 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical SANSformers: Training self-supervised transformers without attention for Electronic Medical Records
Aug 31, 2021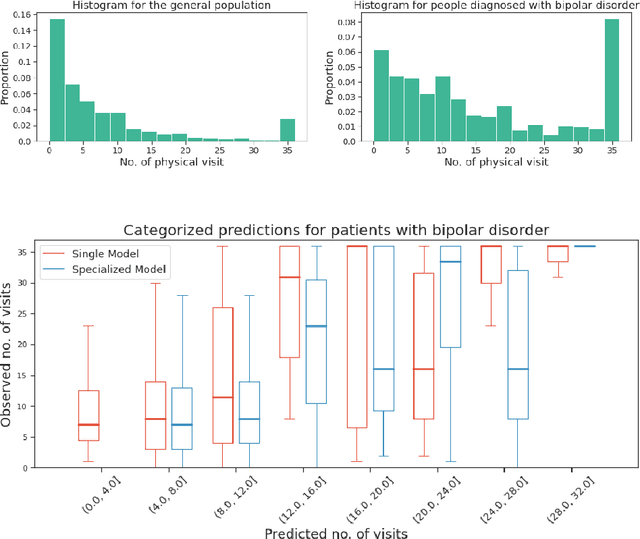
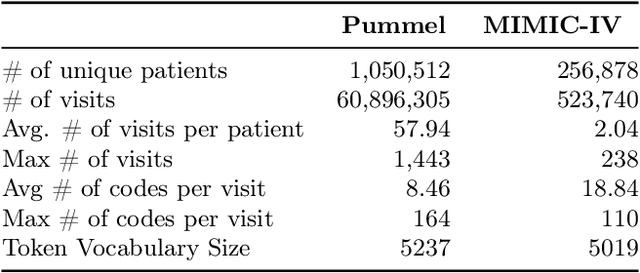
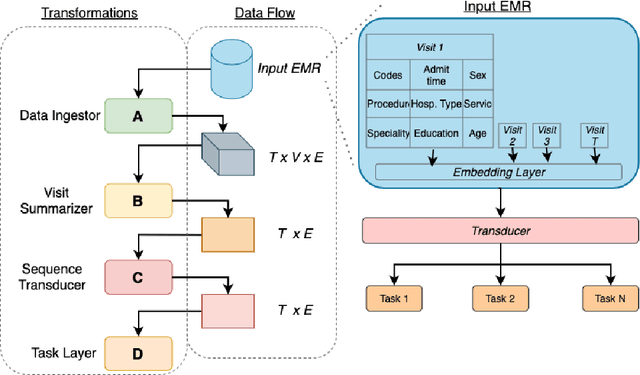
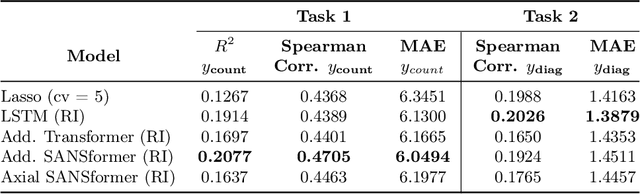
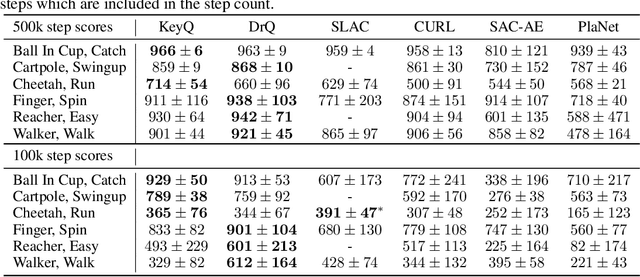
We leverage deep sequential models to tackle the problem of predicting healthcare utilization for patients, which could help governments to better allocate resources for future healthcare use. Specifically, we study the problem of \textit{divergent subgroups}, wherein the outcome distribution in a smaller subset of the population considerably deviates from that of the general population. The traditional approach for building specialized models for divergent subgroups could be problematic if the size of the subgroup is very small (for example, rare diseases). To address this challenge, we first develop a novel attention-free sequential model, SANSformers, instilled with inductive biases suited for modeling clinical codes in electronic medical records. We then design a task-specific self-supervision objective and demonstrate its effectiveness, particularly in scarce data settings, by pre-training each model on the entire health registry (with close to one million patients) before fine-tuning for downstream tasks on the divergent subgroups. We compare the novel SANSformer architecture with the LSTM and Transformer models using two data sources and a multi-task learning objective that aids healthcare utilization prediction. Empirically, the attention-free SANSformer models perform consistently well across experiments, outperforming the baselines in most cases by at least $\sim 10$\%. Furthermore, the self-supervised pre-training boosts performance significantly throughout, for example by over $\sim 50$\% (and as high as $800$\%) on $R^2$ score when predicting the number of hospital visits.
