 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-shot Translation with Language-Independent Constraints
Jun 20, 2019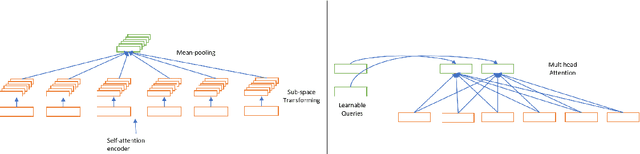
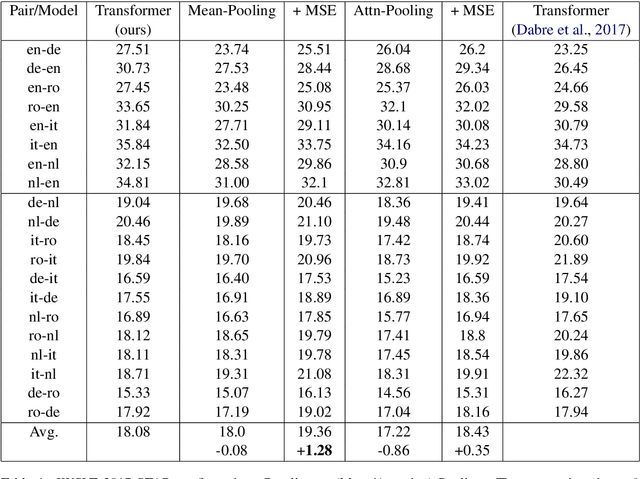
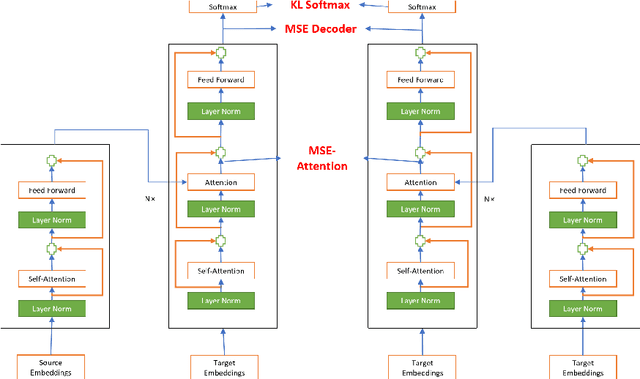
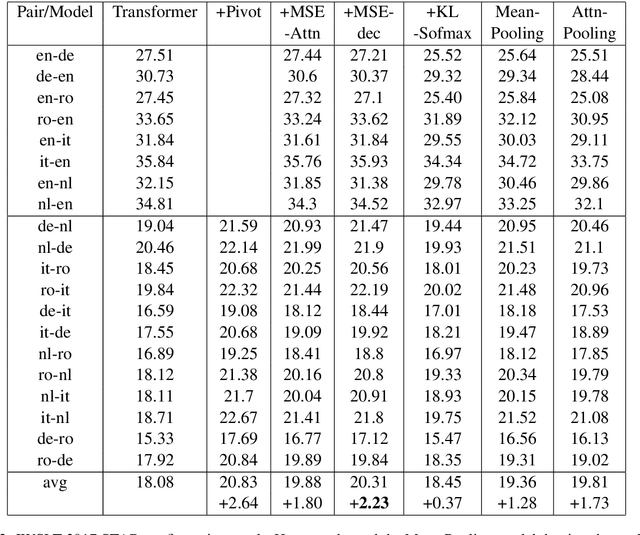
An important concern in training multilingual neural machine translation (NMT) is to translate between language pairs unseen during training, i.e zero-shot translation. Improving this ability kills two birds with one stone by providing an alternative to pivot translation which also allows us to better understand how the model captures information between languages. In this work, we carried out an investigation on this capability of the multilingual NMT models. First, we intentionally create an encoder architecture which is independent with respect to the source language. Such experiments shed light on the ability of NMT encoders to learn multilingual representations, in general. Based on such proof of concept, we were able to design regularization methods into the standard Transformer model, so that the whole architecture becomes more robust in zero-shot conditions. We investigated the behaviour of such models on the standard IWSLT 2017 multilingual dataset. We achieved an average improvement of 2.23 BLEU points across 12 language pairs compared to the zero-shot performance of a state-of-the-art multilingual system. Additionally, we carry out further experiments in which the effect is confirmed even for language pairs with multiple intermediate pivots.
