 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Human Performance in Online Low-latency Recognition of Conversational Speech
Oct 22, 2020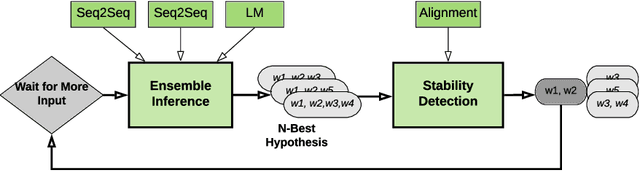
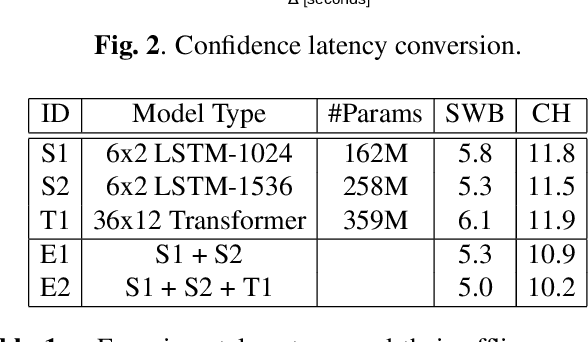
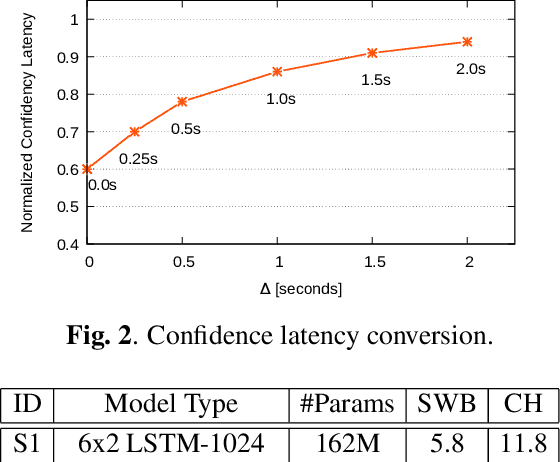
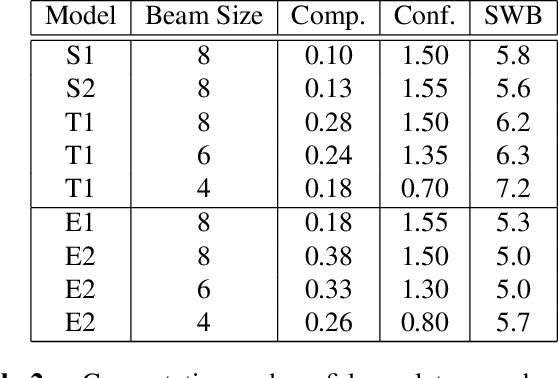
Achieving super-human performance in recognizing human speech has been a goal for several decades, as researchers have worked on increasingly challenging tasks. In the 1990's it was discovered, that conversational speech between two humans turns out to be considerably more difficult than read speech as hesitations, disfluencies, false starts and sloppy articulation complicate acoustic processing and require robust handling of acoustic, lexical and language context, jointly. Early attempts with statistical models could only reach error rates over 50% and far from human performance (WER of around 5.5%). Neural hybrid models and recent attention-based encoder-decoder models have considerably improved performance as such contexts can now be learned in an integral fashion. However, processing such contexts requires an entire utterance presentation and thus introduces unwanted delays before a recognition result can be output. In this paper, we address performance as well as latency. We present results for a system that can achieve super-human performance (at a WER of 5.0%, over the Switchboard conversational benchmark) at a word based latency of only 1 second behind a speaker's speech. The system uses multiple attention-based encoder-decoder networks integrated within a novel low latency incremental inference approach.
Error-correction and extraction in request dialogs
Apr 08, 2020



We propose a component that gets a request and a correction and outputs a corrected request. To get this corrected request, the entities in the correction phrase replace their corresponding entities in the request. In addition, the proposed component outputs these pairs of corresponding reparandum and repair entity. These entity pairs can be used, for example, for learning in a life-long learning component of a dialog system to reduce the need for correction in future dialogs. For the approach described in this work, we fine-tune BERT for sequence labeling. We created a dataset to evaluate our component; for which we got an accuracy of 93.28 %. An accuracy of 88.58 % has been achieved for out-of-domain data. This accuracy shows that the proposed component is learning the concept of corrections and can be developed to be used as an upstream component to avoid the need for collecting data for request corrections for every new domain.
