 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Self-Attention Approximation via Trainable Feedforward Kernel
Nov 08, 2022In pursuit of faster computation, Efficient Transformers demonstrate an impressive variety of approaches -- models attaining sub-quadratic attention complexity can utilize a notion of sparsity or a low-rank approximation of inputs to reduce the number of attended keys; other ways to reduce complexity include locality-sensitive hashing, key pooling, additional memory to store information in compacted or hybridization with other architectures, such as CNN. Often based on a strong mathematical basis, kernelized approaches allow for the approximation of attention with linear complexity while retaining high accuracy. Therefore, in the present paper, we aim to expand the idea of trainable kernel methods to approximate the self-attention mechanism of the Transformer architecture.
Graph Neural Networks with Trainable Adjacency Matrices for Fault Diagnosis on Multivariate Sensor Data
Oct 20, 2022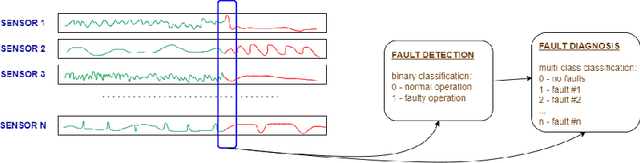

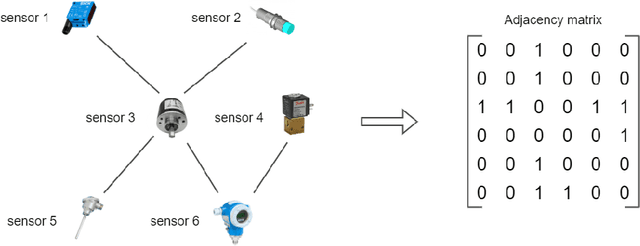
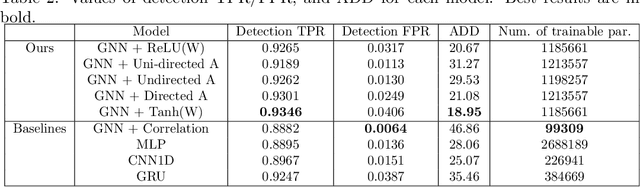
Timely detected anomalies in the chemical technological processes, as well as the earliest detection of the cause of the fault, significantly reduce the production cost in the industrial factories. Data on the state of the technological process and the operation of production equipment are received by a large number of different sensors. To better predict the behavior of the process and equipment, it is necessary not only to consider the behavior of the signals in each sensor separately, but also to take into account their correlation and hidden relationships with each other. Graph-based data representation helps with this. The graph nodes can be represented as data from the different sensors, and the edges can display the influence of these data on each other. In this work, the possibility of applying graph neural networks to the problem of fault diagnosis in a chemical process is studied. It was proposed to construct a graph during the training of graph neural network. This allows to train models on data where the dependencies between the sensors are not known in advance. In this work, several methods for obtaining adjacency matrices were considered, as well as their quality was studied. It has also been proposed to use multiple adjacency matrices in one model. We showed state-of-the-art performance on the fault diagnosis task with the Tennessee Eastman Process dataset. The proposed graph neural networks outperformed the results of recurrent neural networks.