End-to-End Learning of Keypoint Representations for Continuous Control from Images
Jun 15, 2021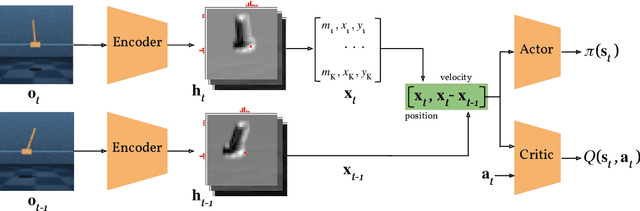


In many control problems that include vision, optimal controls can be inferred from the location of the objects in the scene. This information can be represented using keypoints, which is a list of spatial locations in the input image. Previous works show that keypoint representations learned during unsupervised pre-training using encoder-decoder architectures can provide good features for control tasks. In this paper, we show that it is possible to learn efficient keypoint representations end-to-end, without the need for unsupervised pre-training, decoders, or additional losses. Our proposed architecture consists of a differentiable keypoint extractor that feeds the coordinates of the estimated keypoints directly to a soft actor-critic agent. The proposed algorithm yields performance competitive to the state-of-the art on DeepMind Control Suite tasks.
Learning to Play Imperfect-Information Games by Imitating an Oracle Planner
Dec 22, 2020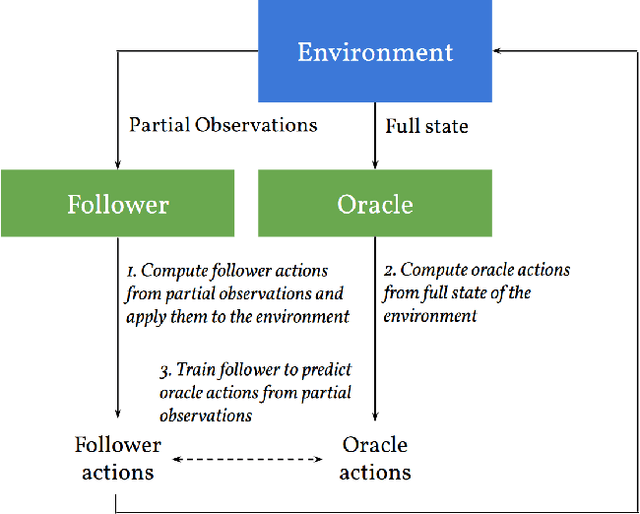
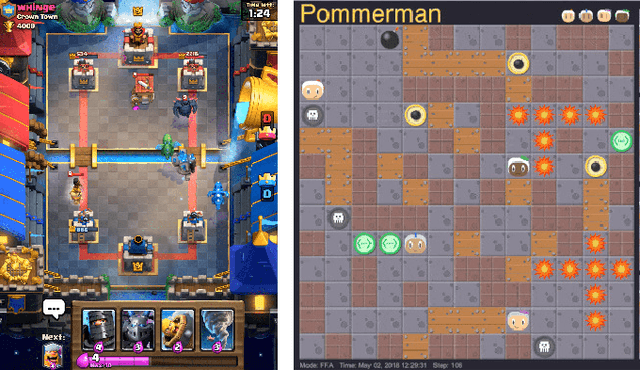
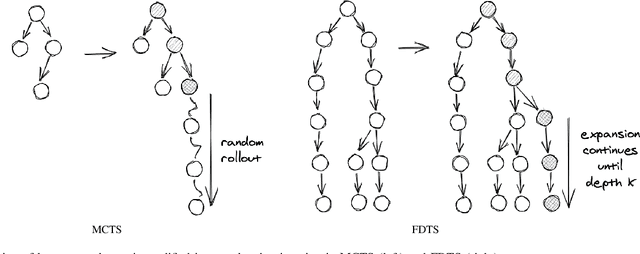
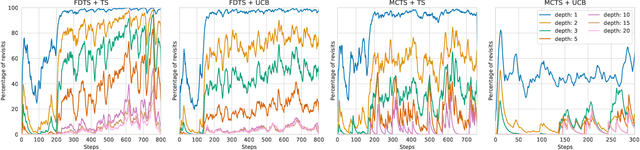
We consider learning to play multiplayer imperfect-information games with simultaneous moves and large state-action spaces. Previous attempts to tackle such challenging games have largely focused on model-free learning methods, often requiring hundreds of years of experience to produce competitive agents. Our approach is based on model-based planning. We tackle the problem of partial observability by first building an (oracle) planner that has access to the full state of the environment and then distilling the knowledge of the oracle to a (follower) agent which is trained to play the imperfect-information game by imitating the oracle's choices. We experimentally show that planning with naive Monte Carlo tree search does not perform very well in large combinatorial action spaces. We therefore propose planning with a fixed-depth tree search and decoupled Thompson sampling for action selection. We show that the planner is able to discover efficient playing strategies in the games of Clash Royale and Pommerman and the follower policy successfully learns to implement them by training on a few hundred battles.