High Performance Sequence-to-Sequence Model for Streaming Speech Recognition
Mar 22, 2020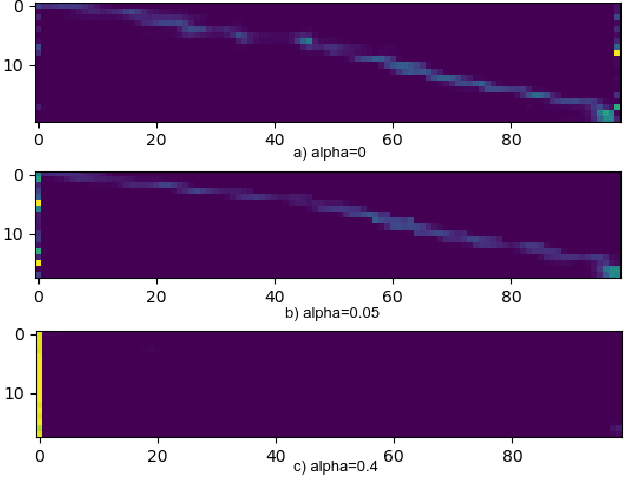
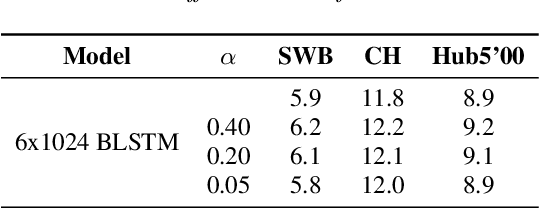
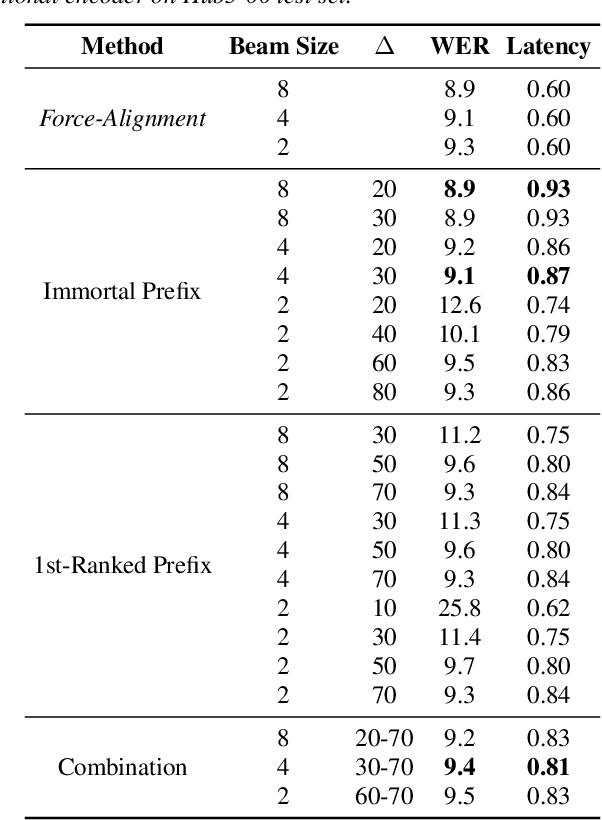
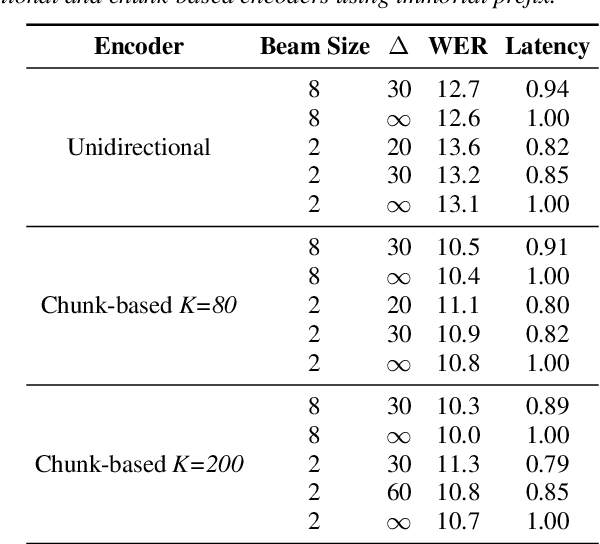
Recently sequence-to-sequence models have started to achieve state-of-the art performance on standard speech recognition tasks when processing audio data in batch mode, i.e., the complete audio data is available when starting processing. However, when it comes to perform run-on recognition on an input stream of audio data while producing recognition results in real-time and with a low word-based latency, these models face several challenges. For many techniques, the whole audio sequence to be decoded needs to be available at the start of the processing, e.g., for the attention mechanism or for the bidirectional LSTM (BLSTM). In this paper we propose several techniques to mitigate these problems. We introduce an additional loss function controlling the uncertainty of the attention mechanism, a modified beam search identifying partial, stable hypotheses, ways of working with BLSTM in the encoder, and the use of chunked BLSTM. Our experiments show that with the right combination of these techniques it is possible to perform run-on speech recognition with a low word-based latency without sacrificing performance in terms of word error rate.
