 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackprop Diffusion is Biologically Plausible
Dec 10, 2019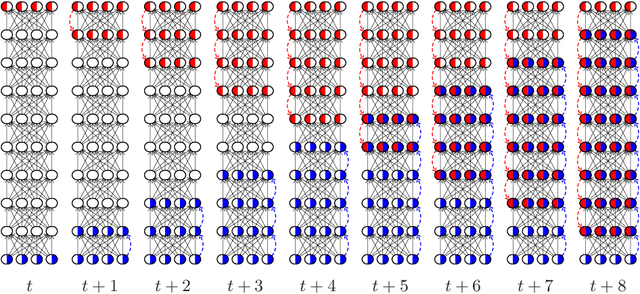


The Backpropagation algorithm relies on the abstraction of using a neural model that gets rid of the notion of time, since the input is mapped instantaneously to the output. In this paper, we claim that this abstraction of ignoring time, along with the abrupt input changes that occur when feeding the training set, are in fact the reasons why, in some papers, Backprop biological plausibility is regarded as an arguable issue. We show that as soon as a deep feedforward network operates with neurons with time-delayed response, the backprop weight update turns out to be the basic equation of a biologically plausible diffusion process based on forward-backward waves. We also show that such a process very well approximates the gradient for inputs that are not too fast with respect to the depth of the network. These remarks somewhat disclose the diffusion process behind the backprop equation and leads us to interpret the corresponding algorithm as a degeneration of a more general diffusion process that takes place also in neural networks with cyclic connections.
Condition monitoring and early diagnostics methodologies for hydropower plants
Nov 13, 2019
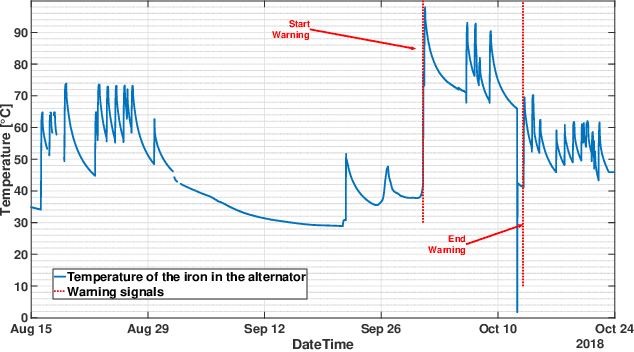
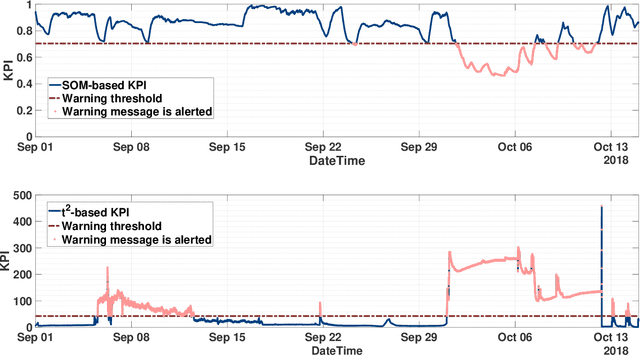
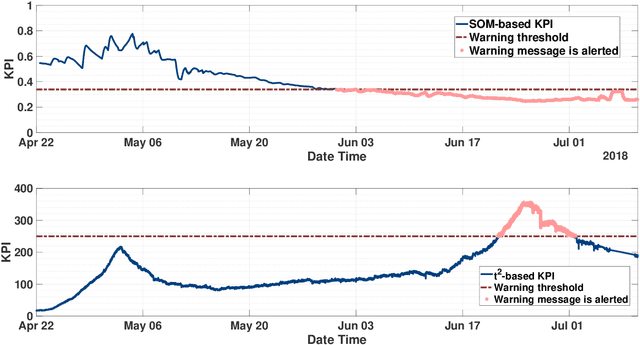
Hydropower plants are one of the most convenient option for power generation, as they generate energy exploiting a renewable source, they have relatively low operating and maintenance costs, and they may be used to provide ancillary services, exploiting the large reservoirs of available water. The recent advances in Information and Communication Technologies (ICT) and in machine learning methodologies are seen as fundamental enablers to upgrade and modernize the current operation of most hydropower plants, in terms of condition monitoring, early diagnostics and eventually predictive maintenance. While very few works, or running technologies, have been documented so far for the hydro case, in this paper we propose a novel Key Performance Indicator (KPI) that we have recently developed and tested on operating hydropower plants. In particular, we show that after more than one year of operation it has been able to identify several faults, and to support the operation and maintenance tasks of plant operators. Also, we show that the proposed KPI outperforms conventional multivariable process control charts, like the Hotelling $t_2$ index.
