 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate independence testing across two parties
Jul 08, 2022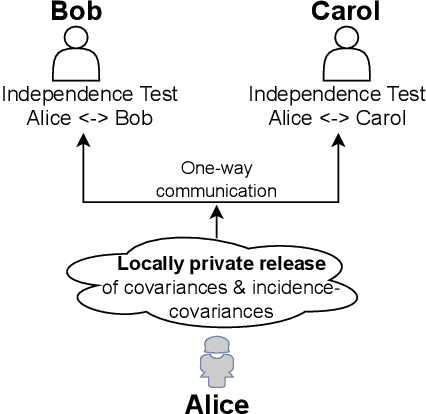

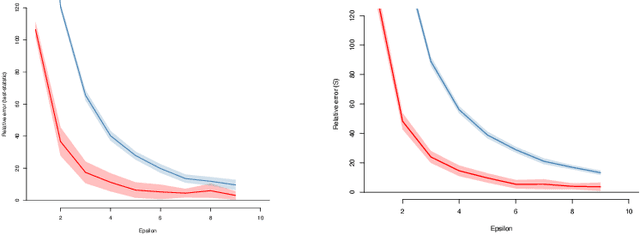
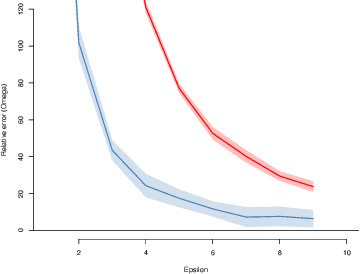
We introduce $\pi$-test, a privacy-preserving algorithm for testing statistical independence between data distributed across multiple parties. Our algorithm relies on privately estimating the distance correlation between datasets, a quantitative measure of independence introduced in Sz\'ekely et al. [2007]. We establish both additive and multiplicative error bounds on the utility of our differentially private test, which we believe will find applications in a variety of distributed hypothesis testing settings involving sensitive data.
Private and Byzantine-Proof Cooperative Decision-Making
May 27, 2022
The cooperative bandit problem is a multi-agent decision problem involving a group of agents that interact simultaneously with a multi-armed bandit, while communicating over a network with delays. The central idea in this problem is to design algorithms that can efficiently leverage communication to obtain improvements over acting in isolation. In this paper, we investigate the stochastic bandit problem under two settings - (a) when the agents wish to make their communication private with respect to the action sequence, and (b) when the agents can be byzantine, i.e., they provide (stochastically) incorrect information. For both these problem settings, we provide upper-confidence bound algorithms that obtain optimal regret while being (a) differentially-private and (b) tolerant to byzantine agents. Our decentralized algorithms require no information about the network of connectivity between agents, making them scalable to large dynamic systems. We test our algorithms on a competitive benchmark of random graphs and demonstrate their superior performance with respect to existing robust algorithms. We hope that our work serves as an important step towards creating distributed decision-making systems that maintain privacy.
Adaptive Methods for Aggregated Domain Generalization
Dec 23, 2021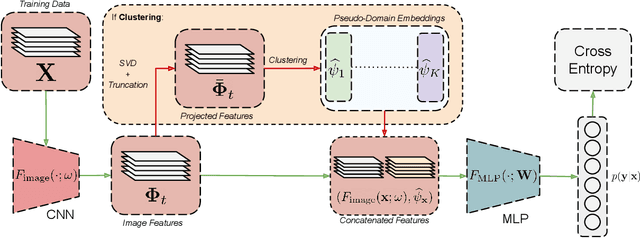
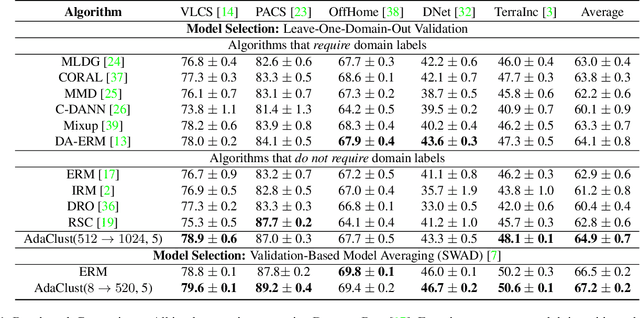
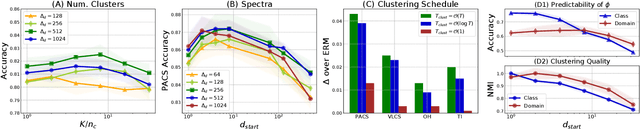
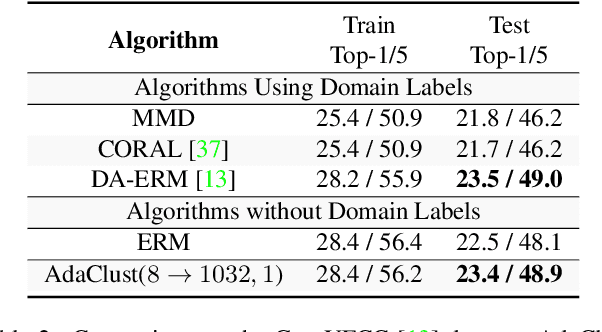