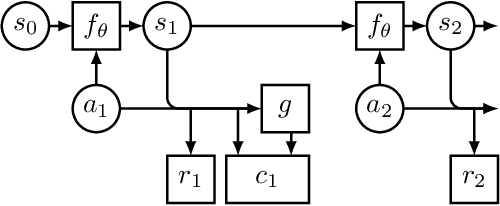
Regularizing Model-Based Planning with Energy-Based Models
Oct 12, 2019
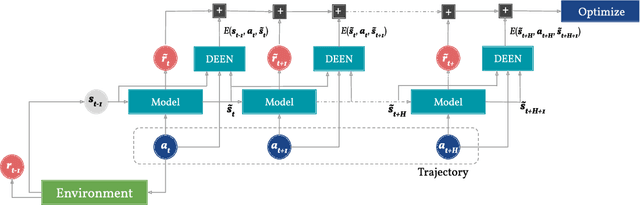
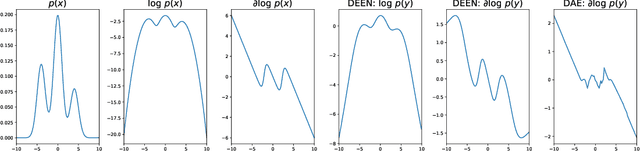
Model-based reinforcement learning could enable sample-efficient learning by quickly acquiring rich knowledge about the world and using it to improve behaviour without additional data. Learned dynamics models can be directly used for planning actions but this has been challenging because of inaccuracies in the learned models. In this paper, we focus on planning with learned dynamics models and propose to regularize it using energy estimates of state transitions in the environment. We visually demonstrate the effectiveness of the proposed method and show that off-policy training of an energy estimator can be effectively used to regularize planning with pre-trained dynamics models. Further, we demonstrate that the proposed method enables sample-efficient learning to achieve competitive performance in challenging continuous control tasks such as Half-cheetah and Ant in just a few minutes of experience.
Regularizing Trajectory Optimization with Denoising Autoencoders
Mar 28, 2019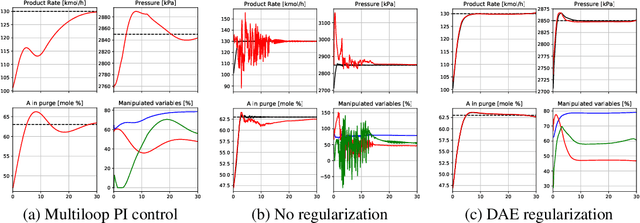

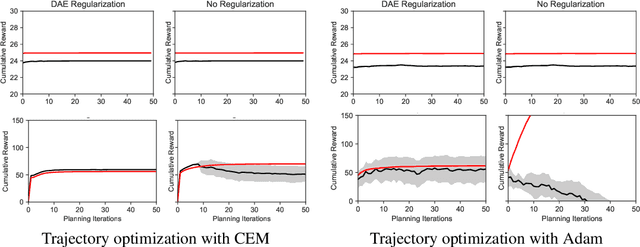
Trajectory optimization with learned dynamics models can often suffer from erroneous predictions of out-of-distribution trajectories. We propose to regularize trajectory optimization by means of a denoising autoencoder that is trained on the same trajectories as the dynamics model. We visually demonstrate the effectiveness of the regularization in gradient-based trajectory optimization for open-loop control of an industrial process. We compare with recent model-based reinforcement learning algorithms on a set of popular motor control tasks to demonstrate that the denoising regularization enables state-of-the-art sample-efficiency. We demonstrate the efficacy of the proposed method in regularizing both gradient-based and gradient-free trajectory optimization.