Self-Attentional Models for Lattice Inputs
Jun 04, 2019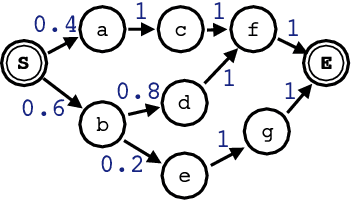
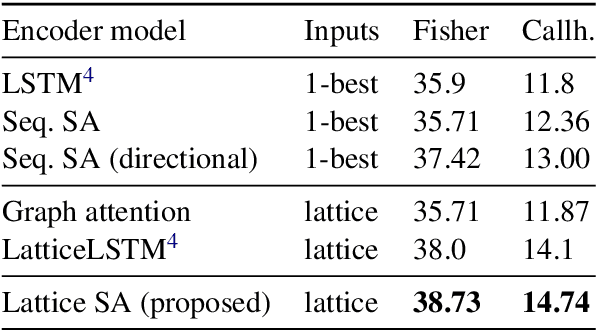
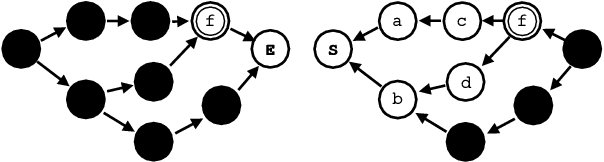
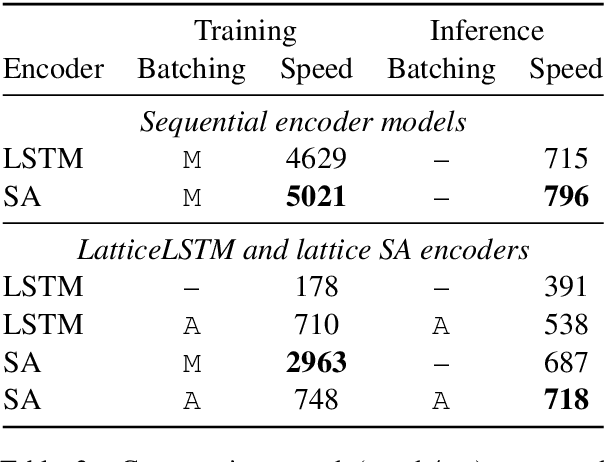
Lattices are an efficient and effective method to encode ambiguity of upstream systems in natural language processing tasks, for example to compactly capture multiple speech recognition hypotheses, or to represent multiple linguistic analyses. Previous work has extended recurrent neural networks to model lattice inputs and achieved improvements in various tasks, but these models suffer from very slow computation speeds. This paper extends the recently proposed paradigm of self-attention to handle lattice inputs. Self-attention is a sequence modeling technique that relates inputs to one another by computing pairwise similarities and has gained popularity for both its strong results and its computational efficiency. To extend such models to handle lattices, we introduce probabilistic reachability masks that incorporate lattice structure into the model and support lattice scores if available. We also propose a method for adapting positional embeddings to lattice structures. We apply the proposed model to a speech translation task and find that it outperforms all examined baselines while being much faster to compute than previous neural lattice models during both training and inference.
