 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Environmental Sound Representation to Robustness of 2D CNN Models Against Adversarial Attacks
Apr 14, 2022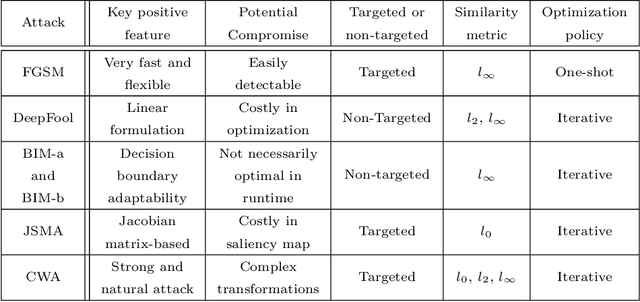
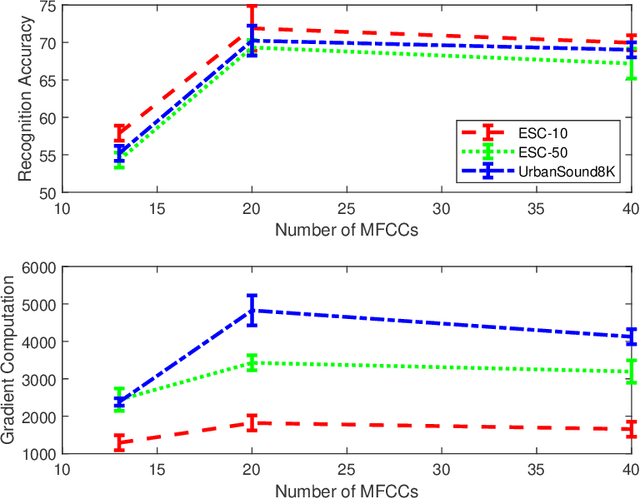
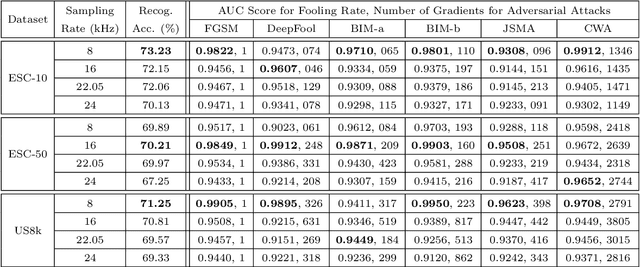
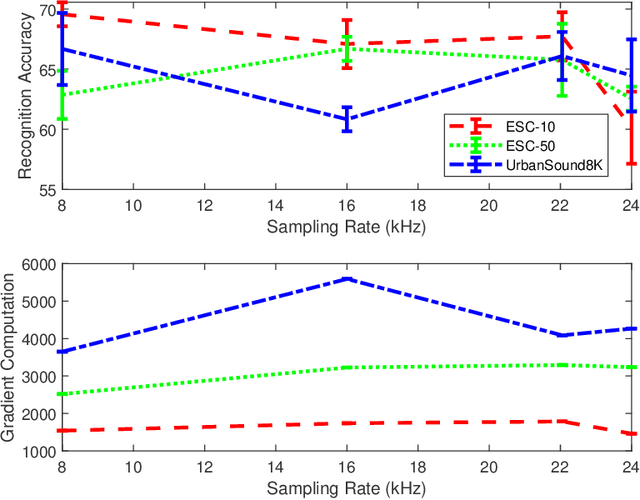
This paper investigates the impact of different standard environmental sound representations (spectrograms) on the recognition performance and adversarial attack robustness of a victim residual convolutional neural network, namely ResNet-18. Our main motivation for focusing on such a front-end classifier rather than other complex architectures is balancing recognition accuracy and the total number of training parameters. Herein, we measure the impact of different settings required for generating more informative Mel-frequency cepstral coefficient (MFCC), short-time Fourier transform (STFT), and discrete wavelet transform (DWT) representations on our front-end model. This measurement involves comparing the classification performance over the adversarial robustness. We demonstrate an inverse relationship between recognition accuracy and model robustness against six benchmarking attack algorithms on the balance of average budgets allocated by the adversary and the attack cost. Moreover, our experimental results have shown that while the ResNet-18 model trained on DWT spectrograms achieves a high recognition accuracy, attacking this model is relatively more costly for the adversary than other 2D representations. We also report some results on different convolutional neural network architectures such as ResNet-34, ResNet-56, AlexNet, and GoogLeNet, SB-CNN, and LSTM-based.