Domain generalization involves learning a classifier from a heterogeneous collection of training sources such that it generalizes to data drawn from similar unknown target domains, with applications in large-scale learning and personalized inference. In many settings, privacy concerns prohibit obtaining domain labels for the training data samples, and instead only have an aggregated collection of training points. Existing approaches that utilize domain labels to create domain-invariant feature representations are inapplicable in this setting, requiring alternative approaches to learn generalizable classifiers. In this paper, we propose a domain-adaptive approach to this problem, which operates in two steps: (a) we cluster training data within a carefully chosen feature space to create pseudo-domains, and (b) using these pseudo-domains we learn a domain-adaptive classifier that makes predictions using information about both the input and the pseudo-domain it belongs to. Our approach achieves state-of-the-art performance on a variety of domain generalization benchmarks without using domain labels whatsoever. Furthermore, we provide novel theoretical guarantees on domain generalization using cluster information. Our approach is amenable to ensemble-based methods and provides substantial gains even on large-scale benchmark datasets. The code can be found at: https://github.com/xavierohan/AdaClust_DomainBed
One More Step Towards Reality: Cooperative Bandits with Imperfect Communication
Nov 24, 2021


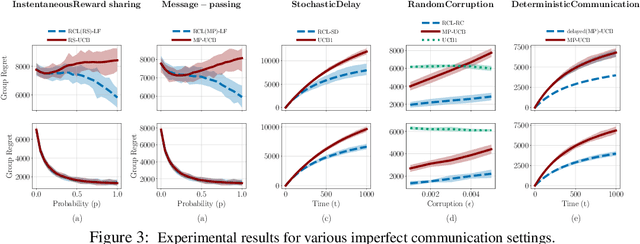
The cooperative bandit problem is increasingly becoming relevant due to its applications in large-scale decision-making. However, most research for this problem focuses exclusively on the setting with perfect communication, whereas in most real-world distributed settings, communication is often over stochastic networks, with arbitrary corruptions and delays. In this paper, we study cooperative bandit learning under three typical real-world communication scenarios, namely, (a) message-passing over stochastic time-varying networks, (b) instantaneous reward-sharing over a network with random delays, and (c) message-passing with adversarially corrupted rewards, including byzantine communication. For each of these environments, we propose decentralized algorithms that achieve competitive performance, along with near-optimal guarantees on the incurred group regret as well. Furthermore, in the setting with perfect communication, we present an improved delayed-update algorithm that outperforms the existing state-of-the-art on various network topologies. Finally, we present tight network-dependent minimax lower bounds on the group regret. Our proposed algorithms are straightforward to implement and obtain competitive empirical performance.