A Scalable Predictive Maintenance Model for Detecting Wind Turbine Component Failures Based on SCADA Data
Oct 22, 2019
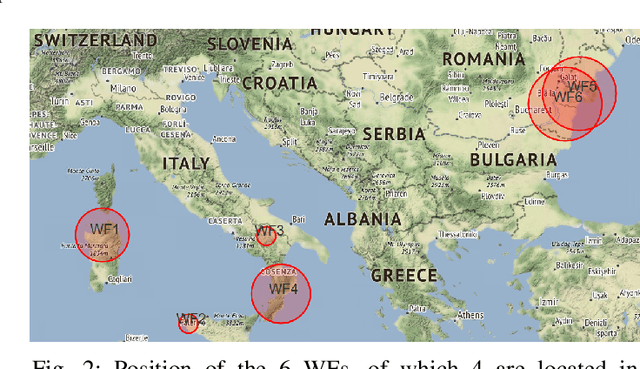

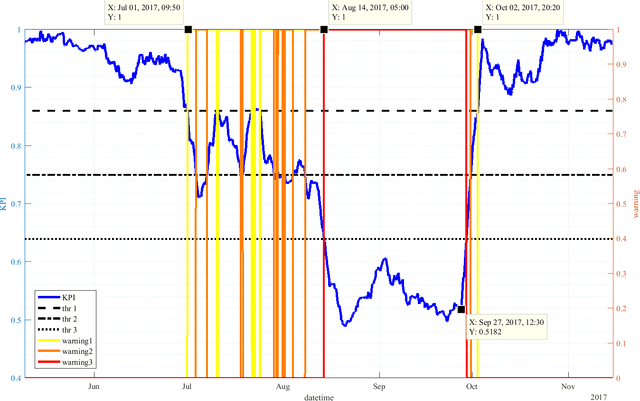
In this work, a novel predictive maintenance system is presented and applied to the main components of wind turbines. The proposed model is based on machine learning and statistical process control tools applied to SCADA (Supervisory Control And Data Acquisition) data of critical components. The test campaign was divided into two stages: a first two years long offline test, and a second one year long real-time test. The offline test used historical faults from six wind farms located in Italy and Romania, corresponding to a total of 150 wind turbines and an overall installed nominal power of 283 MW. The results demonstrate outstanding capabilities of anomaly prediction up to 2 months before device unscheduled downtime. Furthermore, the real-time 12-months test confirms the ability of the proposed system to detect several anomalies, therefore allowing the operators to identify the root causes, and to schedule maintenance actions before reaching a catastrophic stage.