Texture Characterization of Histopathologic Images Using Ecological Diversity Measures and Discrete Wavelet Transform
Feb 27, 2022
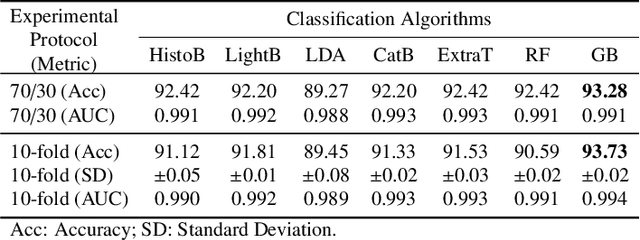
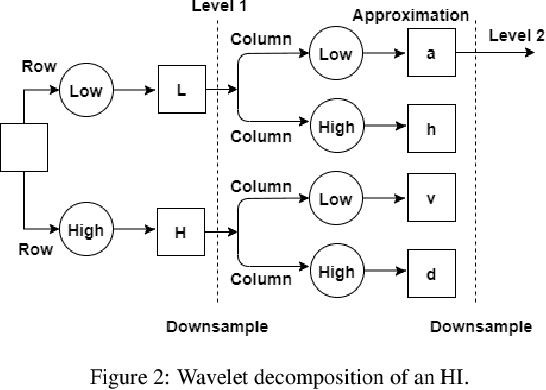
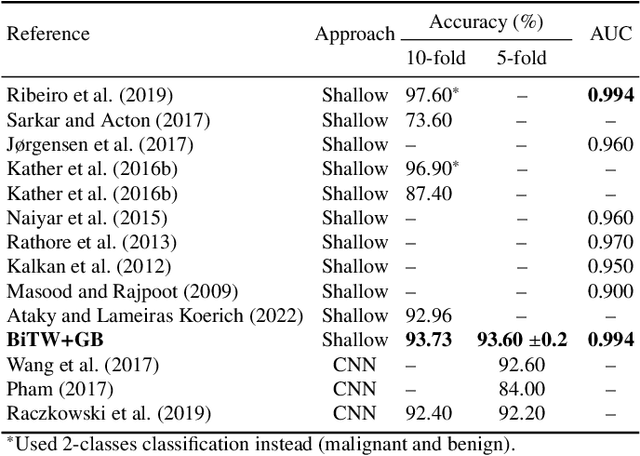
Breast cancer is a health problem that affects mainly the female population. An early detection increases the chances of effective treatment, improving the prognosis of the disease. In this regard, computational tools have been proposed to assist the specialist in interpreting the breast digital image exam, providing features for detecting and diagnosing tumors and cancerous cells. Nonetheless, detecting tumors with a high sensitivity rate and reducing the false positives rate is still challenging. Texture descriptors have been quite popular in medical image analysis, particularly in histopathologic images (HI), due to the variability of both the texture found in such images and the tissue appearance due to irregularity in the staining process. Such variability may exist depending on differences in staining protocol such as fixation, inconsistency in the staining condition, and reagents, either between laboratories or in the same laboratory. Textural feature extraction for quantifying HI information in a discriminant way is challenging given the distribution of intrinsic properties of such images forms a non-deterministic complex system. This paper proposes a method for characterizing texture across HIs with a considerable success rate. By employing ecological diversity measures and discrete wavelet transform, it is possible to quantify the intrinsic properties of such images with promising accuracy on two HI datasets compared with state-of-the-art methods.