Investigating and Modeling the Dynamics of Long Ties
Sep 22, 2021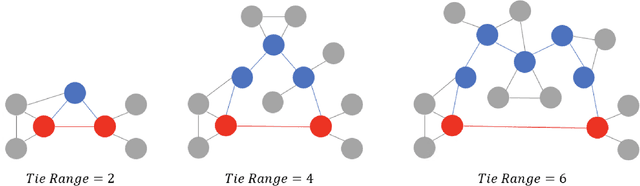
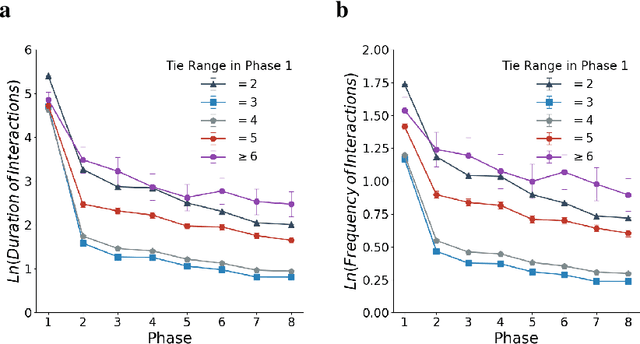
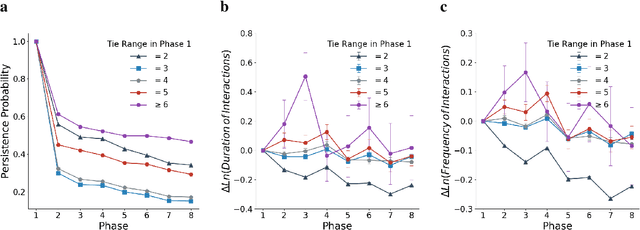
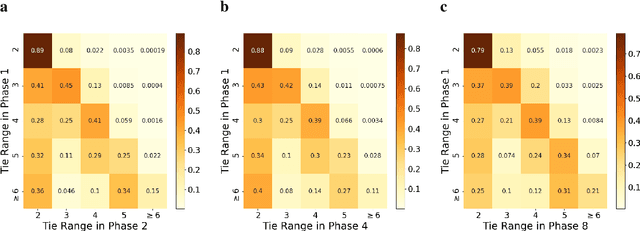
Long ties, the social ties that bridge different communities, are widely believed to play crucial roles in spreading novel information in social networks. However, some existing network theories and prediction models indicate that long ties might dissolve quickly or eventually become redundant, thus putting into question the long-term value of long ties. Our empirical analysis of real-world dynamic networks shows that contrary to such reasoning, long ties are more likely to persist than other social ties, and that many of them constantly function as social bridges without being embedded in local networks. Using a novel cost-benefit analysis model combined with machine learning, we show that long ties are highly beneficial, which instinctively motivates people to expend extra effort to maintain them. This partly explains why long ties are more persistent than what has been suggested by many existing theories and models. Overall, our study suggests the need for social interventions that can promote the formation of long ties, such as mixing people with diverse backgrounds.
Adaptive Methods for Real-World Domain Generalization
Mar 30, 2021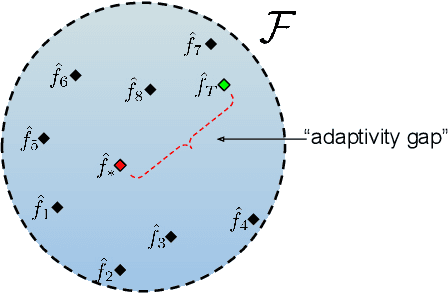

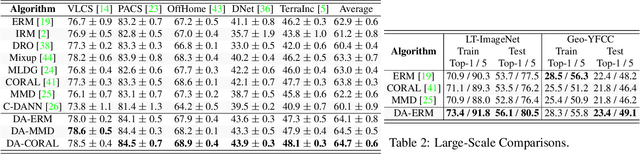
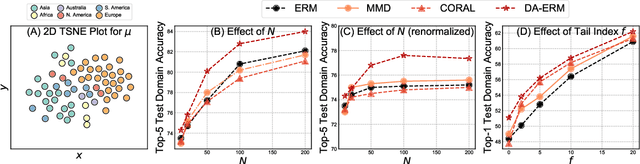
Invariant approaches have been remarkably successful in tackling the problem of domain generalization, where the objective is to perform inference on data distributions different from those used in training. In our work, we investigate whether it is possible to leverage domain information from the unseen test samples themselves. We propose a domain-adaptive approach consisting of two steps: a) we first learn a discriminative domain embedding from unsupervised training examples, and b) use this domain embedding as supplementary information to build a domain-adaptive model, that takes both the input as well as its domain into account while making predictions. For unseen domains, our method simply uses few unlabelled test examples to construct the domain embedding. This enables adaptive classification on any unseen domain. Our approach achieves state-of-the-art performance on various domain generalization benchmarks. In addition, we introduce the first real-world, large-scale domain generalization benchmark, Geo-YFCC, containing 1.1M samples over 40 training, 7 validation, and 15 test domains, orders of magnitude larger than prior work. We show that the existing approaches either do not scale to this dataset or underperform compared to the simple baseline of training a model on the union of data from all training domains. In contrast, our approach achieves a significant improvement.