A Machine Learning Model for Long-Term Power Generation Forecasting at Bidding Zone Level
Oct 08, 2019
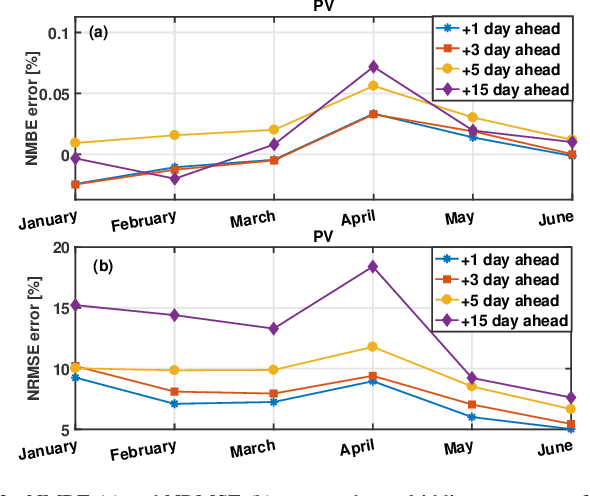
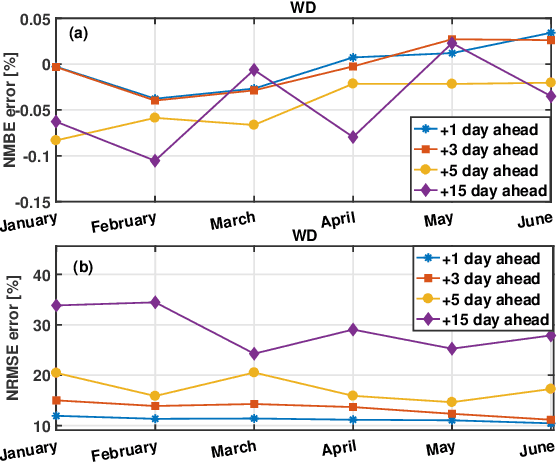
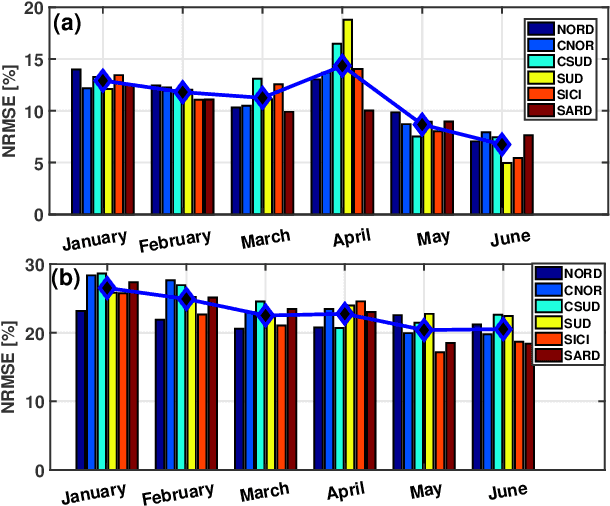
The increasing penetration level of energy generation from renewable sources is demanding for more accurate and reliable forecasting tools to support classic power grid operations (e.g., unit commitment, electricity market clearing or maintenance planning). For this purpose, many physical models have been employed, and more recently many statistical or machine learning algorithms, and data-driven methods in general, are becoming subject of intense research. While generally the power research community focuses on power forecasting at the level of single plants, in a short future horizon of time, in this time we are interested in aggregated macro-area power generation (i.e., in a territory of size greater than 100000 km^2) with a future horizon of interest up to 15 days ahead. Real data are used to validate the proposed forecasting methodology on a test set of several months.
Learning Visual Features Under Motion Invariance
Sep 01, 2019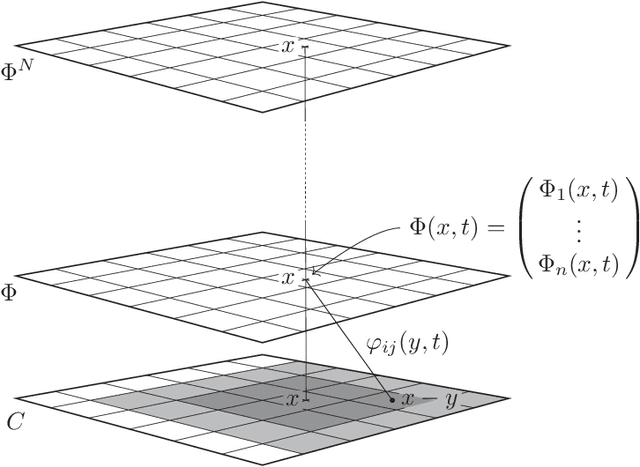

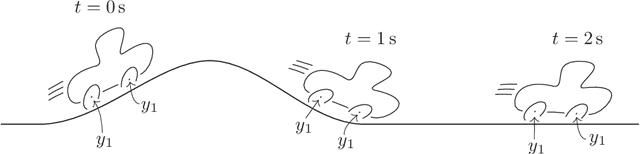
Humans are continuously exposed to a stream of visual data with a natural temporal structure. However, most successful computer vision algorithms work at image level, completely discarding the precious information carried by motion. In this paper, we claim that processing visual streams naturally leads to formulate the motion invariance principle, which enables the construction of a new theory of learning that originates from variational principles, just like in physics. Such principled approach is well suited for a discussion on a number of interesting questions that arise in vision, and it offers a well-posed computational scheme for the discovery of convolutional filters over the retina. Differently from traditional convolutional networks, which need massive supervision, the proposed theory offers a truly new scenario for the unsupervised processing of video signals, where features are extracted in a multi-layer architecture with motion invariance. While the theory enables the implementation of novel computer vision systems, it also sheds light on the role of information-based principles to drive possible biological solutions.