1D CNN Architectures for Music Genre Classification
May 15, 2021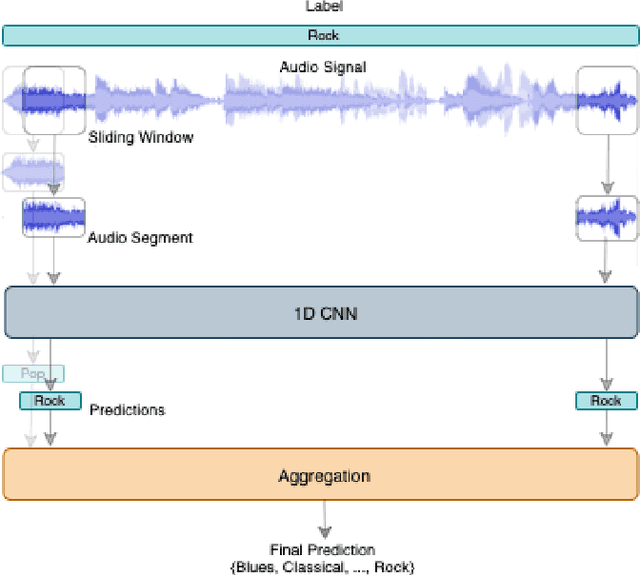
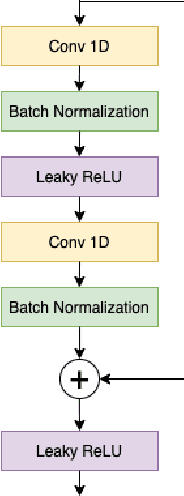
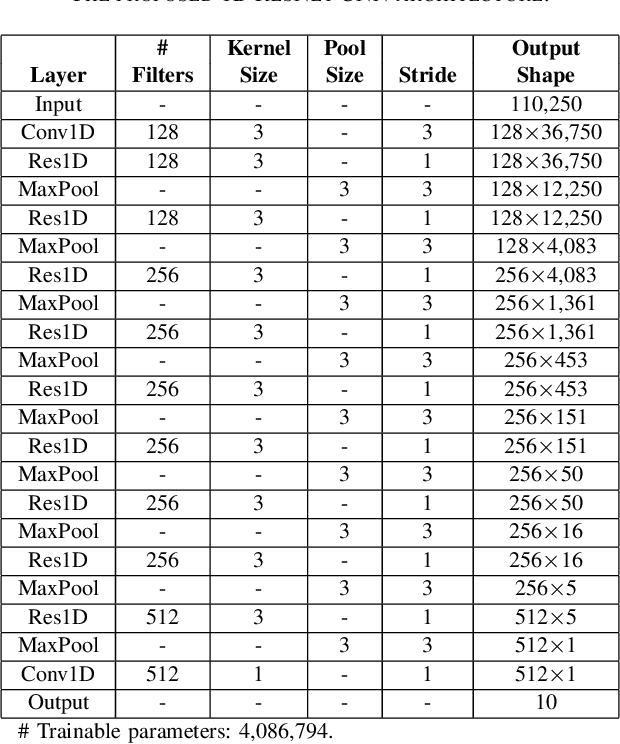
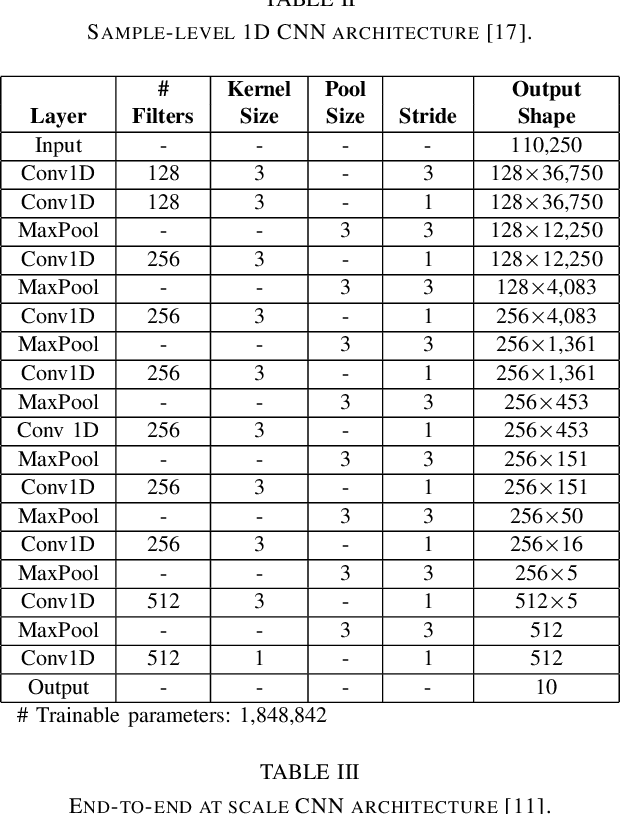
This paper proposes a 1D residual convolutional neural network (CNN) architecture for music genre classification and compares it with other recent 1D CNN architectures. The 1D CNNs learn a representation and a discriminant directly from the raw audio signal. Several convolutional layers capture the time-frequency characteristics of the audio signal and learn various filters relevant to the music genre recognition task. The proposed approach splits the audio signal into overlapped segments using a sliding window to comply with the fixed-length input constraint of the 1D CNNs. As a result, music genre classification can be carried out on a single audio segment or on the aggregation of the predictions on several audio segments, which improves the final accuracy. The performance of the proposed 1D residual CNN is assessed on a public dataset of 1,000 audio clips. The experimental results have shown that it achieves 80.93% of mean accuracy in classifying music genres and outperforms other 1D CNN architectures.
Cyclic Defense GAN Against Speech Adversarial Attacks
Mar 26, 2021
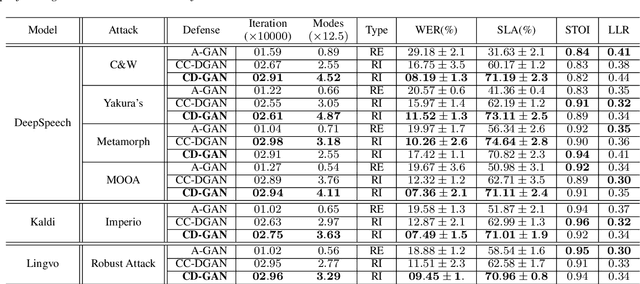
This paper proposes a new defense approach for counteracting with state-of-the-art white and black-box adversarial attack algorithms. Our approach fits in the category of implicit reactive defense algorithms since it does not directly manipulate the potentially malicious input signals. Instead, it reconstructs a similar signal with a synthesized