Fluent Translations from Disfluent Speech in End-to-End Speech Translation
Jun 03, 2019
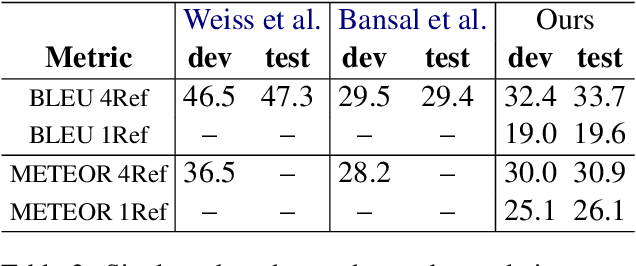
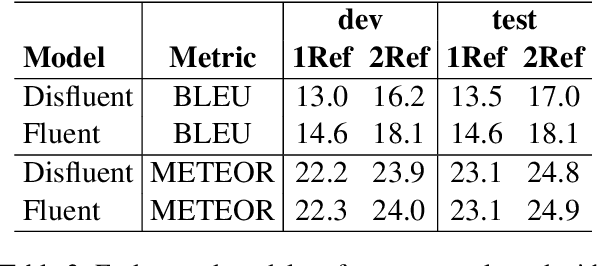
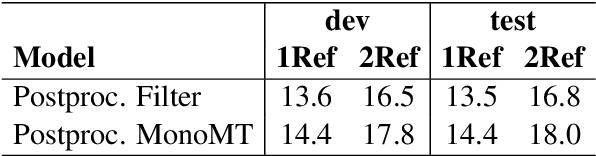
Spoken language translation applications for speech suffer due to conversational speech phenomena, particularly the presence of disfluencies. With the rise of end-to-end speech translation models, processing steps such as disfluency removal that were previously an intermediate step between speech recognition and machine translation need to be incorporated into model architectures. We use a sequence-to-sequence model to translate from noisy, disfluent speech to fluent text with disfluencies removed using the recently collected `copy-edited' references for the Fisher Spanish-English dataset. We are able to directly generate fluent translations and introduce considerations about how to evaluate success on this task. This work provides a baseline for a new task, the translation of conversational speech with joint removal of disfluencies.
Attention-Passing Models for Robust and Data-Efficient End-to-End Speech Translation
Apr 15, 2019Speech translation has traditionally been approached through cascaded models consisting of a speech recognizer trained on a corpus of transcribed speech, and a machine translation system trained on parallel texts. Several recent works have shown the feasibility of collapsing the cascade into a single, direct model that can be trained in an end-to-end fashion on a corpus of translated speech. However, experiments are inconclusive on whether the cascade or the direct model is stronger, and have only been conducted under the unrealistic assumption that both are trained on equal amounts of data, ignoring other available speech recognition and machine translation corpora. In this paper, we demonstrate that direct speech translation models require more data to perform well than cascaded models, and while they allow including auxiliary data through multi-task training, they are poor at exploiting such data, putting