 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScream Detection in Heavy Metal Music
May 11, 2022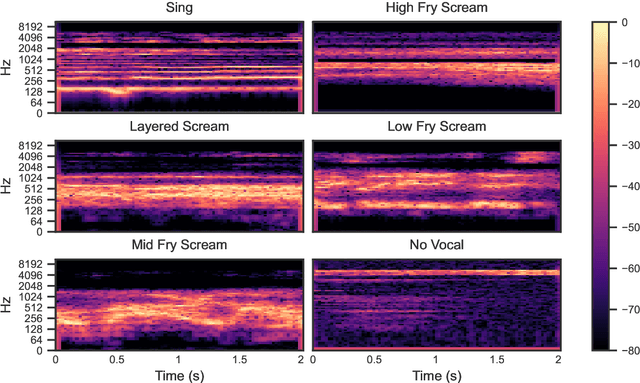
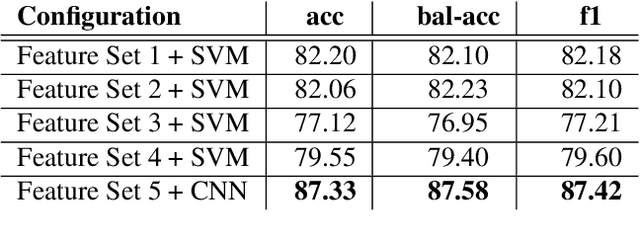
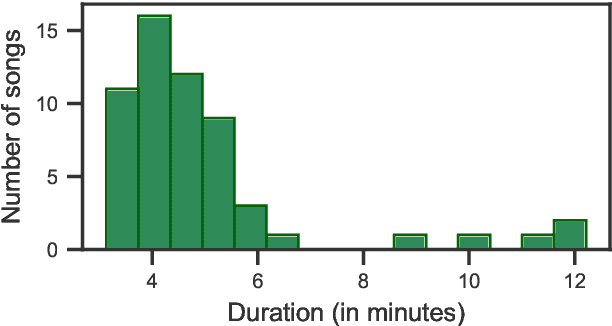
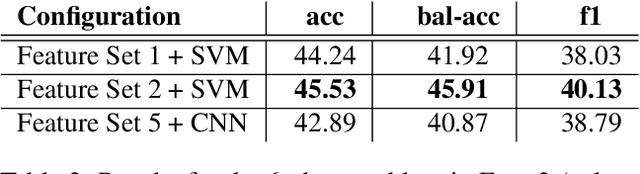
Harsh vocal effects such as screams or growls are far more common in heavy metal vocals than the traditionally sung vocal. This paper explores the problem of detection and classification of extreme vocal techniques in heavy metal music, specifically the identification of different scream techniques. We investigate the suitability of various feature representations, including cepstral, spectral, and temporal features as input representations for classification. The main contributions of this work are (i) a manually annotated dataset comprised of over 280 minutes of heavy metal songs of various genres with a statistical analysis of occurrences of different extreme vocal techniques in heavy metal music, and (ii) a systematic study of different input feature representations for the classification of heavy metal vocals
Feature-informed Latent Space Regularization for Music Source Separation
Mar 17, 2022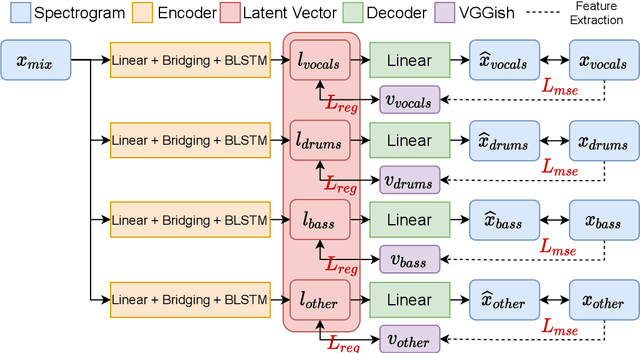
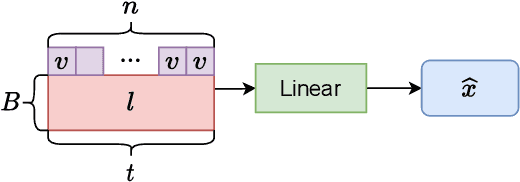
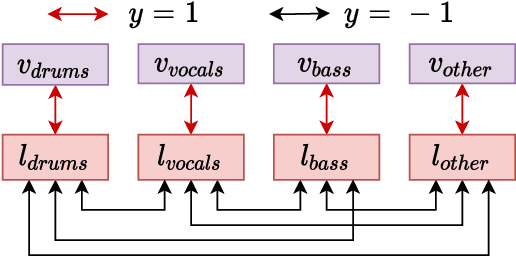
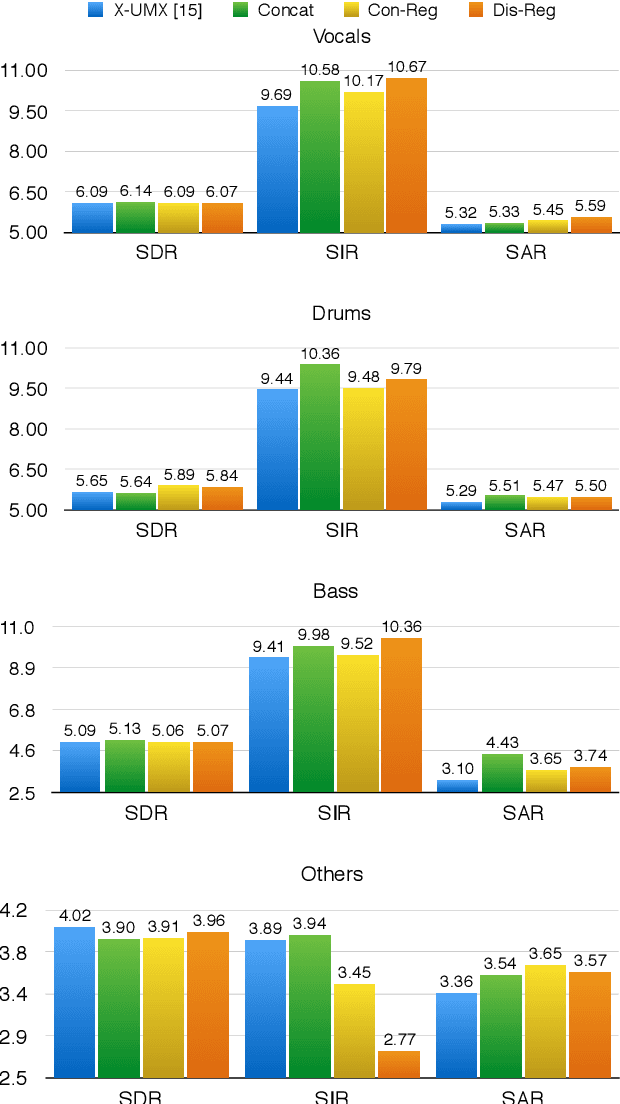
The integration of additional side information to improve music source separation has been investigated numerous times, e.g., by adding features to the input or by adding learning targets in a multi-task learning scenario. These approaches, however, require additional annotations such as musical scores, instrument labels, etc. in training and possibly during inference. The available datasets for source separation do not usually provide these additional annotations. In this work, we explore transfer learning strategies to incorporate VGGish features with a state-of-the-art source separation model; VGGish features are known to be a very condensed representation of audio content and have been successfully used in many MIR tasks. We introduce three approaches to incorporate the features, including two latent space regularization methods and one naive concatenation method. Experimental results show that our proposed approaches improve several evaluation metrics for music source separation.
Latte: Cross-framework Python Package for Evaluation of Latent-Based Generative Models
Jan 22, 2022

Latte (for LATent Tensor Evaluation) is a Python library for evaluation of latent-based generative models in the fields of disentanglement learning and controllable generation. Latte is compatible with both PyTorch and TensorFlow/Keras, and provides both functional and modular APIs that can be easily extended to support other deep learning frameworks. Using NumPy-based and framework-agnostic implementation, Latte ensures reproducible, consistent, and deterministic metric calculations regardless of the deep learning framework of choice.