spectrogram using a cyclic generative adversarial network. This cyclic framework helps to yield a stable generative model. Finally, we feed the reconstructed signal into the speech-to-text model for transcription. The conducted experiments on targeted and non-targeted adversarial attacks developed for attacking DeepSpeech, Kaldi, and Lingvo models demonstrate the proposed defense's effectiveness in adverse scenarios.
Towards Robust Speech-to-Text Adversarial Attack
Mar 15, 2021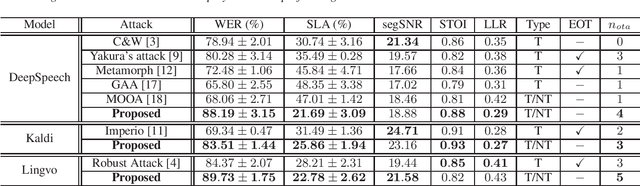
This paper introduces a novel adversarial algorithm for attacking the state-of-the-art speech-to-text systems, namely DeepSpeech, Kaldi, and Lingvo. Our approach is based on developing an extension for the conventional distortion condition of the adversarial optimization formulation using the Cram\`er integral probability metric. Minimizing over this metric, which measures the discrepancies between original and adversarial samples' distributions, contributes to crafting signals very close to the subspace of legitimate speech recordings. This helps to yield more robust adversarial signals against playback over-the-air without employing neither costly expectation over transformation operations nor static room impulse response simulations. Our approach outperforms other targeted and non-targeted algorithms in terms of word error rate and sentence-level-accuracy with competitive performance on the crafted adversarial signals' quality. Compared to seven other strong white and black-box adversarial attacks, our proposed approach is considerably more resilient against multiple consecutive playbacks over-the-air, corroborating its higher robustness in noisy environments.