SimpleTron: Eliminating Softmax from Attention Computation
Dec 02, 2021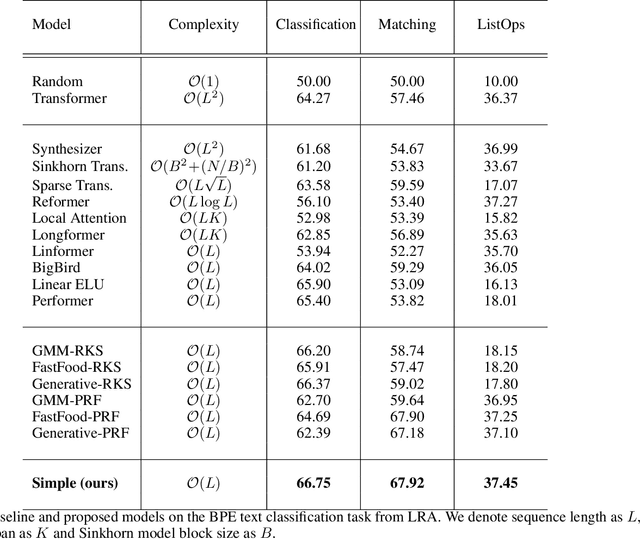
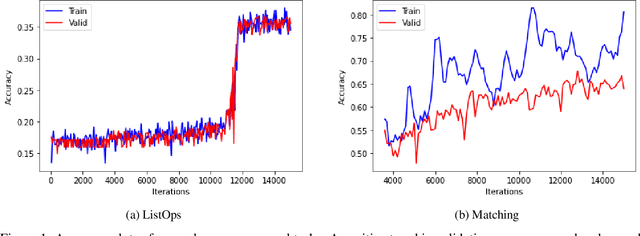
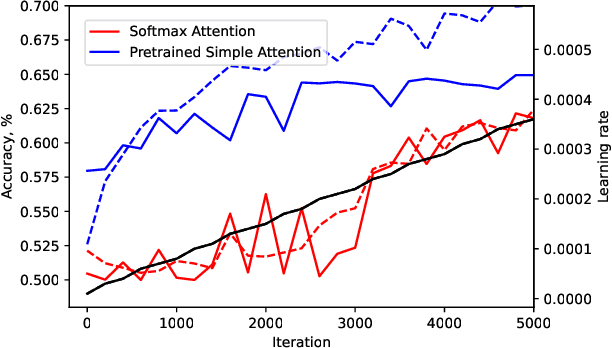
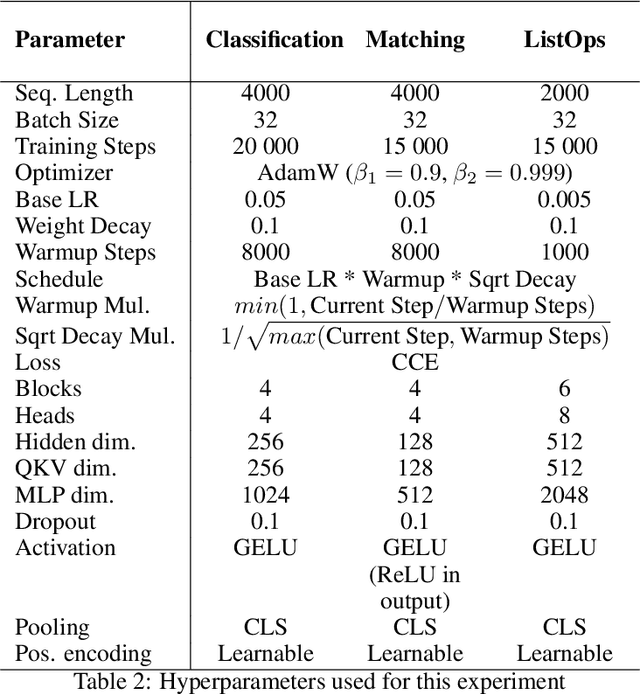
In this paper, we propose that the dot product pairwise matching attention layer, which is widely used in transformer-based models, is redundant for the model performance. Attention in its original formulation has to be rather seen as a human-level tool to explore and/or visualize relevancy scores in the sequences. Instead, we present a simple and fast alternative without any approximation that, to the best of our knowledge, outperforms existing attention approximations on several tasks from the Long-Range Arena benchmark.
Dynamic Neural Diversification: Path to Computationally Sustainable Neural Networks
Sep 20, 2021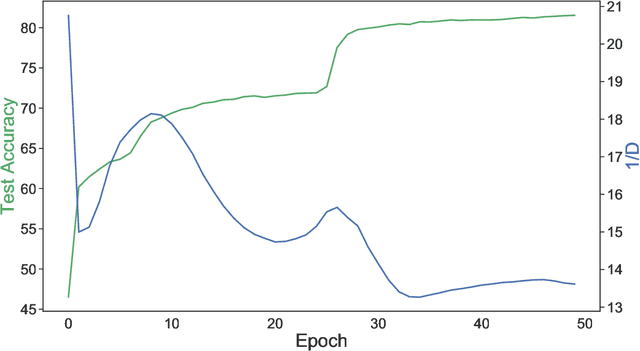
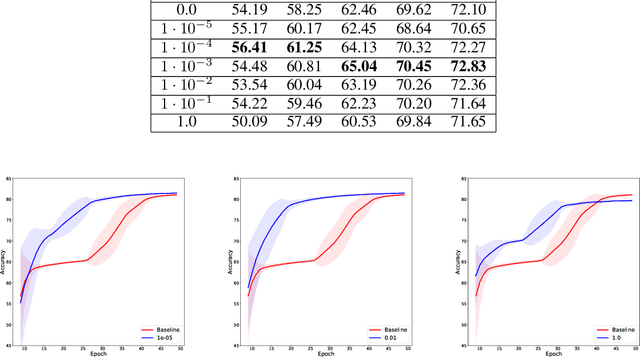
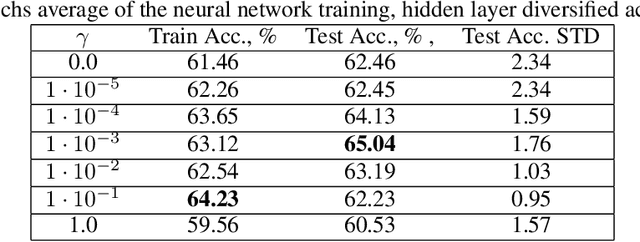
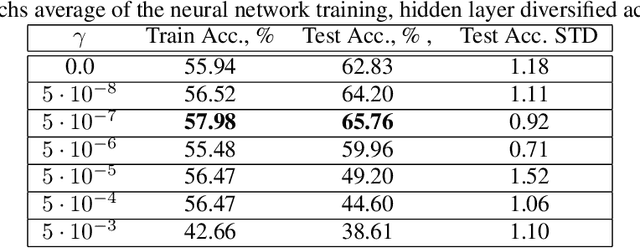
Small neural networks with a constrained number of trainable parameters, can be suitable resource-efficient candidates for many simple tasks, where now excessively large models are used. However, such models face several problems during the learning process, mainly due to the redundancy of the individual neurons, which results in sub-optimal accuracy or the need for additional training steps. Here, we explore the diversity of the neurons within the hidden layer during the learning process, and analyze how the diversity of the neurons affects predictions of the model. As following, we introduce several techniques to dynamically reinforce diversity between neurons during the training. These decorrelation techniques improve learning at early stages and occasionally help to overcome local minima faster. Additionally, we describe novel weight initialization method to obtain decorrelated, yet stochastic weight initialization for a fast and efficient neural network training. Decorrelated weight initialization in our case shows about 40% relative increase in test accuracy during the first 5 epochs.
* Accepted to ICANN 2021