Low Latency ASR for Simultaneous Speech Translation
Mar 22, 2020

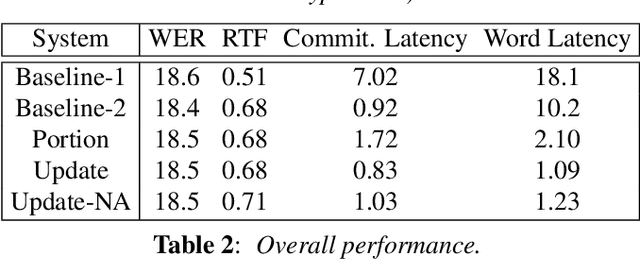
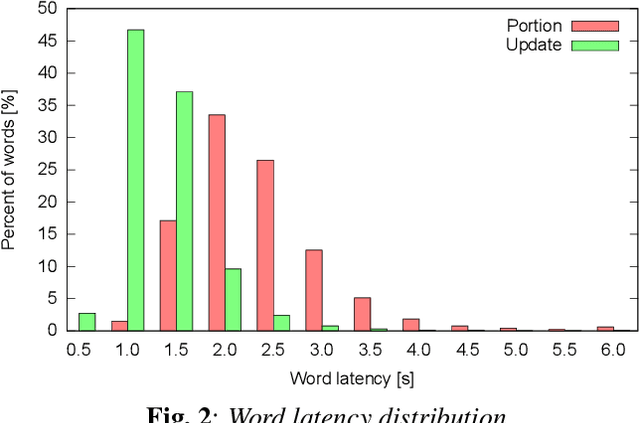
User studies have shown that reducing the latency of our simultaneous lecture translation system should be the most important goal. We therefore have worked on several techniques for reducing the latency for both components, the automatic speech recognition and the speech translation module. Since the commonly used commitment latency is not appropriate in our case of continuous stream decoding, we focused on word latency. We used it to analyze the performance of our current system and to identify opportunities for improvements. In order to minimize the latency we combined run-on decoding with a technique for identifying stable partial hypotheses when stream decoding and a protocol for dynamic output update that allows to revise the most recent parts of the transcription. This combination reduces the latency at word level, where the words are final and will never be updated again in the future, from 18.1s to 1.1s without sacrificing performance in terms of word error rate.