Multi-Discriminator Sobolev Defense-GAN Against Adversarial Attacks for End-to-End Speech Systems
Mar 15, 2021

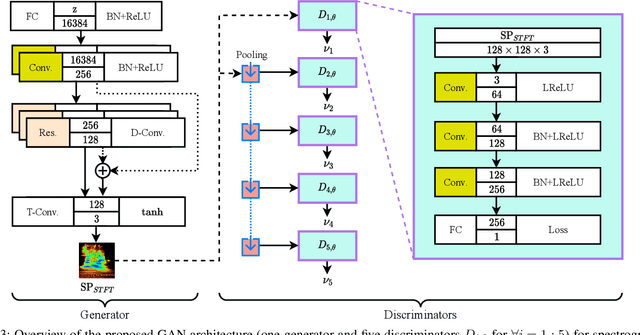
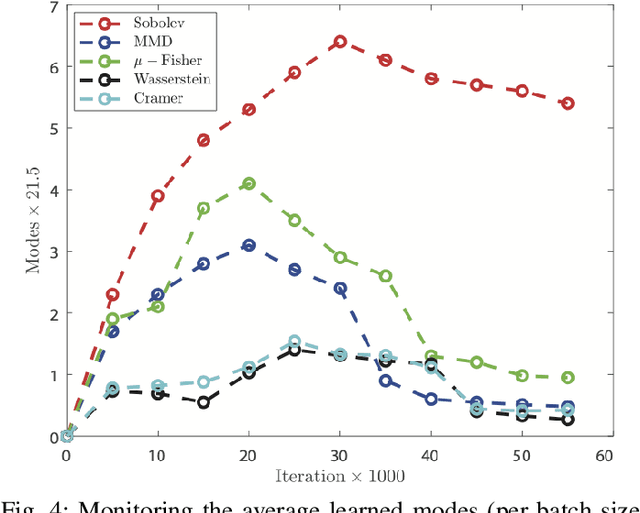
This paper introduces a defense approach against end-to-end adversarial attacks developed for cutting-edge speech-to-text systems. The proposed defense algorithm has four major steps. First, we represent speech signals with 2D spectrograms using the short-time Fourier transform. Second, we iteratively find a safe vector using a spectrogram subspace projection operation. This operation minimizes the chordal distance adjustment between spectrograms with an additional regularization term. Third, we synthesize a spectrogram with such a safe vector using a novel GAN architecture trained with Sobolev integral probability metric. To improve the model's performance in terms of stability and the total number of learned modes, we impose an additional constraint on the generator network. Finally, we reconstruct the signal from the synthesized spectrogram and the Griffin-Lim phase approximation technique. We evaluate the proposed defense approach against six strong white and black-box adversarial attacks benchmarked on DeepSpeech, Kaldi, and Lingvo models. Our experimental results show that our algorithm outperforms other state-of-the-art defense algorithms both in terms of accuracy and signal quality.