Semi-Supervised and Active Few-Shot Learning with Prototypical Networks
Apr 25, 2018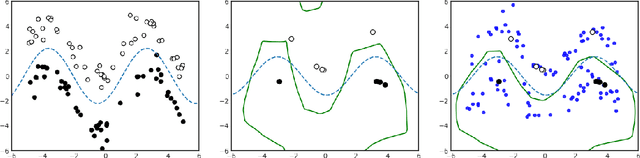
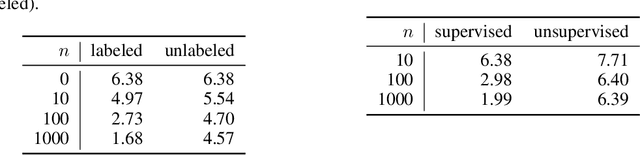
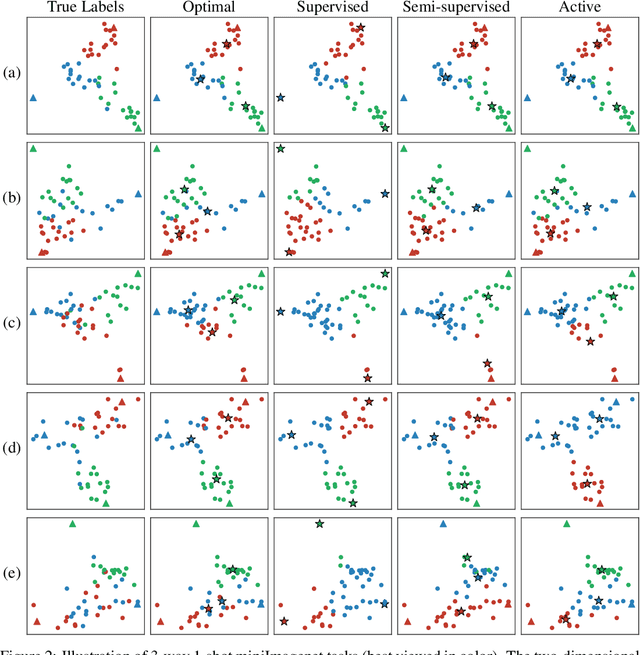
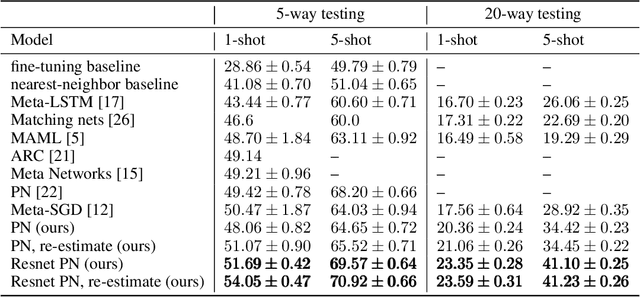
We consider the problem of semi-supervised few-shot classification where a classifier needs to adapt to new tasks using a few labeled examples and (potentially many) unlabeled examples. We propose a clustering approach to the problem. The features extracted with Prototypical Networks are clustered using $K$-means with the few labeled examples guiding the clustering process. We note that in many real-world applications the adaptation performance can be significantly improved by requesting the few labels through user feedback. We demonstrate good performance of the active adaptation strategy using image data.
