 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive machine learning for prescriptive applications: a coupled training-validating approach
Oct 22, 2021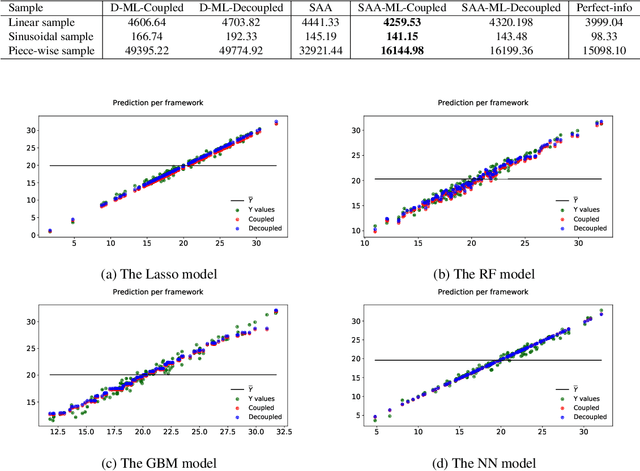


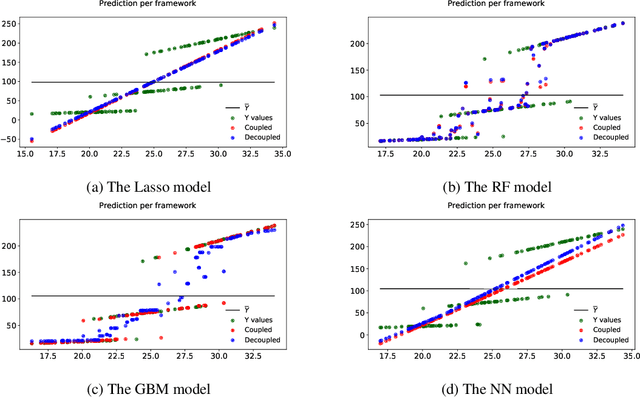
In this research we propose a new method for training predictive machine learning models for prescriptive applications. This approach, which we refer to as coupled validation, is based on tweaking the validation step in the standard training-validating-testing scheme. Specifically, the coupled method considers the prescription loss as the objective for hyper-parameter calibration. This method allows for intelligent introduction of bias in the prediction stage to improve decision making at the prescriptive stage, and is generally applicable to most machine learning methods, including recently proposed hybrid prediction-stochastic-optimization techniques, and can be easily implemented without model-specific mathematical modeling. Several experiments with synthetic and real data demonstrate promising results in reducing the prescription costs in both deterministic and stochastic models.
Benchmarking Graph Neural Networks on Link Prediction
Feb 24, 2021
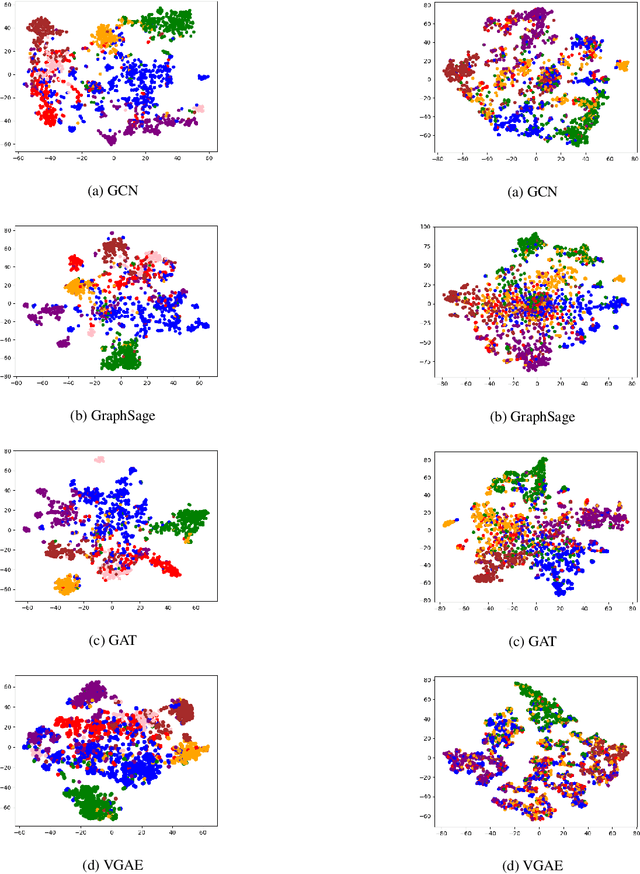

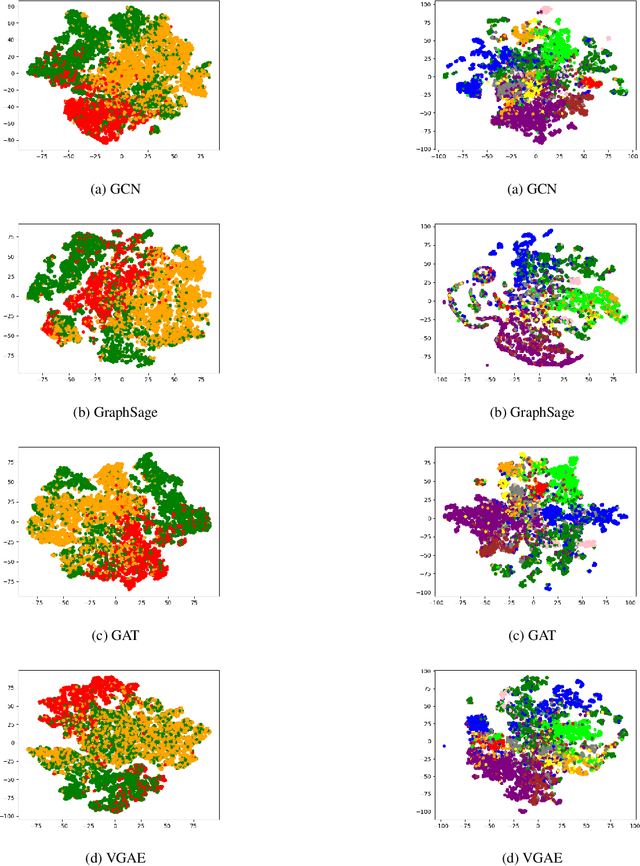