them at a severe disadvantage. As a remedy, we propose the use of end-to-end trainable models with two attention mechanisms, the first establishing source speech to source text alignments, the second modeling source to target text alignment. We show that such models naturally decompose into multi-task-trainable recognition and translation tasks and propose an attention-passing technique that alleviates error propagation issues in a previous formulation of a model with two attention stages. Our proposed model outperforms all examined baselines and is able to exploit auxiliary training data much more effectively than direct attentional models.
Learning Shared Encoding Representation for End-to-End Speech Recognition Models
Mar 31, 2019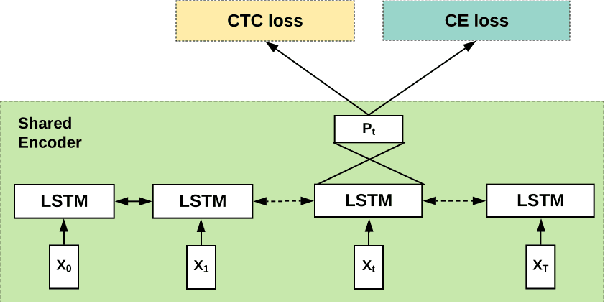

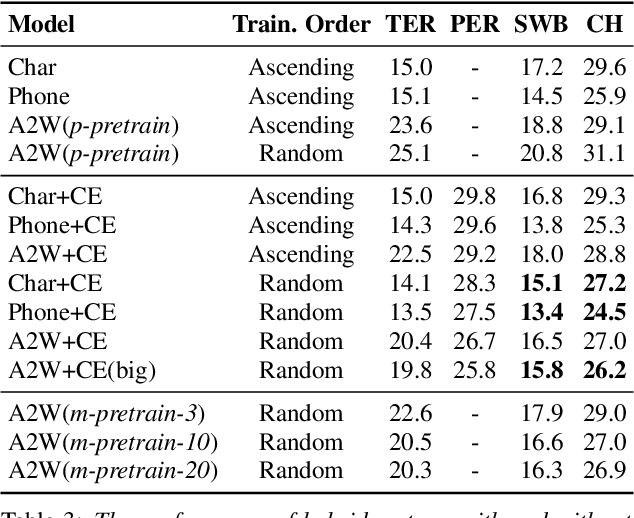
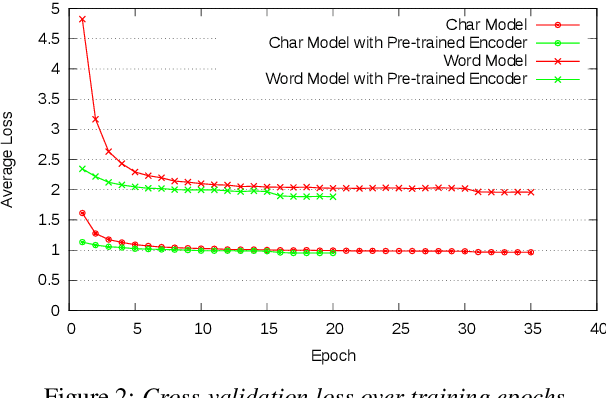
In this work, we learn a shared encoding representation for a multi-task neural network model optimized with connectionist temporal classification (CTC) and conventional framewise cross-entropy training criteria. Our experiments show that the multi-task training not only tackles the complexity of optimizing CTC models such as acoustic-to-word but also results in significant improvement compared to the plain-task training with an optimal setup. Furthermore, we propose to use the encoding representation learned by the multi-task network to initialize the encoder of attention-based models. Thereby, we train a deep attention-based end-to-end model with 10 long short-term memory (LSTM) layers of encoder which produces 12.2\% and 22.6\% word-error-rate on Switchboard and CallHome subsets of the Hub5 2000 evaluation.
Using multi-task learning to improve the performance of acoustic-to-word and conventional hybrid models
Feb 02, 2019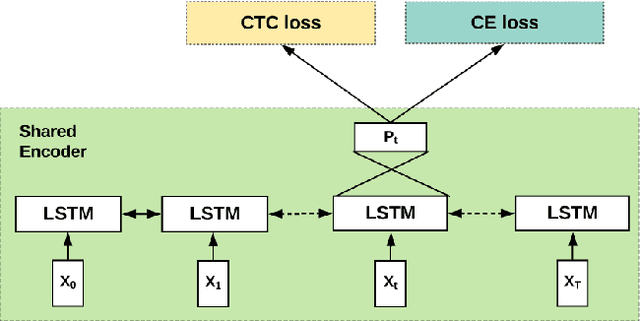
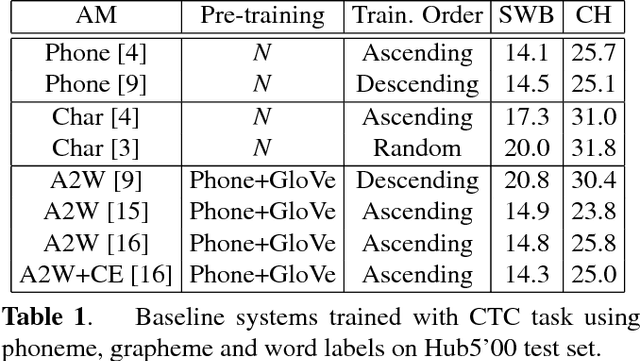
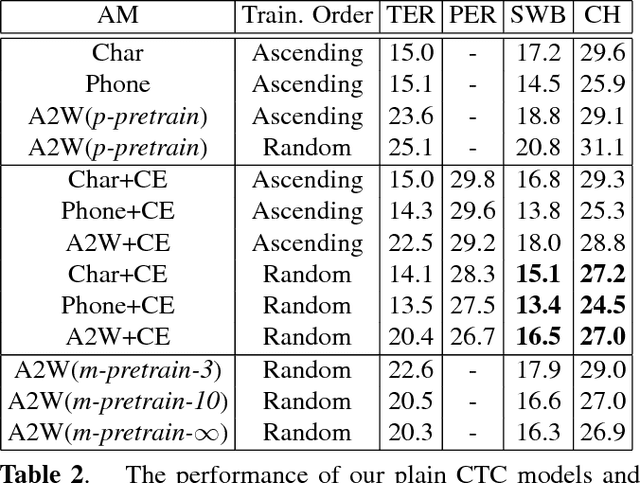
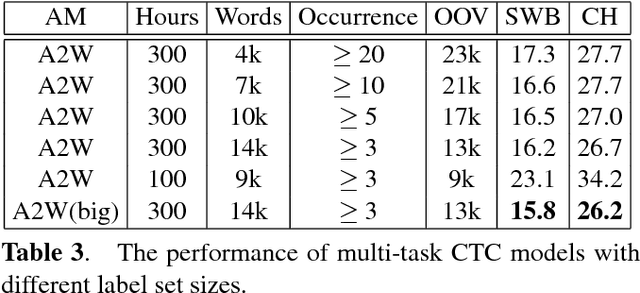