A Novel Bio-Inspired Texture Descriptor based on Biodiversity and Taxonomic Measures
Mar 07, 2021
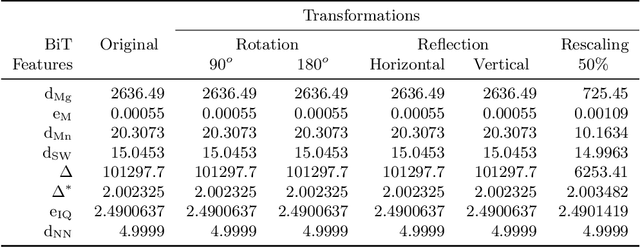
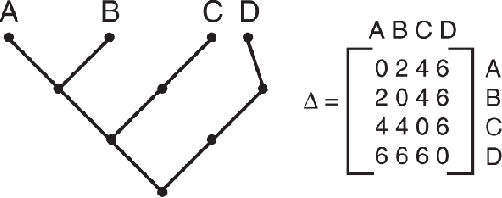
Texture can be defined as the change of image intensity that forms repetitive patterns, resulting from physical properties of the object's roughness or differences in a reflection on the surface. Considering that texture forms a complex system of patterns in a non-deterministic way, biodiversity concepts can help texture characterization in images. This paper proposes a novel approach capable of quantifying such a complex system of diverse patterns through species diversity and richness and taxonomic distinctiveness. The proposed approach considers each image channel as a species ecosystem and computes species diversity and richness measures as well as taxonomic measures to describe the texture. The proposed approach takes advantage of ecological patterns' invariance characteristics to build a permutation, rotation, and translation invariant descriptor. Experimental results on three datasets of natural texture images and two datasets of histopathological images have shown that the proposed texture descriptor has advantages over several texture descriptors and deep methods.
Machine Learning Methods for Histopathological Image Analysis: A Review
Feb 07, 2021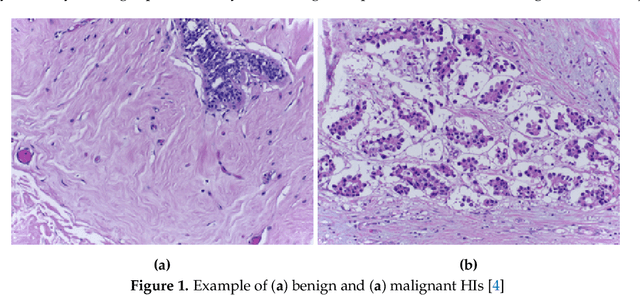
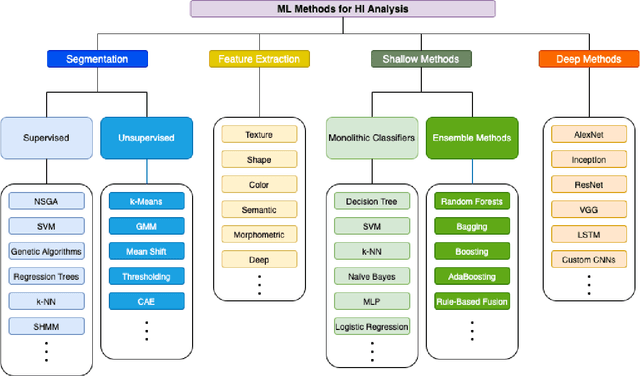
Histopathological images (HIs) are the gold standard for evaluating some types of tumors for cancer diagnosis. The analysis of such images is not only time and resource consuming, but also very challenging even for experienced pathologists, resulting in inter- and intra-observer disagreements. One of the ways of accelerating such an analysis is to use computer-aided diagnosis (CAD) systems. In this paper, we present a review on machine learning methods for histopathological image analysis, including shallow and deep learning methods. We also cover the most common tasks in HI analysis, such as segmentation and feature extraction. In addition, we present a list of publicly available and private datasets that have been used in HI research.
Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks
Nov 18, 2020
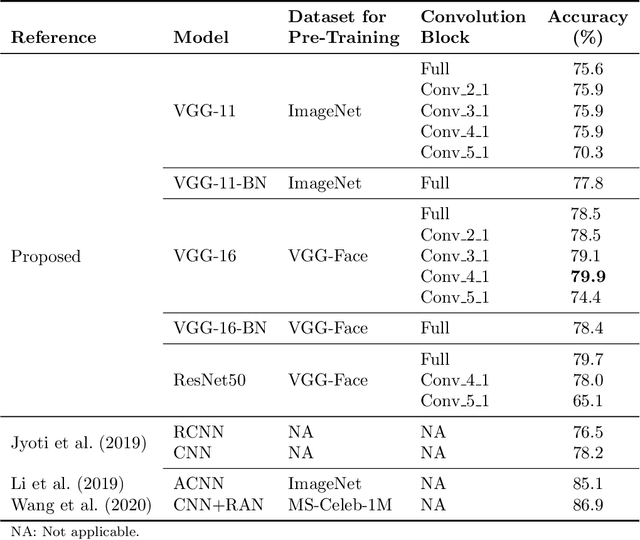
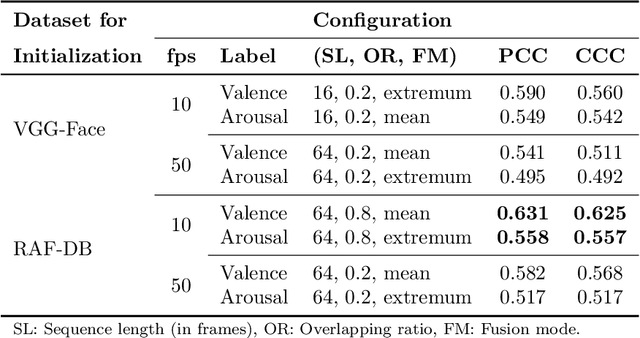
The attention in affect computing and emotion recognition has increased in the last decade. Facial expressions are one of the most powerful ways for depicting specific patterns in human behavior and describing human emotional state. Nevertheless, even for humans, identifying facial expressions is difficult, and automatic video-based systems for facial expression recognition (FER) have often suffered from variations in expressions among individuals, and from a lack of diverse and cross-culture training datasets. However, with video sequences captured in-the-wild and more complex emotion representation such as dimensional models, deep FER systems have the ability to learn more discriminative feature representations. In this paper, we present a survey of the state-of-the-art approaches based on convolutional neural networks (CNNs) for long video sequences recorded with in-the-wild settings, by considering the continuous emotion space of valence and arousal. Since few studies have used 3D-CNN for FER systems and dimensional representation of emotions, we propose an inflated 3D-CNN architecture, allowing for weight inflation of pre-trained 2D-CNN model, in order to operate the essential transfer learning for our video-based application. As a baseline, we also considered a 2D-CNN architecture cascaded network with a long short term memory network, therefore we could finally conclude with a model comparison over two approaches for spatiotemporal representation of facial features and performing the regression of valence/arousal values for emotion prediction. The experimental results on RAF-DB and SEWA-DB datasets have shown that these fine-tuned architectures allow to effectively encode the spatiotemporal information from raw pixel images, and achieved far better results than the current state-of-the-art.
Class-Conditional Defense GAN Against End-to-End Speech Attacks
Oct 22, 2020
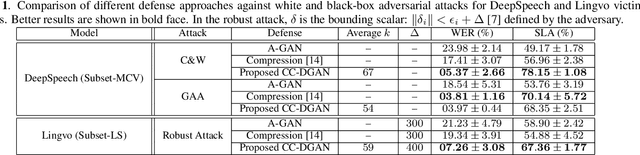

In this paper we propose a novel defense approach against end-to-end adversarial attacks developed to fool advanced speech-to-text systems such as DeepSpeech and Lingvo. Unlike conventional defense approaches, the proposed approach does not directly employ low-level transformations such as autoencoding a given input signal aiming at removing potential adversarial perturbation. Instead of that, we find an optimal input vector for a class conditional generative adversarial network through minimizing the relative chordal distance adjustment between a given test input and the generator network. Then, we reconstruct the 1D signal from the synthesized spectrogram and the original phase information derived from the given input signal. Hence, this reconstruction does not add any extra noise to the signal and according to our experimental results, our defense-GAN considerably outperforms conventional defense algorithms both in terms of word error rate and sentence level recognition accuracy.