Toward Cross-Domain Speech Recognition with End-to-End Models
Mar 09, 2020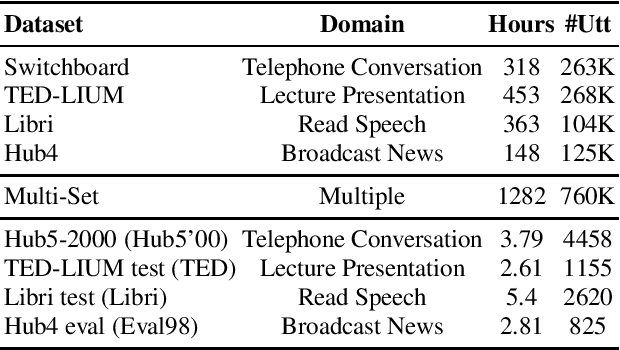
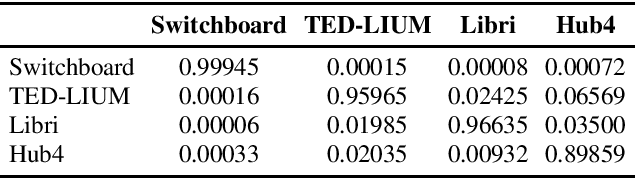
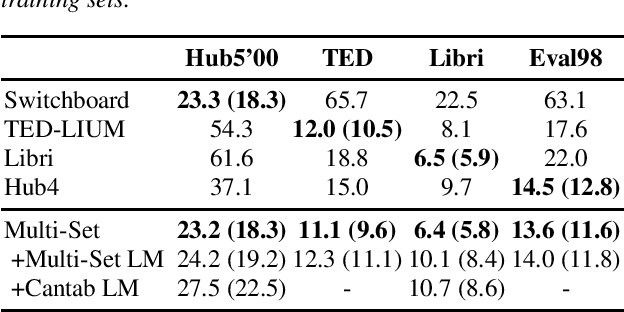
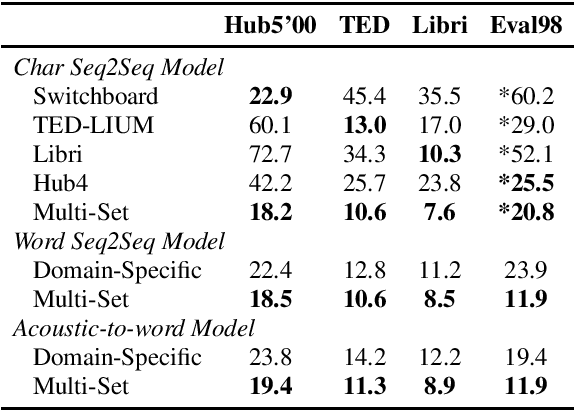
In the area of multi-domain speech recognition, research in the past focused on hybrid acoustic models to build cross-domain and domain-invariant speech recognition systems. In this paper, we empirically examine the difference in behavior between hybrid acoustic models and neural end-to-end systems when mixing acoustic training data from several domains. For these experiments we composed a multi-domain dataset from public sources, with the different domains in the corpus covering a wide variety of topics and acoustic conditions such as telephone conversations, lectures, read speech and broadcast news. We show that for the hybrid models, supplying additional training data from other domains with mismatched acoustic conditions does not increase the performance on specific domains. However, our end-to-end models optimized with sequence-based criterion generalize better than the hybrid models on diverse domains. In term of word-error-rate performance, our experimental acoustic-to-word and attention-based models trained on multi-domain dataset reach the performance of domain-specific long short-term memory (LSTM) hybrid models, thus resulting in multi-domain speech recognition systems that do not suffer in performance over domain specific ones. Moreover, the use of neural end-to-end models eliminates the need of domain-adapted language models during recognition, which is a great advantage when the input domain is unknown.