In this paper, we benchmark several existing graph neural network (GNN) models on different datasets for link predictions. In particular, the graph convolutional network (GCN), GraphSAGE, graph attention network (GAT) as well as variational graph auto-encoder (VGAE) are implemented dedicated to link prediction tasks, in-depth analysis are performed, and results from several different papers are replicated, also a more fair and systematic comparison are provided. Our experiments show these GNN architectures perform similarly on various benchmarks for link prediction tasks.
Reannealing of Decaying Exploration Based On Heuristic Measure in Deep Q-Network
Sep 29, 2020
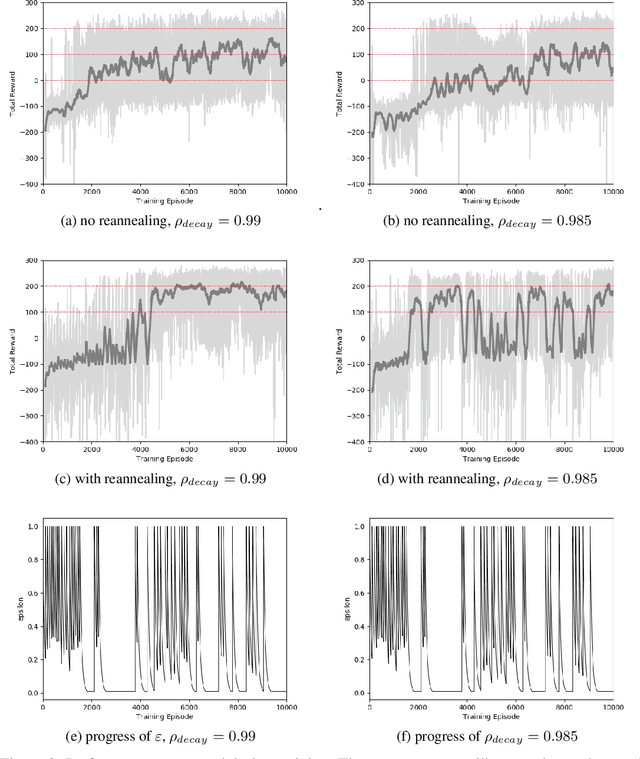
Existing exploration strategies in reinforcement learning (RL) often either ignore the history or feedback of search, or are complicated to implement. There is also a very limited literature showing their effectiveness over diverse domains. We propose an algorithm based on the idea of reannealing, that aims at encouraging exploration only when it is needed, for example, when the algorithm detects that the agent is stuck in a local optimum. The approach is simple to implement. We perform an illustrative case study showing that it has potential to both accelerate training and obtain a better policy.