On the Role of Time in Learning
Jul 14, 2019By and large the process of learning concepts that are embedded in time is regarded as quite a mature research topic. Hidden Markov models, recurrent neural networks are, amongst others, successful approaches to learning from temporal data. In this paper, we claim that the dominant approach minimizing appropriate risk functions defined over time by classic stochastic gradient might miss the deep interpretation of time given in other fields like physics. We show that a recent reformulation of learning according to the principle of Least Cognitive Action is better suited whenever time is involved in learning. The principle gives rise to a learning process that is driven by differential equations, that can somehow descrive the process within the same framework as other laws of nature.
Spatiotemporal Local Propagation
Jul 11, 2019
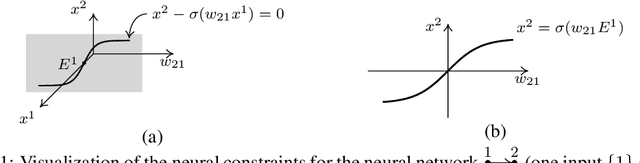
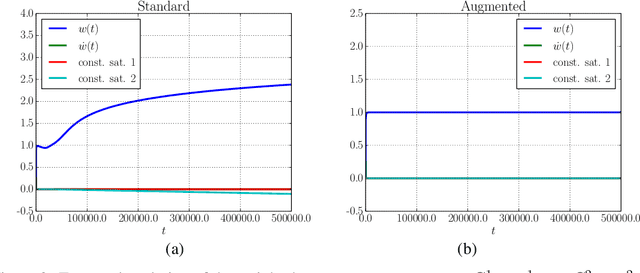
This paper proposes an in-depth re-thinking of neural computation that parallels apparently unrelated laws of physics, that are formulated in the variational framework of the least action principle. The theory holds for neural networks that are also based on any digraph, and the resulting computational scheme exhibits the intriguing property of being truly biologically plausible. The scheme, which is referred to as SpatioTemporal Local Propagation (STLP), is local in both space and time. Space locality comes from the expression of the network connections by an appropriate Lagrangian term, so as the corresponding computational scheme does not need the backpropagation (BP) of the error, while temporal locality is the outcome of the variational formulation of the problem. Overall, in addition to conquering the often invoked biological plausibility missed by BP, the locality in both space and time that arises from the proposed theory can neither be exhibited by Backpropagation Through Time (BPTT) nor by Real-Time Recurrent Learning (RTRL).
Least Action Principles and Well-Posed Learning Problems
Jul 04, 2019
Machine Learning algorithms are typically regarded as appropriate optimization schemes for minimizing risk functions that are constructed on the training set, which conveys statistical flavor to the corresponding learning problem. When the focus is shifted on perception, which is inherently interwound with time, recent alternative formulations of learning have been proposed that rely on the principle of Least Cognitive Action, which very much reminds us of the Least Action Principle in mechanics. In this paper, we discuss different forms of the cognitive action and show the well-posedness of learning. In particular, unlike the special case of the action in mechanics, where the stationarity is typically gained on saddle points, we prove the existence of the minimum of a special form of cognitive action, which yields forth-order differential equations of learning. We also briefly discuss the dissipative behavior of these equations that turns out to characterize the process of learning.