An Interactive Indoor Drone Assistant
Dec 09, 2019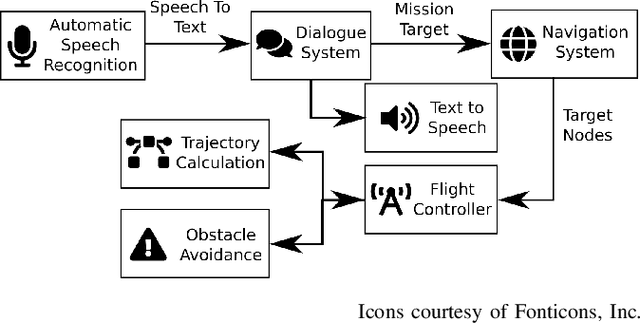

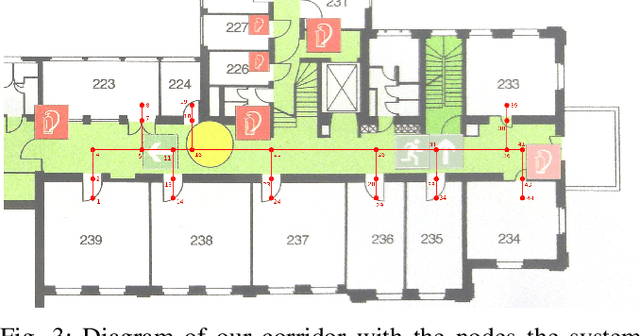
With the rapid advance of sophisticated control algorithms, the capabilities of drones to stabilise, fly and manoeuvre autonomously have dramatically improved, enabling us to pay greater attention to entire missions and the interaction of a drone with humans and with its environment during the course of such a mission. In this paper, we present an indoor office drone assistant that is tasked to run errands and carry out simple tasks at our laboratory, while given instructions from and interacting with humans in the space. To accomplish its mission, the system has to be able to understand verbal instructions from humans, and perform subject to constraints from control and hardware limitations, uncertain localisation information, unpredictable and uncertain obstacles and environmental factors. We combine and evaluate the dialogue, navigation, flight control, depth perception and collision avoidance components. We discuss performance and limitations of our assistant at the component as well as the mission level. A 78% mission success rate was obtained over the course of 27 missions.
Bimodal Speech Emotion Recognition Using Pre-Trained Language Models
Nov 29, 2019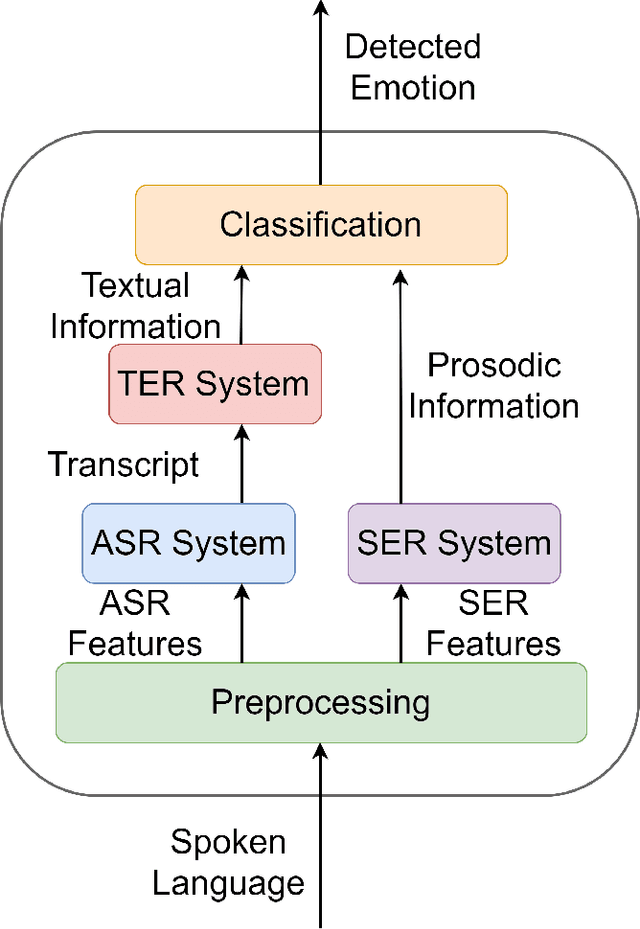
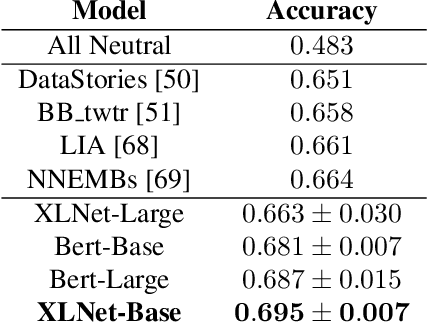

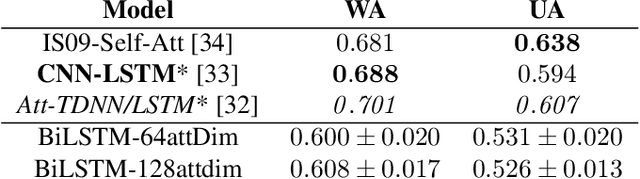
Speech emotion recognition is a challenging task and an important step towards more natural human-machine interaction. We show that pre-trained language models can be fine-tuned for text emotion recognition, achieving an accuracy of 69.5% on Task 4A of SemEval 2017, improving upon the previous state of the art by over 3% absolute. We combine these language models with speech emotion recognition, achieving results of 73.5% accuracy when using provided transcriptions and speech data on a subset of four classes of the IEMOCAP dataset. The use of noise-induced transcriptions and speech data results in an accuracy of 71.4%. For our experiments, we created IEmoNet, a modular and adaptable bimodal framework for speech emotion recognition based on pre-trained language models. Lastly, we discuss the idea of using an emotional classifier as a reward for reinforcement learning as a step towards more successful and convenient human-machine interaction.
