 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training Reduces Information and Improves Transferability
Aug 21, 2020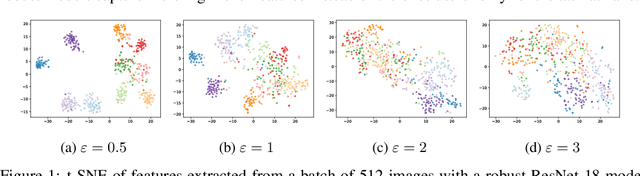
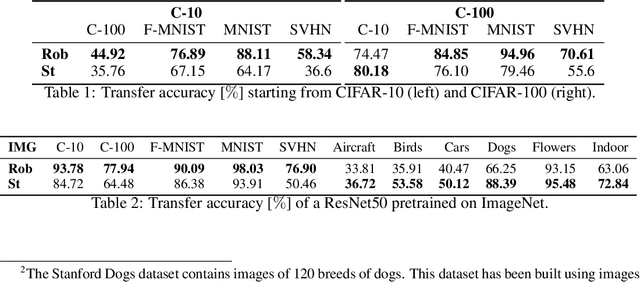
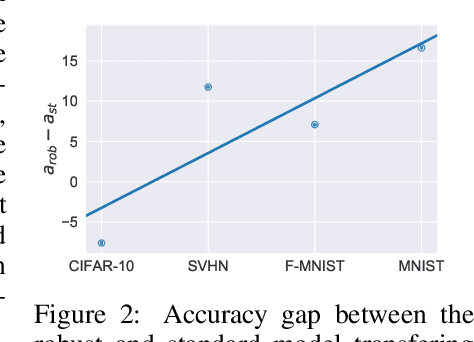
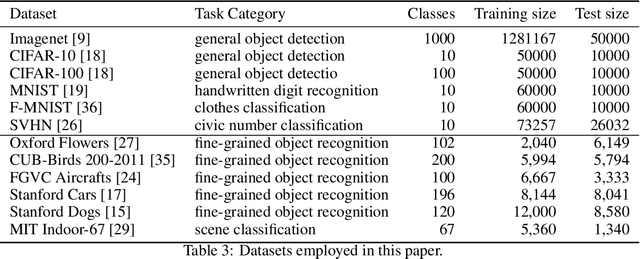
Recent results show that features of adversarially trained networks for classification, in addition to being robust, enable desirable properties such as invertibility. The latter property may seem counter-intuitive as it is widely accepted by the community that classification models should only capture the minimal information (features) required for the task. Motivated by this discrepancy, we investigate the dual relationship between Adversarial Training and Information Theory. We show that the Adversarial Training can improve linear transferability to new tasks, from which arises a new trade-off between transferability of representations and accuracy on the source task. We validate our results employing robust networks trained on CIFAR-10, CIFAR-100 and ImageNet on several datasets. Moreover, we show that Adversarial Training reduces Fisher information of representations about the input and of the weights about the task, and we provide a theoretical argument which explains the invertibility of deterministic networks without violating the principle of minimality. Finally, we leverage our theoretical insights to remarkably improve the quality of reconstructed images through inversion.