Semi-Supervised Audio Classification with Partially Labeled Data
Nov 24, 2021
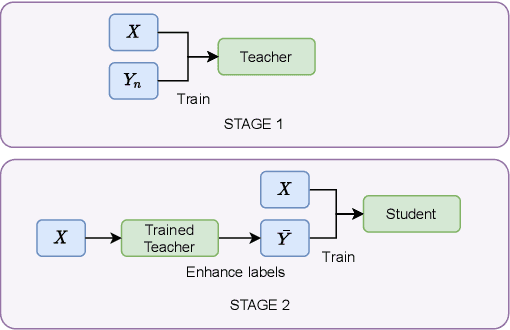
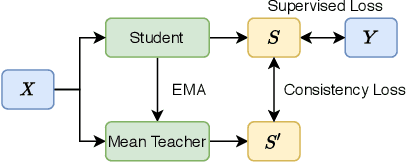
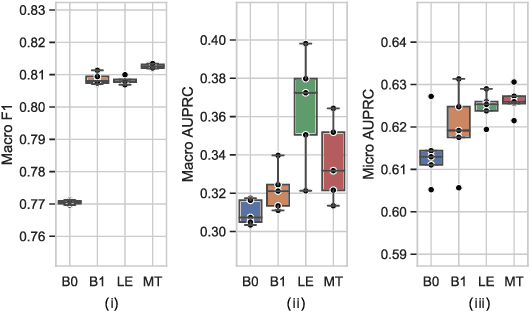
Audio classification has seen great progress with the increasing availability of large-scale datasets. These large datasets, however, are often only partially labeled as collecting full annotations is a tedious and expensive process. This paper presents two semi-supervised methods capable of learning with missing labels and evaluates them on two publicly available, partially labeled datasets. The first method relies on label enhancement by a two-stage teacher-student learning process, while the second method utilizes the mean teacher semi-supervised learning algorithm. Our results demonstrate the impact of improperly handling missing labels and compare the benefits of using different strategies leveraging data with few labels. Methods capable of learning with partially labeled data have the potential to improve models for audio classification by utilizing even larger amounts of data without the need for complete annotations.
Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes
Oct 11, 2021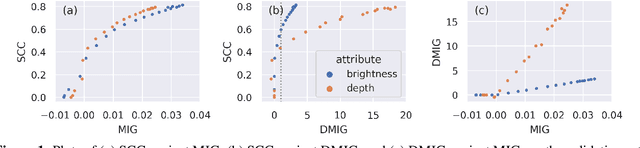
Controllable music generation with deep generative models has become increasingly reliant on disentanglement learning techniques. However, current disentanglement metrics, such as mutual information gap (MIG), are often inadequate and misleading when used for evaluating latent representations in the presence of interdependent semantic attributes often encountered in real-world music datasets. In this work, we propose a dependency-aware information metric as a drop-in replacement for MIG that accounts for the inherent relationship between semantic attributes.
Improving Music Performance Assessment with Contrastive Learning
Aug 03, 2021
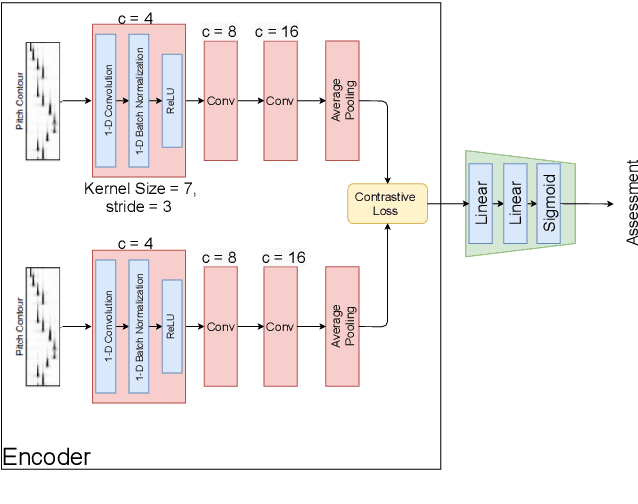
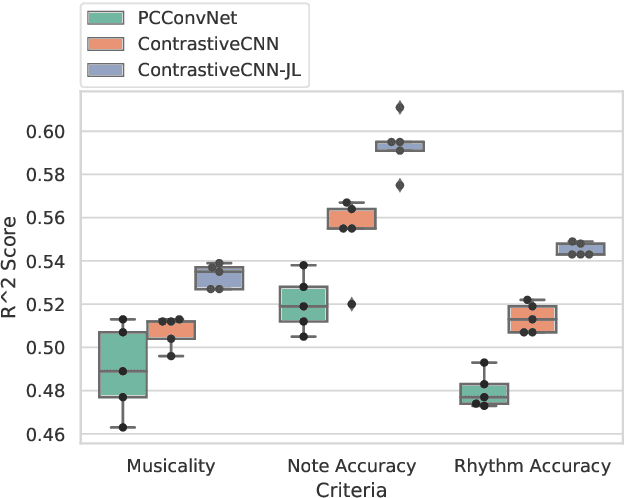
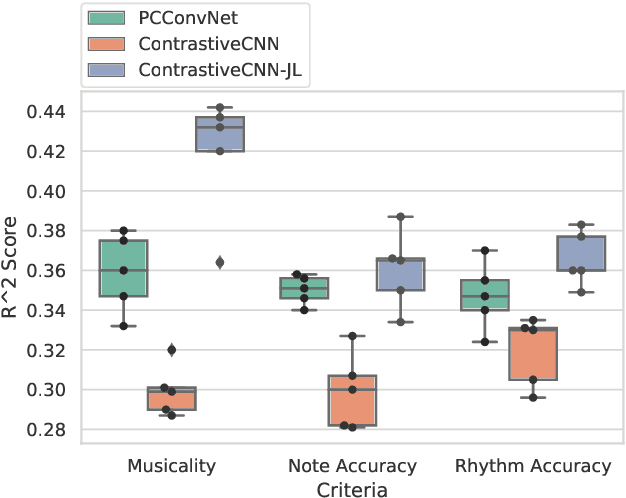