Cross Learning in Deep Q-Networks
Sep 29, 2020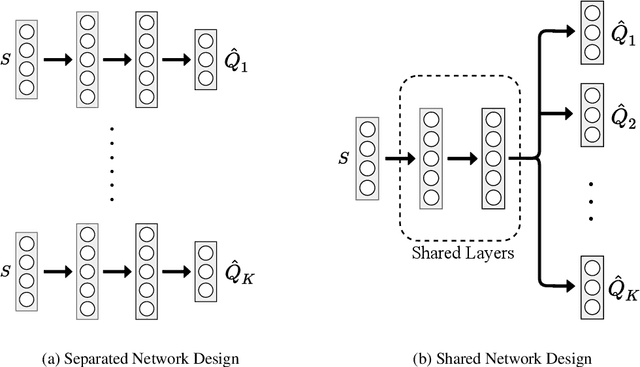
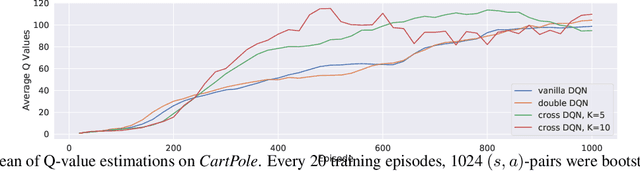
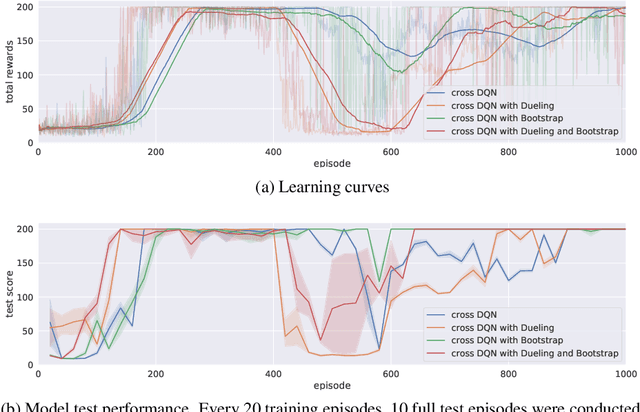
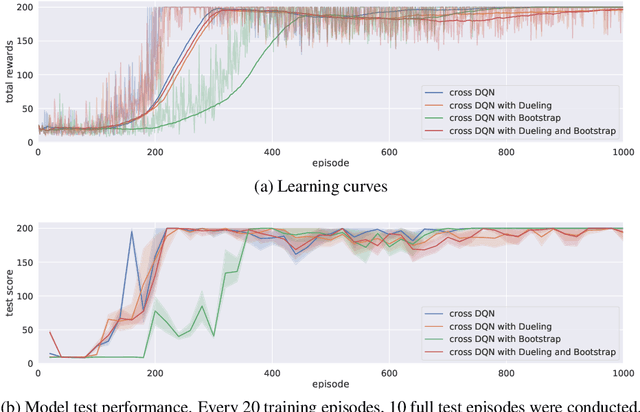
In this work, we propose a novel cross Q-learning algorithm, aim at alleviating the well-known overestimation problem in value-based reinforcement learning methods, particularly in the deep Q-networks where the overestimation is exaggerated by function approximation errors. Our algorithm builds on double Q-learning, by maintaining a set of parallel models and estimate the Q-value based on a randomly selected network, which leads to reduced overestimation bias as well as the variance. We provide empirical evidence on the advantages of our method by evaluating on some benchmark environment, the experimental results demonstrate significant improvement of performance in reducing the overestimation bias and stabilizing the training, further leading to better derived policies.