Day-Ahead Hourly Forecasting of Power Generation from Photovoltaic Plants
Feb 26, 2019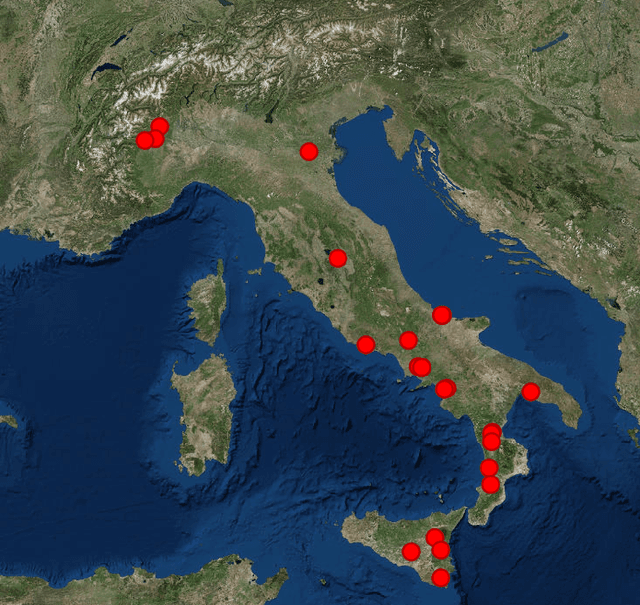
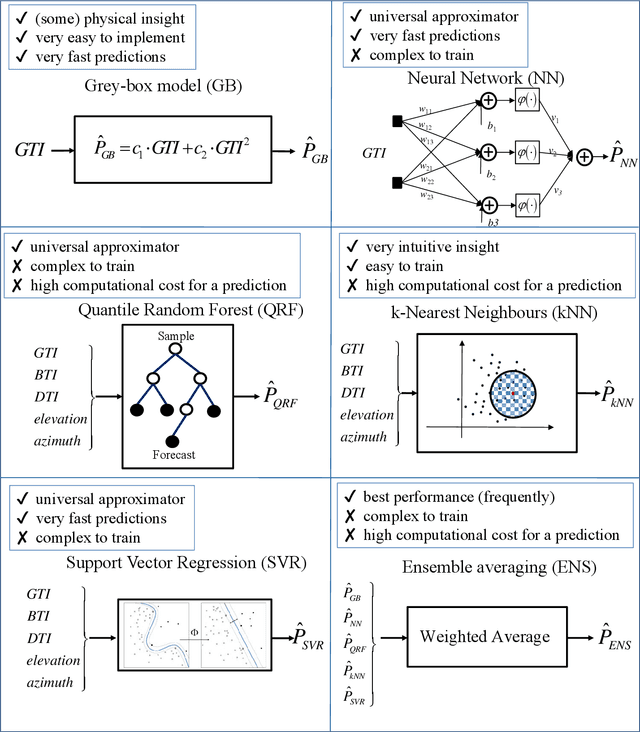
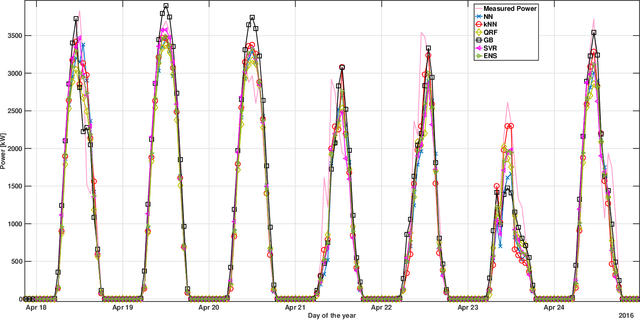
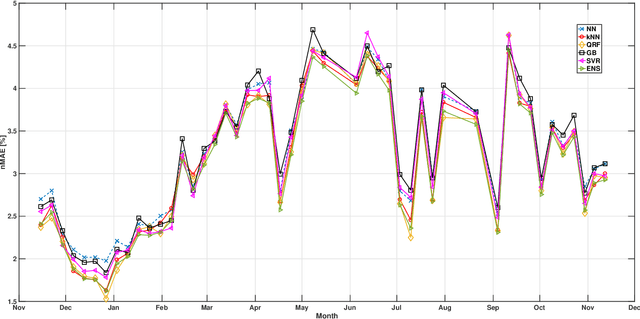
The ability to accurately forecast power generation from renewable sources is nowadays recognised as a fundamental skill to improve the operation of power systems. Despite the general interest of the power community in this topic, it is not always simple to compare different forecasting methodologies, and infer the impact of single components in providing accurate predictions. In this paper we extensively compare simple forecasting methodologies with more sophisticated ones over 32 photovoltaic plants of different size and technology over a whole year. Also, we try to evaluate the impact of weather conditions and weather forecasts on the prediction of PV power generation.