Acoustic-to-word (A2W) models that allow direct mapping from acoustic signals to word sequences are an appealing approach to end-to-end automatic speech recognition due to their simplicity. However, prior works have shown that modelling A2W typically encounters issues of data sparsity that prevent training such a model directly. So far, pre-training initialization is the only approach proposed to deal with this issue. In this work, we propose to build a shared neural network and optimize A2W and conventional hybrid models in a multi-task manner. Our results show that training an A2W model is much more stable with our multi-task model without pre-training initialization, and results in a significant improvement compared to a baseline model. Experiments also reveal that the performance of a hybrid acoustic model can be further improved when jointly training with a sequence-level optimization criterion such as acoustic-to-word.
Multi-task learning to improve natural language understanding
Dec 17, 2018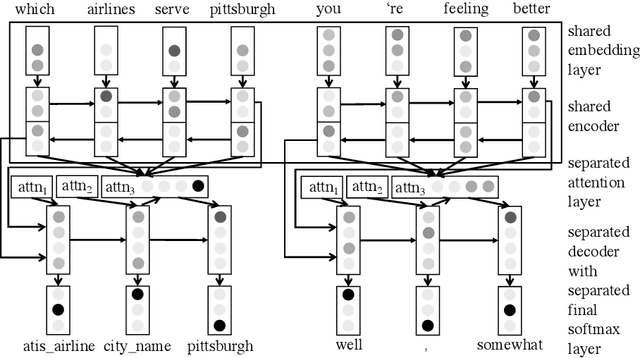
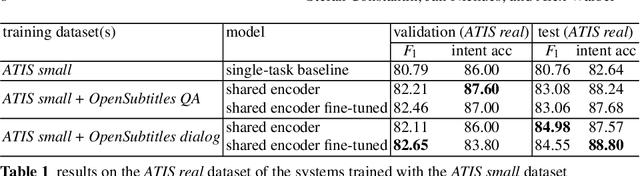

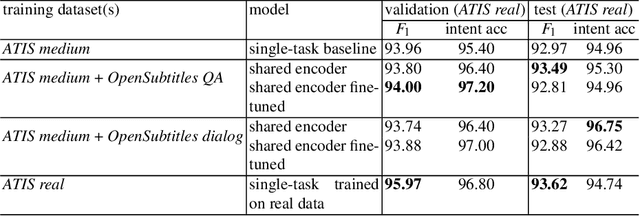
Recently advancements in sequence-to-sequence neural network architectures have led to an improved natural language understanding. When building a neural network-based Natural Language Understanding component, one main challenge is to collect enough training data. The generation of a synthetic dataset is an inexpensive and quick way to collect data. Since this data often has less variety than real natural language, neural networks often have problems to generalize to unseen utterances during testing. In this work, we address this challenge by using multi-task learning. We train out-of-domain real data alongside in-domain synthetic data to improve natural language understanding. We evaluate this approach in the domain of airline travel information with two synthetic datasets. As out-of-domain real data, we test two datasets based on the subtitles of movies and series. By using an attention-based encoder-decoder model, we were able to improve the F1-score over strong baselines from 80.76 % to 84.98 % in the smaller synthetic dataset.