Recurrent Ladder Networks
Dec 18, 2017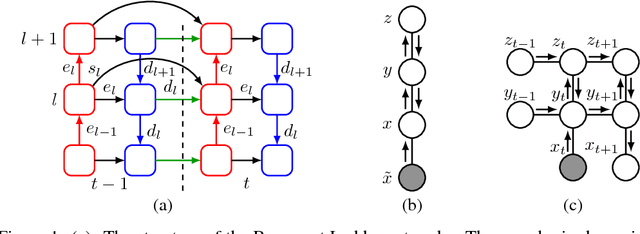
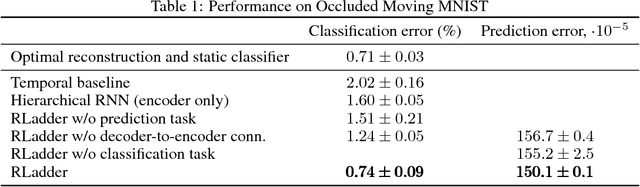
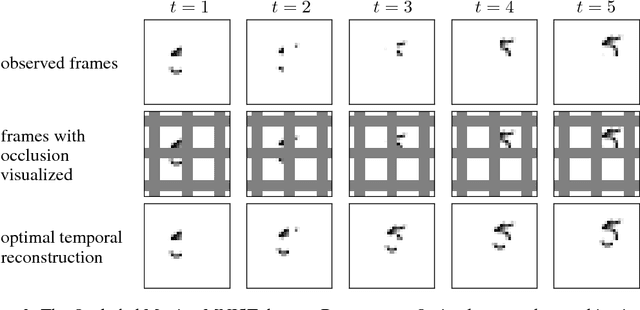

We propose a recurrent extension of the Ladder networks whose structure is motivated by the inference required in hierarchical latent variable models. We demonstrate that the recurrent Ladder is able to handle a wide variety of complex learning tasks that benefit from iterative inference and temporal modeling. The architecture shows close-to-optimal results on temporal modeling of video data, competitive results on music modeling, and improved perceptual grouping based on higher order abstractions, such as stochastic textures and motion cues. We present results for fully supervised, semi-supervised, and unsupervised tasks. The results suggest that the proposed architecture and principles are powerful tools for learning a hierarchy of abstractions, learning iterative inference and handling temporal information.
Linear State-Space Model with Time-Varying Dynamics
Oct 03, 2014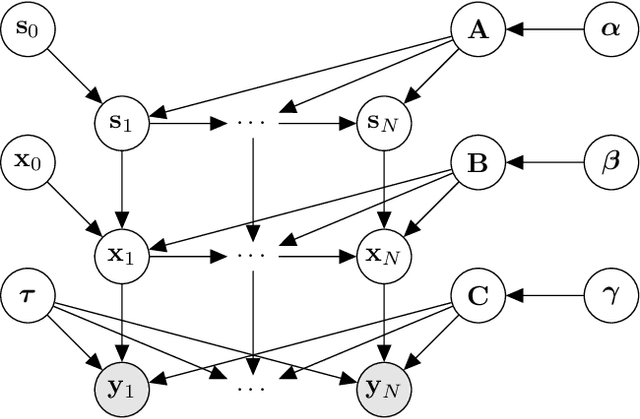
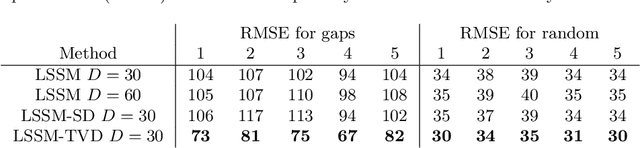
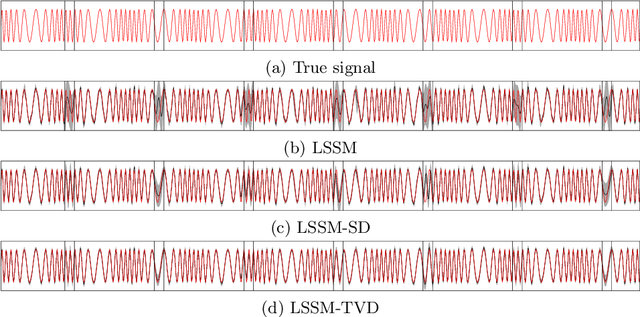

This paper introduces a linear state-space model with time-varying dynamics. The time dependency is obtained by forming the state dynamics matrix as a time-varying linear combination of a set of matrices. The time dependency of the weights in the linear combination is modelled by another linear Gaussian dynamical model allowing the model to learn how the dynamics of the process changes. Previous approaches have used switching models which have a small set of possible state dynamics matrices and the model selects one of those matrices at each time, thus jumping between them. Our model forms the dynamics as a linear combination and the changes can be smooth and more continuous. The model is motivated by physical processes which are described by linear partial differential equations whose parameters vary in time. An example of such a process could be a temperature field whose evolution is driven by a varying wind direction. The posterior inference is performed using variational Bayesian approximation. The experiments on stochastic advection-diffusion processes and real-world weather processes show that the model with time-varying dynamics can outperform previously introduced approaches.
* The final publication is available at Springer via http://dx.doi.org/10.1007/978-3-662-44851-9_22