* Preprint of IEEE Transactions of Sustainable Energy, Vol. 9, Issue 2, pp. 831 - 842 (2018)
Predictive Maintenance in Photovoltaic Plants with a Big Data Approach
Jan 29, 2019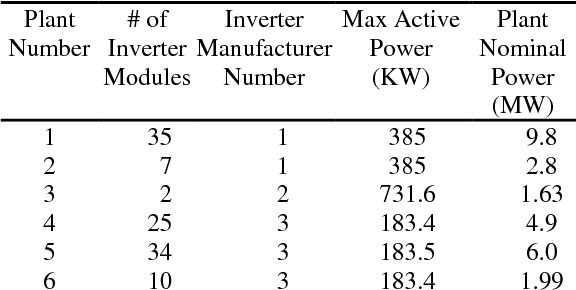
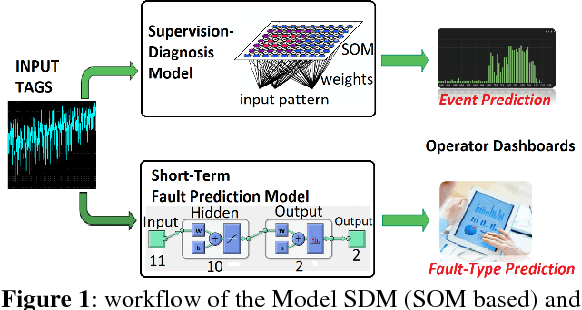
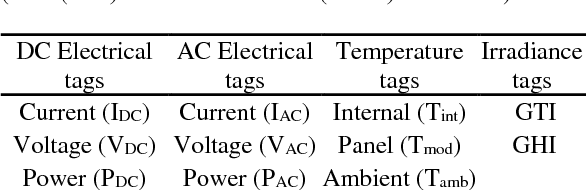
This paper presents a novel and flexible solution for fault prediction based on data collected from SCADA system. Fault prediction is offered at two different levels based on a data-driven approach: (a) generic fault/status prediction and (b) specific fault class prediction, implemented by means of two different machine learning based modules built on an unsupervised clustering algorithm and a Pattern Recognition Neural Network, respectively. Model has been assessed on a park of six photovoltaic (PV) plants up to 10 MW and on more than one hundred inverter modules of three different technology brands. The results indicate that the proposed method is effective in (a) predicting incipient generic faults up to 7 days in advance with sensitivity up to 95% and (b) anticipating damage of specific fault classes with times ranging from few hours up to 7 days. The model is easily deployable for on-line monitoring of anomalies on new PV plants and technologies, requiring only the availability of historical SCADA and fault data, fault taxonomy and inverter electrical datasheet. Keywords: Data Mining, Fault Prediction, Inverter Module, Key Performance Indicator, Lost Production
* Preprint of the 33rd EUPVSEC Proceeding, 25-29 September 2017, Amsterdam. Plenary Presentation