Towards Fluent Translations from Disfluent Speech
Nov 07, 2018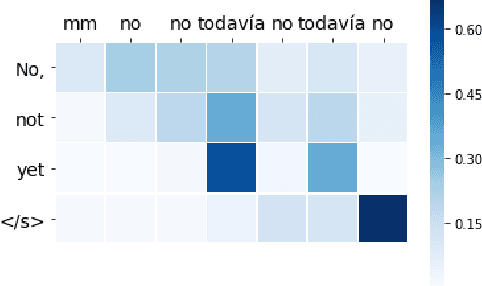
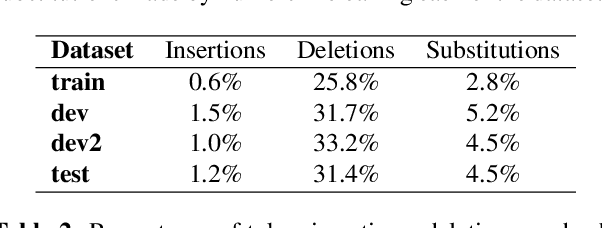
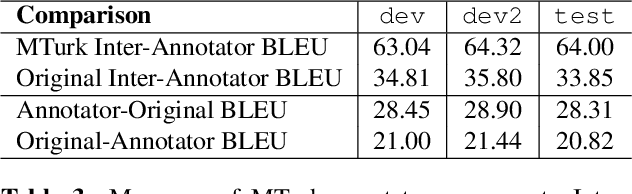
When translating from speech, special consideration for conversational speech phenomena such as disfluencies is necessary. Most machine translation training data consists of well-formed written texts, causing issues when translating spontaneous speech. Previous work has introduced an intermediate step between speech recognition (ASR) and machine translation (MT) to remove disfluencies, making the data better-matched to typical translation text and significantly improving performance. However, with the rise of end-to-end speech translation systems, this intermediate step must be incorporated into the sequence-to-sequence architecture. Further, though translated speech datasets exist, they are typically news or rehearsed speech without many disfluencies (e.g. TED), or the disfluencies are translated into the references (e.g. Fisher). To generate clean translations from disfluent speech, cleaned references are necessary for evaluation. We introduce a corpus of cleaned target data for the Fisher Spanish-English dataset for this task. We compare how different architectures handle disfluencies and provide a baseline for removing disfluencies in end-to-end translation.
Towards one-shot learning for rare-word translation with external experts
Sep 10, 2018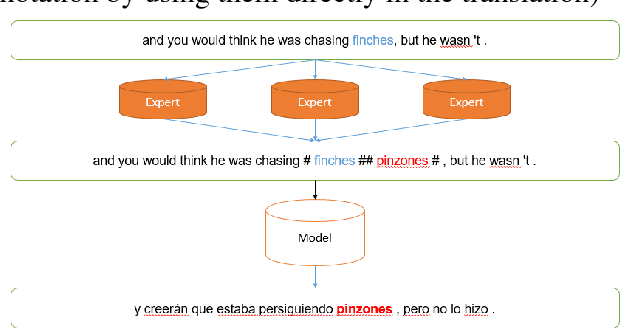
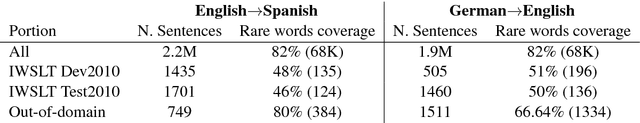

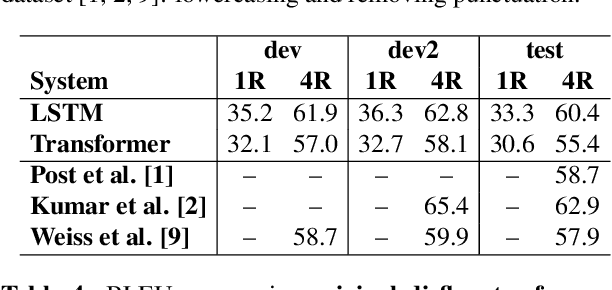
Neural machine translation (NMT) has significantly improved the quality of automatic translation models. One of the main challenges in current systems is the translation of rare words. We present a generic approach to address this weakness by having external models annotate the training data as Experts, and control the model-expert interaction with a