Several automatic approaches for objective music performance assessment (MPA) have been proposed in the past, however, existing systems are not yet capable of reliably predicting ratings with the same accuracy as professional judges. This study investigates contrastive learning as a potential method to improve existing MPA systems. Contrastive learning is a widely used technique in representation learning to learn a structured latent space capable of separately clustering multiple classes. It has been shown to produce state of the art results for image-based classification problems. We introduce a weighted contrastive loss suitable for regression tasks applied to a convolutional neural network and show that contrastive loss results in performance gains in regression tasks for MPA. Our results show that contrastive-based methods are able to match and exceed SoTA performance for MPA regression tasks by creating better class clusters within the latent space of the neural networks.
Is Disentanglement enough? On Latent Representations for Controllable Music Generation
Aug 01, 2021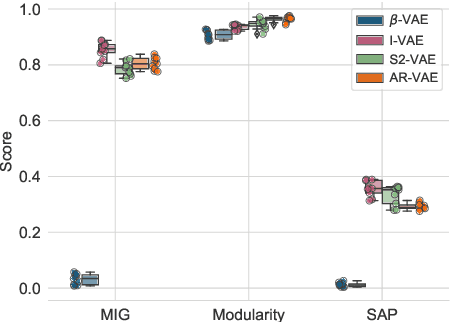
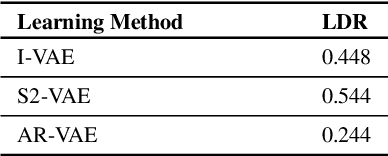
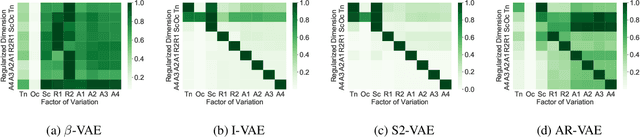
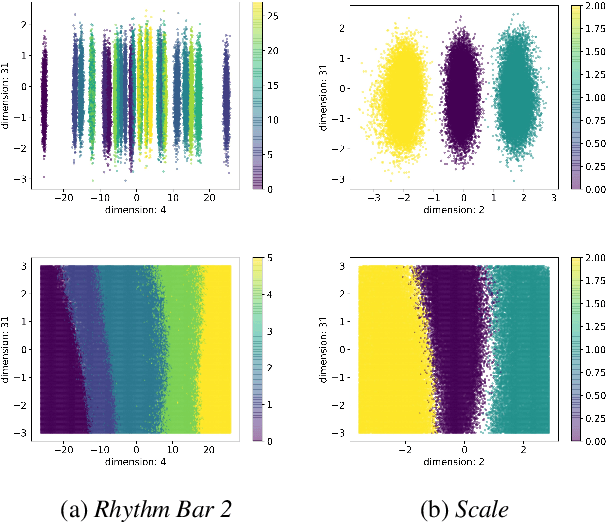
Improving controllability or the ability to manipulate one or more attributes of the generated data has become a topic of interest in the context of deep generative models of music. Recent attempts in this direction have relied on learning disentangled representations from data such that the underlying factors of variation are well separated. In this paper, we focus on the relationship between disentanglement and controllability by conducting a systematic study using different supervised disentanglement learning algorithms based on the Variational Auto-Encoder (VAE) architecture. Our experiments show that a high degree of disentanglement can be achieved by using different forms of supervision to train a strong discriminative encoder. However, in the absence of a strong generative decoder, disentanglement does not necessarily imply controllability. The structure of the latent space with respect to the VAE-decoder plays an important role in boosting the ability of a generative model to manipulate different attributes. To this end, we also propose methods and metrics to help evaluate the quality of a latent space with respect to the afforded degree of controllability.
