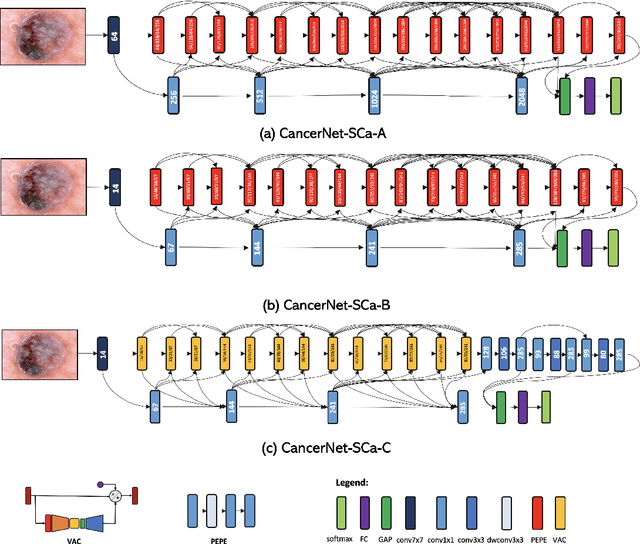
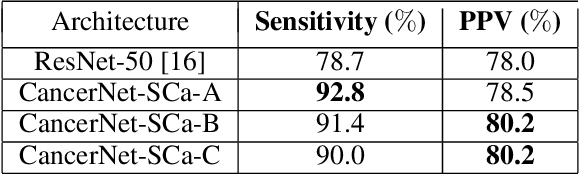
Skin cancer continues to be the most frequently diagnosed form of cancer in the U.S., with not only significant effects on health and well-being but also significant economic costs associated with treatment. A crucial step to the treatment and management of skin cancer is effective skin cancer detection due to strong prognosis when treated at an early stage, with one of the key screening approaches being dermoscopy examination. Motivated by the advances of deep learning and inspired by the open source initiatives in the research community, in this study we introduce CancerNet-SCa, a suite of deep neural network designs tailored for the detection of skin cancer from dermoscopy images that is open source and available to the general public as part of the Cancer-Net initiative. To the best of the authors' knowledge, CancerNet-SCa comprises of the first machine-designed deep neural network architecture designs tailored specifically for skin cancer detection, one of which possessing a self-attention architecture design with attention condensers. Furthermore, we investigate and audit the behaviour of CancerNet-SCa in a responsible and transparent manner via explainability-driven model auditing. While CancerNet-SCa is not a production-ready screening solution, the hope is that the release of CancerNet-SCa in open source, open access form will encourage researchers, clinicians, and citizen data scientists alike to leverage and build upon them.