pointer network and reinforcement learning. Our experiments using phrase-based models to simulate Experts to complement neural machine translation models show that the model can be trained to copy the annotations into the output consistently. We demonstrate the benefit of our proposed framework in outof-domain translation scenarios with only lexical resources, improving more than 1.0 BLEU point in both translation directions English to Spanish and German to English
Paraphrases as Foreign Languages in Multilingual Neural Machine Translation
Aug 25, 2018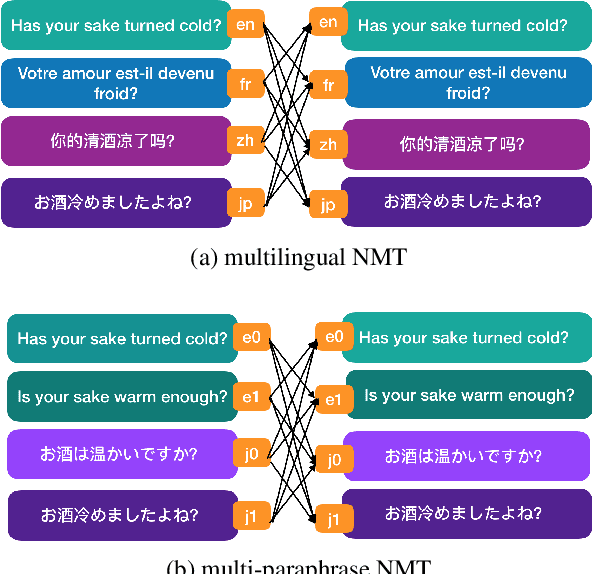

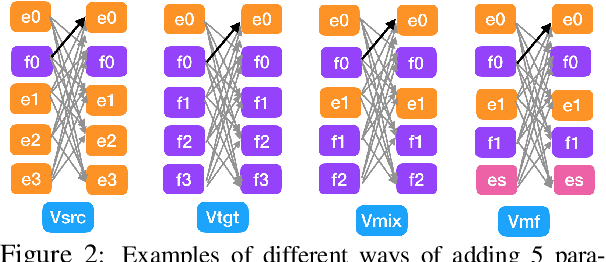
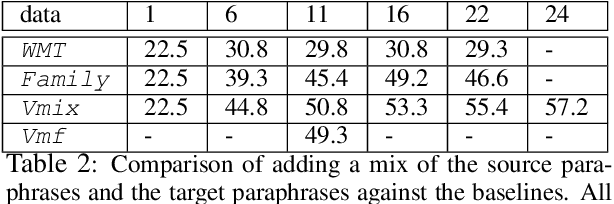
Using paraphrases, the expression of the same semantic meaning in different words, to improve generalization and translation performance is often useful. However, prior works only explore the use of paraphrases at the word or phrase level, not at the sentence or document level. Unlike previous works, we use different translations of the whole training data that are consistent in structure as paraphrases at the corpus level. Our corpus contains parallel paraphrases in multiple languages from various sources. We treat paraphrases as foreign languages, tag source sentences with paraphrase labels, and train in the style of multilingual Neural Machine Translation (NMT). Experimental results indicate that adding paraphrases improves the rare word translation, increases entropy and diversity in lexical choice. Moreover, adding the source paraphrases improves translation performance more effectively than adding the target paraphrases. Combining both the source and the target paraphrases boosts performance further; combining paraphrases with multilingual data also helps but has mixed performance. We achieve a BLEU score of 57.2 for French-to-English translation, training on 24 paraphrases of the Bible, which is ~+27 above the WMT'14 baseline.