An Interdisciplinary Review of Music Performance Analysis
Apr 19, 2021
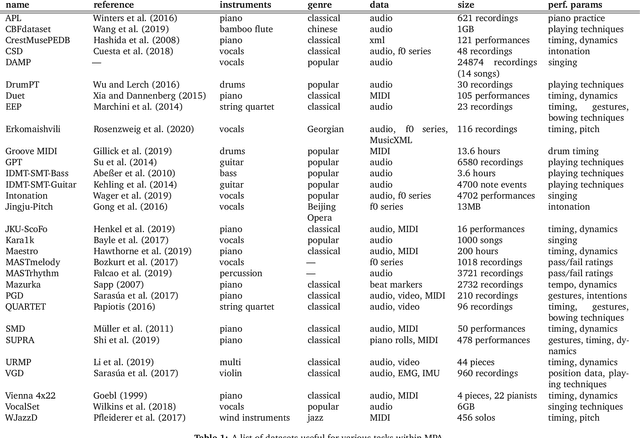
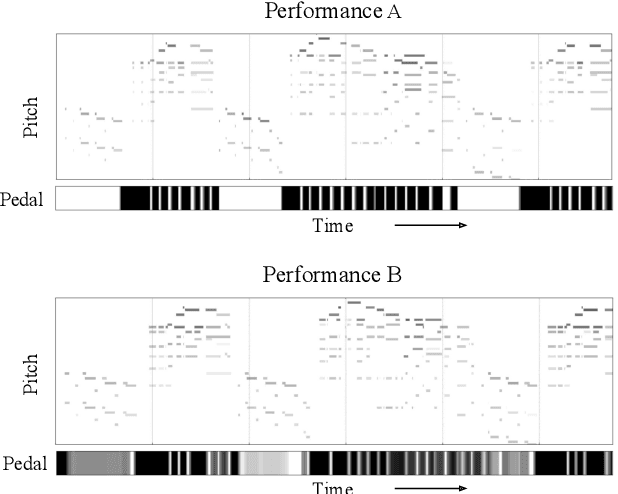
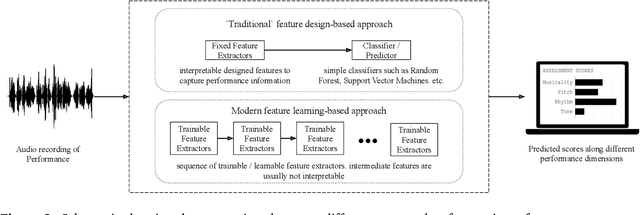
A musical performance renders an acoustic realization of a musical score or other representation of a composition. Different performances of the same composition may vary in terms of performance parameters such as timing or dynamics, and these variations may have a major impact on how a listener perceives the music. The analysis of music performance has traditionally been a peripheral topic for the MIR research community, where often a single audio recording is used as representative of a musical work. This paper surveys the field of Music Performance Analysis (MPA) from several perspectives including the measurement of performance parameters, the relation of those parameters to the actions and intentions of a performer or perceptual effects on a listener, and finally the assessment of musical performance. This paper also discusses MPA as it relates to MIR, pointing out opportunities for collaboration and future research in both areas.