Layout Generation and Completion with Self-attention
Jun 25, 2020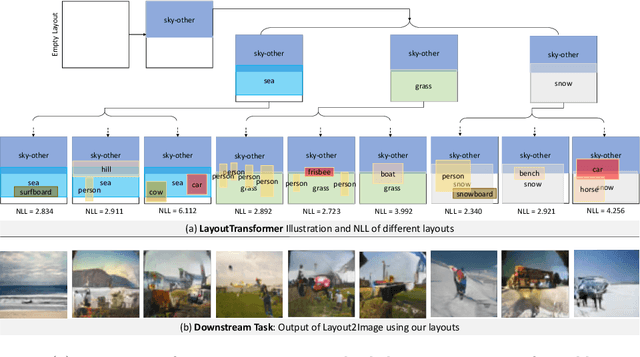
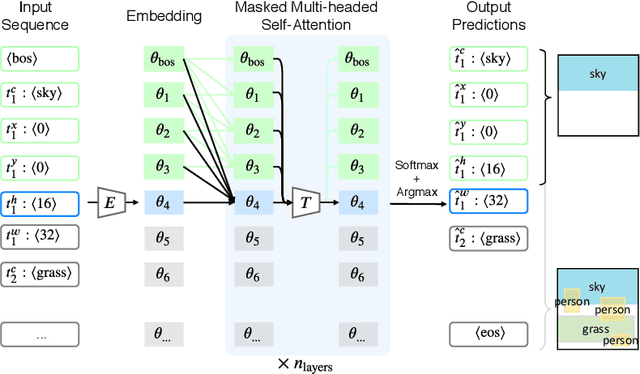

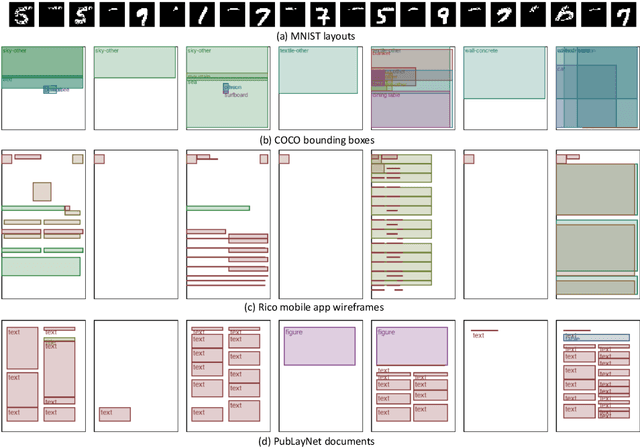
We address the problem of layout generation for diverse domains such as images, documents, and mobile applications. A layout is a set of graphical elements, belonging to one or more categories, placed together in a meaningful way. Generating a new layout or extending an existing layout requires understanding the relationships between these graphical elements. To do this, we propose a novel framework, LayoutTransformer, that leverages a self-attention based approach to learn contextual relationships between layout elements and generate layouts in a given domain. The proposed model improves upon the state-of-the-art approaches in layout generation in four ways. First, our model can generate a new layout either from an empty set or add more elements to a partial layout starting from an initial set of elements. Second, as the approach is attention-based, we can visualize which previous elements the model is attending to predict the next element, thereby providing an interpretable sequence of layout elements. Third, our model can easily scale to support both a large number of element categories and a large number of elements per layout. Finally, the model also produces an embedding for various element categories, which can be used to explore the relationships between the categories. We demonstrate with experiments that our model can produce meaningful layouts in diverse settings such as object bounding boxes in scenes (COCO bounding boxes), documents (PubLayNet), and mobile applications (RICO dataset).
Forgetting Outside the Box: Scrubbing Deep Networks of Information Accessible from Input-Output Observations
Mar 16, 2020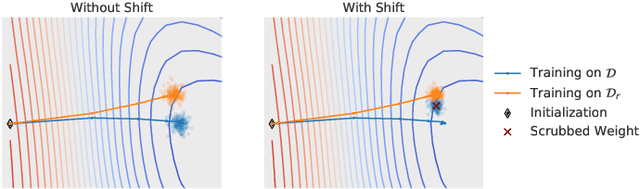
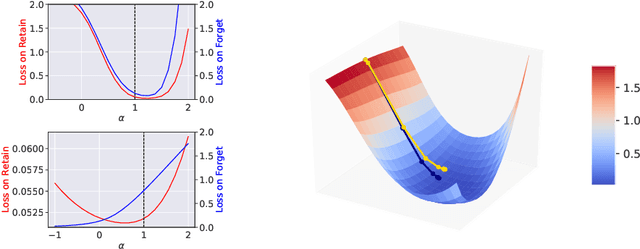
We describe a procedure for removing dependency on a cohort of training data from a trained deep network that improves upon and generalizes previous methods to different readout functions and can be extended to ensure forgetting in the activations of the network. We introduce a new bound on how much information can be extracted per query about the forgotten cohort from a black-box network for which only the input-output behavior is observed. The proposed forgetting procedure has a deterministic part derived from the differential equations of a linearized version of the model, and a stochastic part that ensures information destruction by adding noise tailored to the geometry of the loss landscape. We exploit the connections between the activation and weight dynamics of a DNN inspired by Neural Tangent Kernels to compute the information in the activations.
