 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAQUATK: An Audio Quality Assessment Toolkit
Nov 16, 2023Recent advancements in Neural Audio Synthesis (NAS) have outpaced the development of standardized evaluation methodologies and tools. To bridge this gap, we introduce AquaTk, an open-source Python library specifically designed to simplify and standardize the evaluation of NAS systems. AquaTk offers a range of audio quality metrics, including a unique Python implementation of the basic PEAQ algorithm, and operates in multiple modes to accommodate various user needs.
ASPED: An Audio Dataset for Detecting Pedestrians
Sep 12, 2023



We introduce the new audio analysis task of pedestrian detection and present a new large-scale dataset for this task. While the preliminary results prove the viability of using audio approaches for pedestrian detection, they also show that this challenging task cannot be easily solved with standard approaches.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023



Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.
Audio Embeddings as Teachers for Music Classification
Jun 30, 2023



Music classification has been one of the most popular tasks in the field of music information retrieval. With the development of deep learning models, the last decade has seen impressive improvements in a wide range of classification tasks. However, the increasing model complexity makes both training and inference computationally expensive. In this paper, we integrate the ideas of transfer learning and feature-based knowledge distillation and systematically investigate using pre-trained audio embeddings as teachers to guide the training of low-complexity student networks. By regularizing the feature space of the student networks with the pre-trained embeddings, the knowledge in the teacher embeddings can be transferred to the students. We use various pre-trained audio embeddings and test the effectiveness of the method on the tasks of musical instrument classification and music auto-tagging. Results show that our method significantly improves the results in comparison to the identical model trained without the teacher's knowledge. This technique can also be combined with classical knowledge distillation approaches to further improve the model's performance.
Evaluation of Spatial Distortion in Multichannel Audio
Jun 13, 2023



Despite the recent proliferation of spatial audio technologies, the evaluation of spatial quality continues to rely on subjective listening tests, often requiring expert listeners. Based on the duplex theory of spatial hearing, it is possible to construct a signal model for frequency-independent spatial distortion by accounting for inter-channel time and level differences relative to a reference signal. By using a combination of least-square optimization and heuristics, we propose a signal decomposition method to isolate the spatial error from a processed signal. This allows the computation of simple energy-ratio metrics, providing objective measures of spatial and non-spatial signal qualities, with minimal assumption and no dataset dependency. Experiments demonstrate robustness of the method against common signal degradation as introduced by, e.g., audio compression and music source separation. Implementation is available at https://github.com/karnwatcharasupat/spauq.
Music Instrument Classification Reprogrammed
Nov 15, 2022The performance of approaches to Music Instrument Classification, a popular task in Music Information Retrieval, is often impacted and limited by the lack of availability of annotated data for training. We propose to address this issue with "reprogramming," a technique that utilizes pre-trained deep and complex neural networks originally targeting a different task by modifying and mapping both the input and output of the pre-trained model. We demonstrate that reprogramming can effectively leverage the power of the representation learned for a different task and that the resulting reprogrammed system can perform on par or even outperform state-of-the-art systems at a fraction of training parameters. Our results, therefore, indicate that reprogramming is a promising technique potentially applicable to other tasks impeded by data scarcity.
Low-Resource Music Genre Classification with Advanced Neural Model Reprogramming
Nov 02, 2022