* arXiv admin note: substantial text overlap with arXiv:1907.00178
Mind the beat: detecting audio onsets from EEG recordings of music listening
Feb 12, 2021
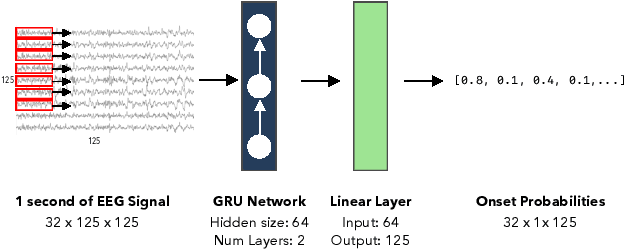
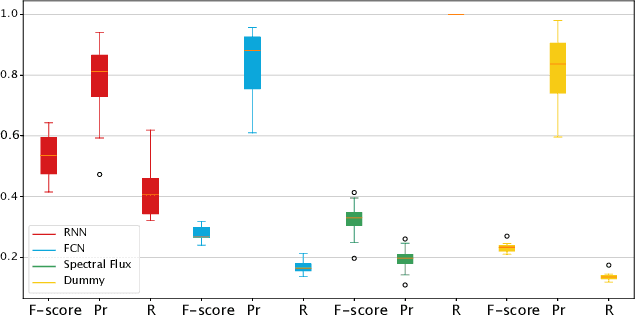
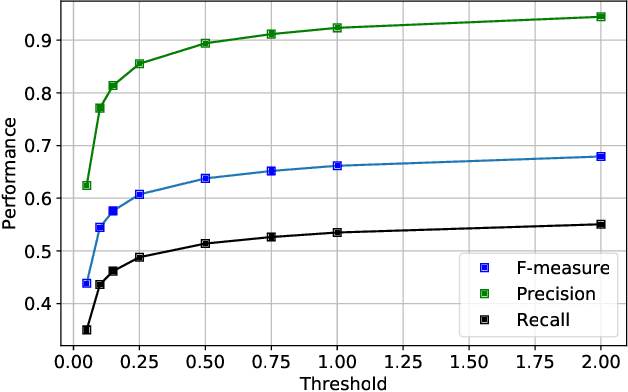
We propose a deep learning approach to predicting audio event onsets in electroencephalogram (EEG) recorded from users as they listen to music. We use a publicly available dataset containing ten contemporary songs and concurrently recorded EEG. We generate a sequence of onset labels for the songs in our dataset and trained neural networks (a fully connected network (FCN) and a recurrent neural network (RNN)) to parse one second windows of input EEG to predict one second windows of onsets in the audio. We compare our RNN network to both the standard spectral-flux based novelty function and the FCN. We find that our RNN was able to produce results that reflected its ability to generalize better than the other methods. Since there are no pre-existing works on this topic, the numbers presented in this paper may serve as useful benchmarks for future approaches to this research problem.
Audio Content Analysis
Jan 01, 2021

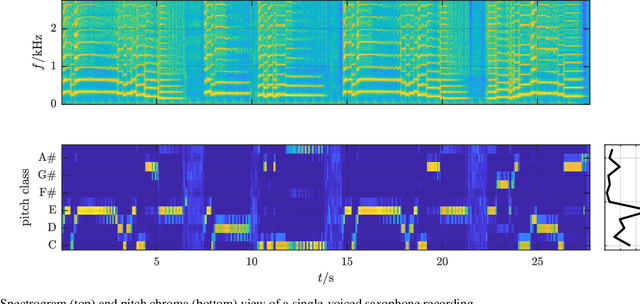
Preprint for a book chapter introducing Audio Content Analysis. With a focus on Music Information Retrieval systems, this chapter defines musical audio content, introduces the general process of audio content analysis, and surveys basic approaches to audio content analysis. The various tasks in Audio Content Analysis are categorized into three classes: music transcription, music performance analysis, and music identification and categorization. The examples for music transcription systems include music key detection, fundamental frequency detection, and music structure detection. Music performance analysis systems feature an overview of beat and tempo detection approaches as well as music performance assessment. The covered music classification systems are audio fingerprinting, music genre classification, and music emotion recognition. The chapter concludes with a discussion and current challenges in the field and a speculation on future perspectives.