TextTubes for Detecting Curved Text in the Wild
Dec 19, 2019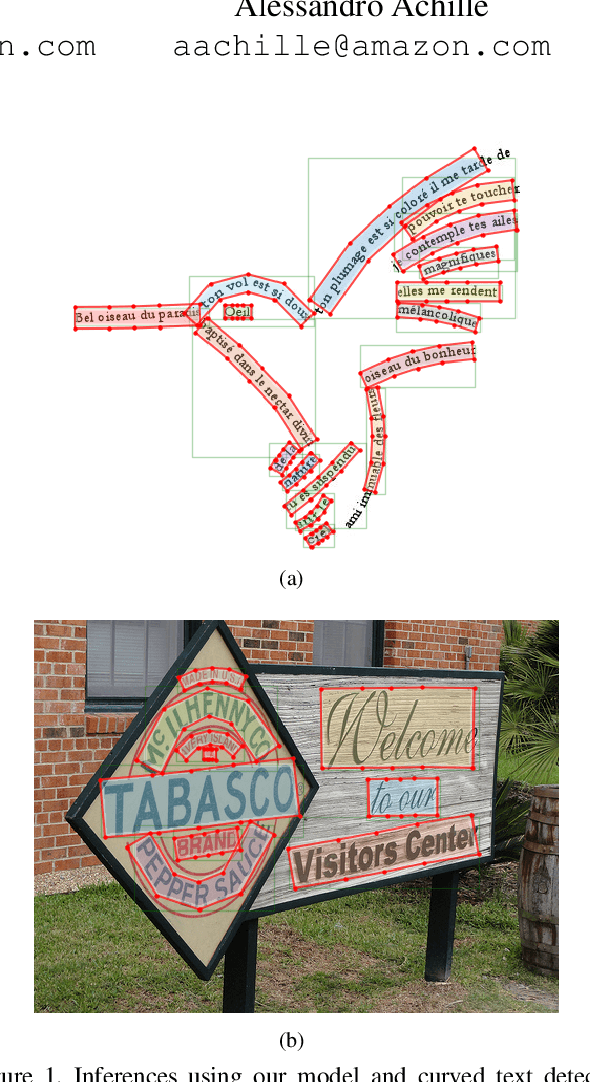
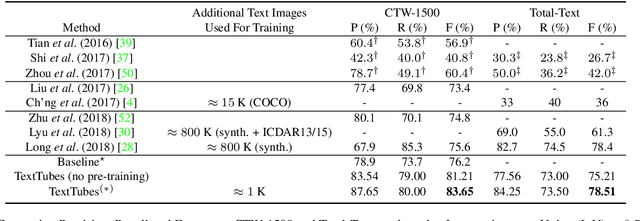

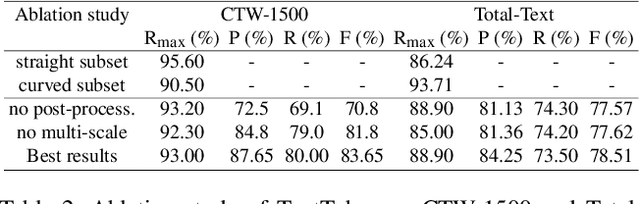
We present a detector for curved text in natural images. We model scene text instances as tubes around their medial axes and introduce a parametrization-invariant loss function. We train a two-stage curved text detector, and evaluate it on the curved text benchmarks CTW-1500 and Total-Text. Our approach achieves state-of-the-art results or improves upon them, notably for CTW-1500 by over 8 percentage points in F-score.
Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks
Nov 25, 2019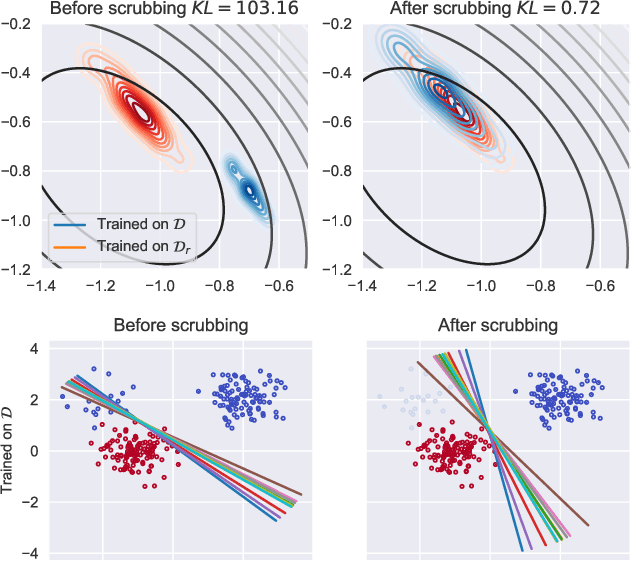
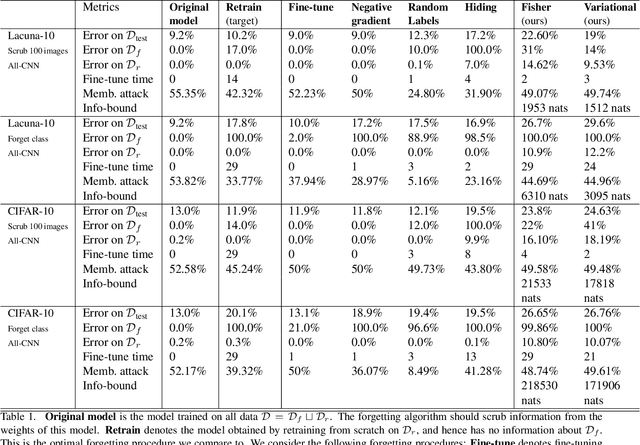
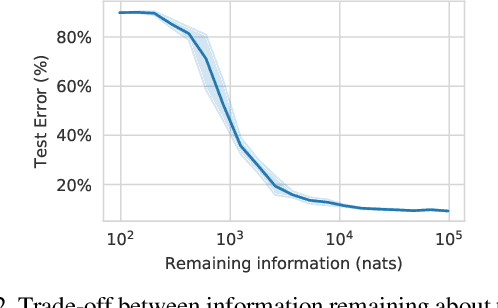
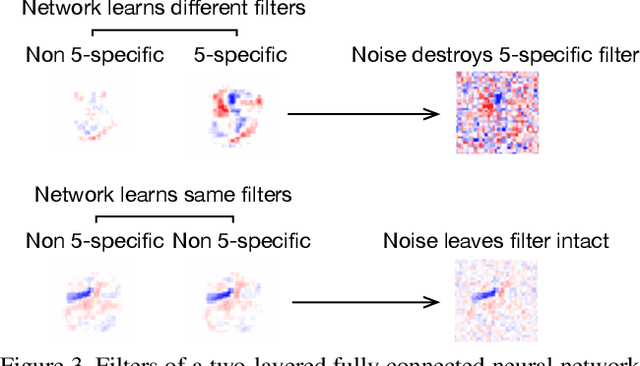
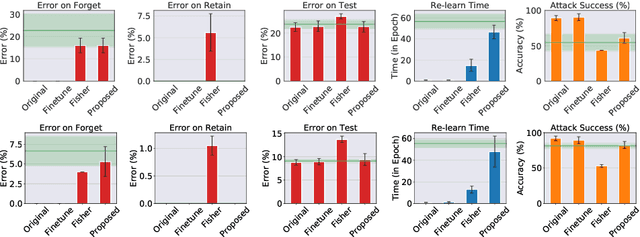
We explore the problem of selectively forgetting a particular set of data used for training a deep neural network. While the effects of the data to be forgotten can be hidden from the output of the network, insights may still be gleaned by probing deep into its weights. We propose a method for "scrubbing" the weights clean of information about a particular set of training data. The method does not require retraining from scratch, nor access to the data originally used for training. Instead, the weights are modified so that any probing function of the weights, computed with no knowledge of the random seed used for training, is indistinguishable from the same function applied to the weights of a network trained without the data to be forgotten. This condition is a generalized and weaker form of Differential Privacy. Exploiting ideas related to the stability of stochastic gradient descent, we introduce an upper-bound on the amount of information remaining in the weights, which can be estimated efficiently even for deep neural networks.