Low-Resource Machine Translation using Interlinear Glosses
Nov 07, 2019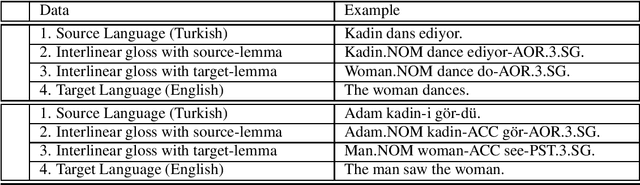

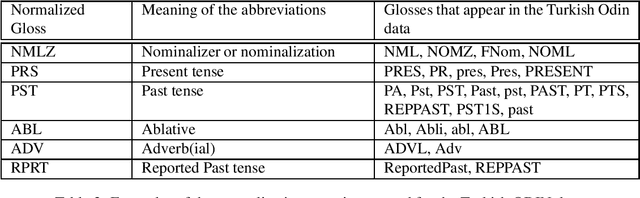
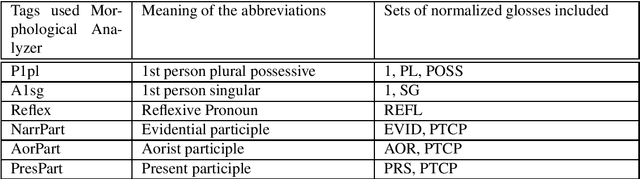
Neural Machine Translation (NMT) does not handle low-resource translation well because NMT is data-hungry and low-resource languages, by their nature, have limited parallel data. Many low-resource languages are morphologically rich, which complicates matters further by increasing data sparsity. However, a good linguist is capable of building a morphological analyzer in far fewer hours than it would take to collect and translate the amount of parallel data needed for conventional NMT. We combine the benefits of both NMT and linguistic information in our work. We use morphological analyzer to automatically generate interlinear glosses with dictionary or parallel data, and translate the source text to interlinear gloss as an interlingua representation, and finally translate into the target text using NMT trained on the ODIN dataset that includes a large collection of interlinear glosses and their corresponding target translations. Our result for translating from the interlinear gloss to the target text using the entire ODIN dataset achieves a BLEU score of 35.07. And our qualitative results show positive findings in a low-resource scenario of Turkish-English translation using 865 lines of training data. Our translation system yield better results than training NMT directly from the source language to the target language in a constrained-data setting, and is helpful to produce translation with sufficiently good content and fluency when data is scarce.