Provably Efficient Cooperative Multi-Agent Reinforcement Learning with Function Approximation
Mar 08, 2021Reinforcement learning in cooperative multi-agent settings has recently advanced significantly in its scope, with applications in cooperative estimation for advertising, dynamic treatment regimes, distributed control, and federated learning. In this paper, we discuss the problem of cooperative multi-agent RL with function approximation, where a group of agents communicates with each other to jointly solve an episodic MDP. We demonstrate that via careful message-passing and cooperative value iteration, it is possible to achieve near-optimal no-regret learning even with a fixed constant communication budget. Next, we demonstrate that even in heterogeneous cooperative settings, it is possible to achieve Pareto-optimal no-regret learning with limited communication. Our work generalizes several ideas from the multi-agent contextual and multi-armed bandit literature to MDPs and reinforcement learning.
Differentially-Private Federated Linear Bandits
Oct 22, 2020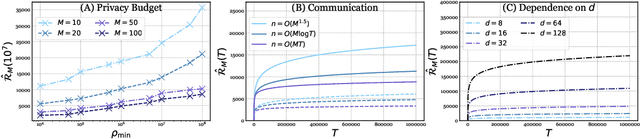
The rapid proliferation of decentralized learning systems mandates the need for differentially-private cooperative learning. In this paper, we study this in context of the contextual linear bandit: we consider a collection of agents cooperating to solve a common contextual bandit, while ensuring that their communication remains private. For this problem, we devise \textsc{FedUCB}, a multiagent private algorithm for both centralized and decentralized (peer-to-peer) federated learning. We provide a rigorous technical analysis of its utility in terms of regret, improving several results in cooperative bandit learning, and provide rigorous privacy guarantees as well. Our algorithms provide competitive performance both in terms of pseudoregret bounds and empirical benchmark performance in various multi-agent settings.
Cooperative Multi-Agent Bandits with Heavy Tails
Aug 14, 2020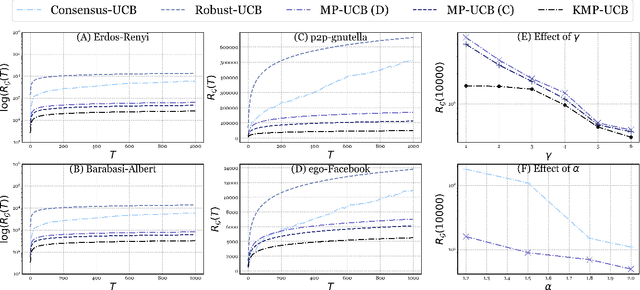
We study the heavy-tailed stochastic bandit problem in the cooperative multi-agent setting, where a group of agents interact with a common bandit problem, while communicating on a network with delays. Existing algorithms for the stochastic bandit in this setting utilize confidence intervals arising from an averaging-based communication protocol known as~\textit{running consensus}, that does not lend itself to robust estimation for heavy-tailed settings. We propose \textsc{MP-UCB}, a decentralized multi-agent algorithm for the cooperative stochastic bandit that incorporates robust estimation with a message-passing protocol. We prove optimal regret bounds for \textsc{MP-UCB} for several problem settings, and also demonstrate its superiority to existing methods. Furthermore, we establish the first lower bounds for the cooperative bandit problem, in addition to providing efficient algorithms for robust bandit estimation of location.
Kernel Methods for Cooperative Multi-Agent Contextual Bandits
Aug 14, 2020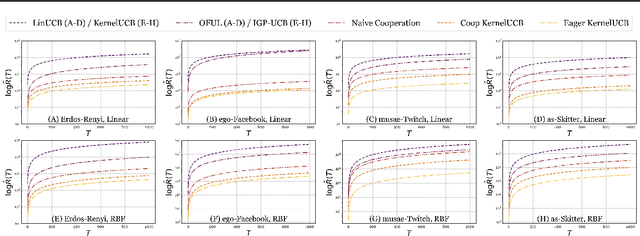
Cooperative multi-agent decision making involves a group of agents cooperatively solving learning problems while communicating over a network with delays. In this paper, we consider the kernelised contextual bandit problem, where the reward obtained by an agent is an arbitrary linear function of the contexts' images in the related reproducing kernel Hilbert space (RKHS), and a group of agents must cooperate to collectively solve their unique decision problems. For this problem, we propose \textsc{Coop-KernelUCB}, an algorithm that provides near-optimal bounds on the per-agent regret, and is both computationally and communicatively efficient. For special cases of the cooperative problem, we also provide variants of \textsc{Coop-KernelUCB} that provides optimal per-agent regret. In addition, our algorithm generalizes several existing results in the multi-agent bandit setting. Finally, on a series of both synthetic and real-world multi-agent network benchmarks, we demonstrate that our algorithm significantly outperforms existing benchmarks.