Transfer learning (TL) approaches have shown promising results when handling tasks with limited training data. However, considerable memory and computational resources are often required for fine-tuning pre-trained neural networks with target domain data. In this work, we introduce a novel method for leveraging pre-trained models for low-resource (music) classification based on the concept of Neural Model Reprogramming (NMR). NMR aims at re-purposing a pre-trained model from a source domain to a target domain by modifying the input of a frozen pre-trained model. In addition to the known, input-independent, reprogramming method, we propose an advanced reprogramming paradigm: Input-dependent NMR, to increase adaptability to complex input data such as musical audio. Experimental results suggest that a neural model pre-trained on large-scale datasets can successfully perform music genre classification by using this reprogramming method. The two proposed Input-dependent NMR TL methods outperform fine-tuning-based TL methods on a small genre classification dataset.
Representation Learning for the Automatic Indexing of Sound Effects Libraries
Aug 18, 2022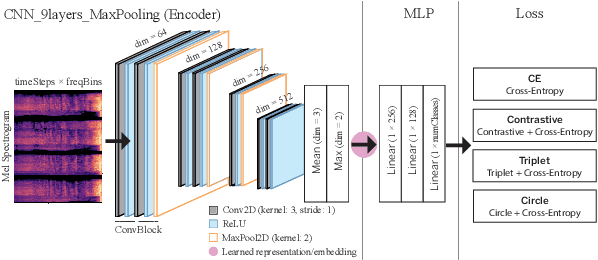
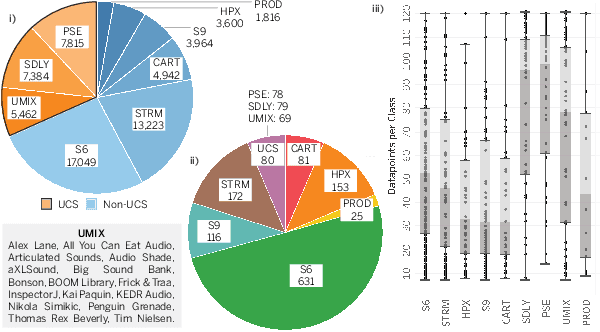
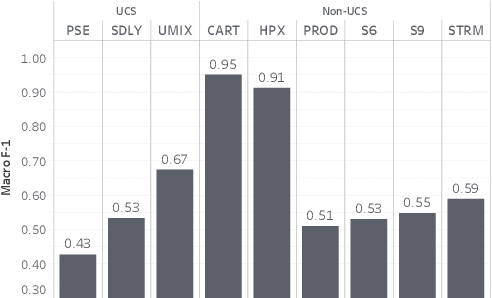
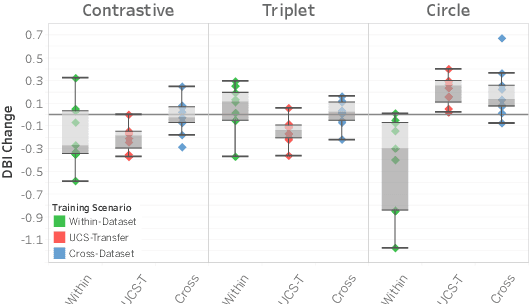
Labeling and maintaining a commercial sound effects library is a time-consuming task exacerbated by databases that continually grow in size and undergo taxonomy updates. Moreover, sound search and taxonomy creation are complicated by non-uniform metadata, an unrelenting problem even with the introduction of a new industry standard, the Universal Category System. To address these problems and overcome dataset-dependent limitations that inhibit the successful training of deep learning models, we pursue representation learning to train generalized embeddings that can be used for a wide variety of sound effects libraries and are a taxonomy-agnostic representation of sound. We show that a task-specific but dataset-independent representation can successfully address data issues such as class imbalance, inconsistent class labels, and insufficient dataset size, outperforming established representations such as OpenL3. Detailed experimental results show the impact of metric learning approaches and different cross-dataset training methods on representational effectiveness.
libACA, pyACA, and ACA-Code: Audio Content Analysis in 3 Languages
Jun 30, 2022The three packages libACA, pyACA, and ACA-Code provide reference implementations for basic approaches and algorithms for the analysis of musical audio signals in three different languages: C++, Python, and Matlab. All three packages cover the same algorithms, such as extraction of low level audio features, fundamental frequency estimation, as well as simple approaches to chord recognition, musical key detection, and onset detection. In addition, it implementations of more generic algorithms useful in audio content analysis such as dynamic time warping and the Viterbi algorithm are provided. The three packages thus provide a practical cross-language and cross-platform reference to students and engineers implementing audio analysis algorithms and enable implementation-focused learning of algorithms for audio content analysis and music information retrieval.
Feature-informed Embedding Space Regularization For Audio Classification
Jun 10, 2022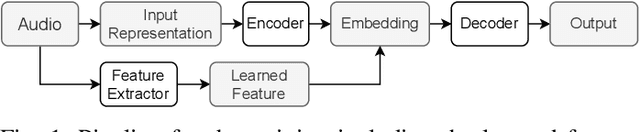
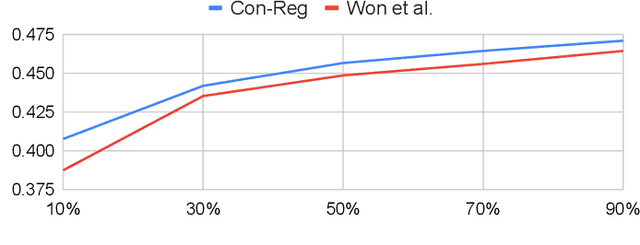
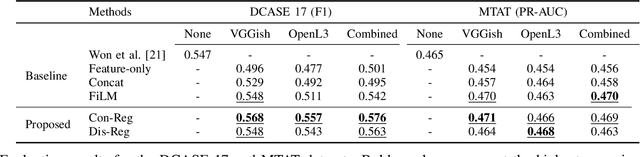
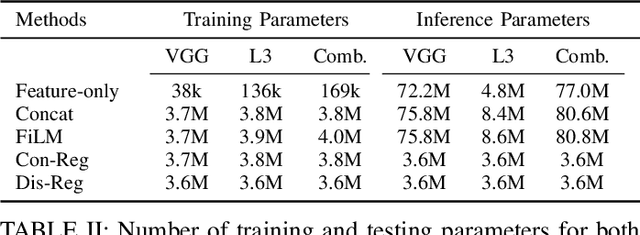
Feature representations derived from models pre-trained on large-scale datasets have shown their generalizability on a variety of audio analysis tasks. Despite this generalizability, however, task-specific features can outperform if sufficient training data is available, as specific task-relevant properties can be learned. Furthermore, the complex pre-trained models bring considerable computational burdens during inference. We propose to leverage both detailed task-specific features from spectrogram input and generic pre-trained features by introducing two regularization methods that integrate the information of both feature classes. The workload is kept low during inference as the pre-trained features are only necessary for training. In experiments with the pre-trained features VGGish, OpenL3, and a combination of both, we show that the proposed methods not only outperform baseline methods, but also can improve state-of-the-art models on several audio classification tasks. The results also suggest that using the mixture of features performs better than using individual features.