Improving sequence-to-sequence speech recognition training with on-the-fly data augmentation
Oct 29, 2019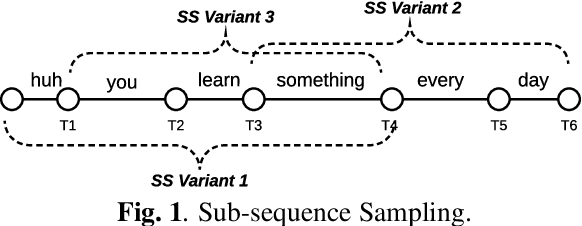
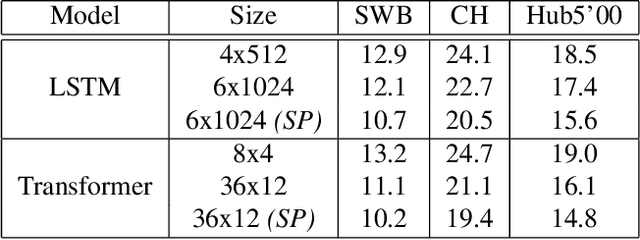
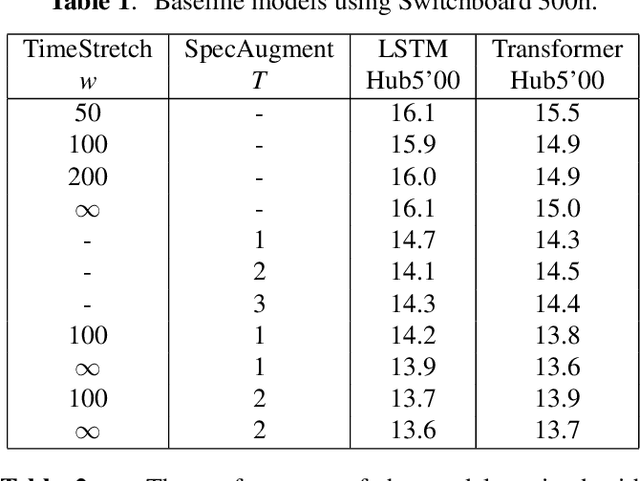
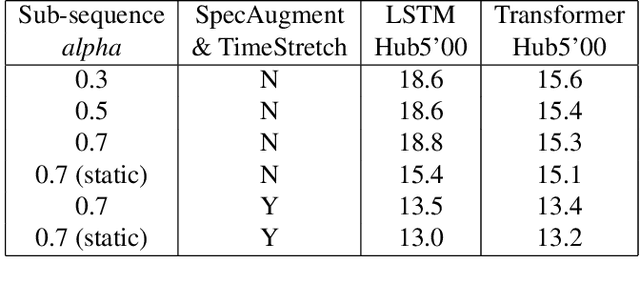
Sequence-to-Sequence (S2S) models recently started to show state-of-the-art performance for automatic speech recognition (ASR). With these large and deep models overfitting remains the largest problem, outweighing performance improvements that can be obtained from better architectures. One solution to the overfitting problem is increasing the amount of available training data and the variety exhibited by the training data with the help of data augmentation. In this paper we examine the influence of three data augmentation methods on the performance of two S2S model architectures. One of the data augmentation method comes from literature, while two other methods are our own development - a time perturbation in the frequency domain and sub-sequence sampling. Our experiments on Switchboard and Fisher data show state-of-the-art performance for S2S models that are trained solely on the speech training data and do not use additional text data.
Incremental processing of noisy user utterances in the spoken language understanding task
Sep 30, 2019
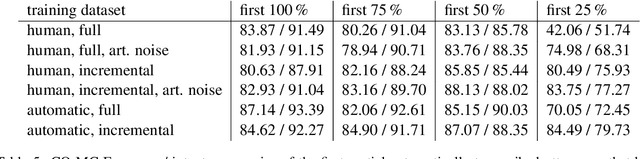
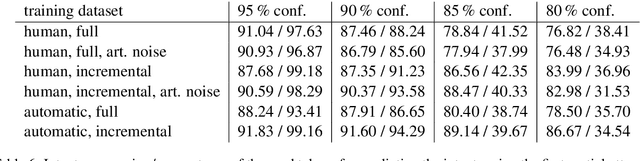
The state-of-the-art neural network architectures make it possible to create spoken language understanding systems with high quality and fast processing time. One major challenge for real-world applications is the high latency of these systems caused by triggered actions with high executions times. If an action can be separated into subactions, the reaction time of the systems can be improved through incremental processing of the user utterance and starting subactions while the utterance is still being uttered. In this work, we present a model-agnostic method to achieve high quality in processing incrementally produced partial utterances. Based on clean and noisy versions of the ATIS dataset, we show how to create datasets with our method to create low-latency natural language understanding components. We get improvements of up to 47.91 absolute percentage points in the metric F1-score.