Toward Understanding Catastrophic Forgetting in Continual Learning
Aug 02, 2019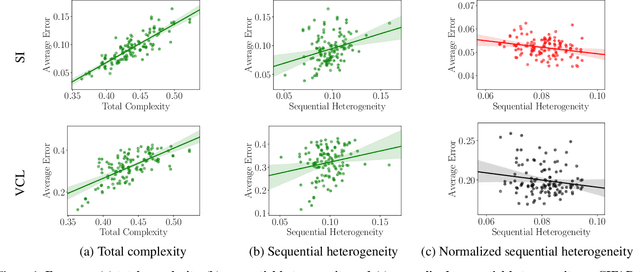
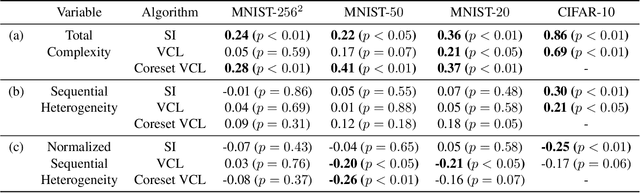
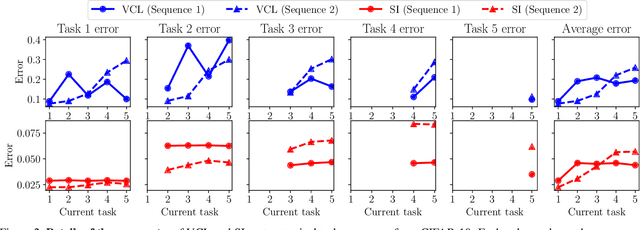
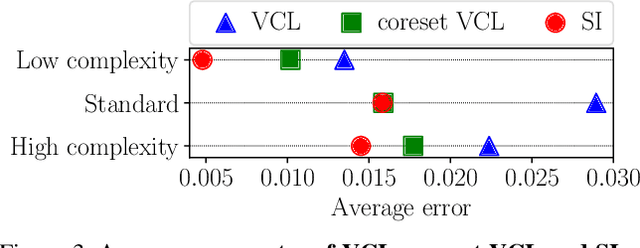
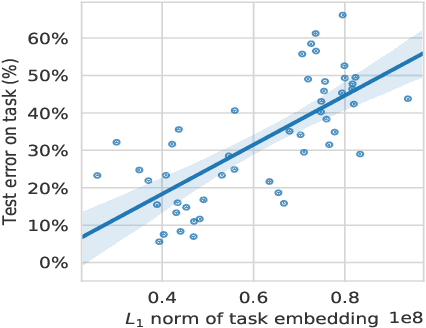
We study the relationship between catastrophic forgetting and properties of task sequences. In particular, given a sequence of tasks, we would like to understand which properties of this sequence influence the error rates of continual learning algorithms trained on the sequence. To this end, we propose a new procedure that makes use of recent developments in task space modeling as well as correlation analysis to specify and analyze the properties we are interested in. As an application, we apply our procedure to study two properties of a task sequence: (1) total complexity and (2) sequential heterogeneity. We show that error rates are strongly and positively correlated to a task sequence's total complexity for some state-of-the-art algorithms. We also show that, surprisingly, the error rates have no or even negative correlations in some cases to sequential heterogeneity. Our findings suggest directions for improving continual learning benchmarks and methods.
Where is the Information in a Deep Neural Network?
Jun 04, 2019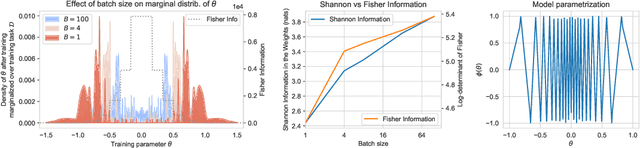
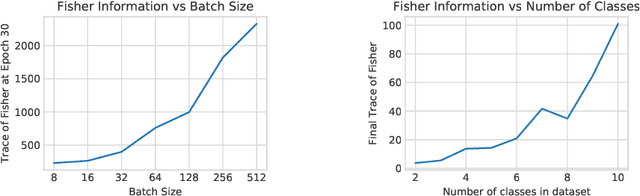
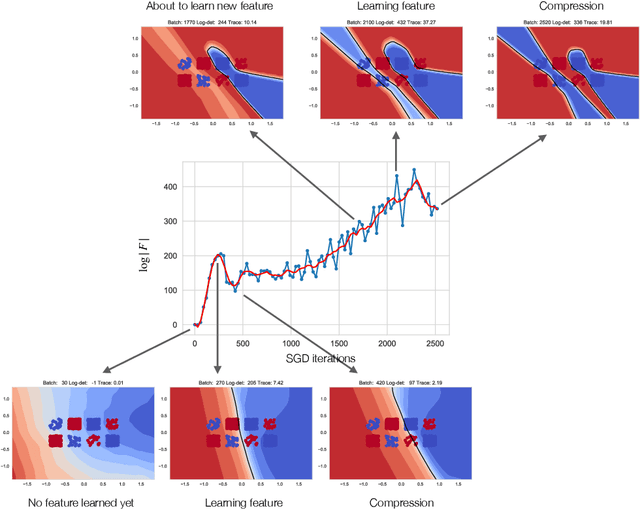
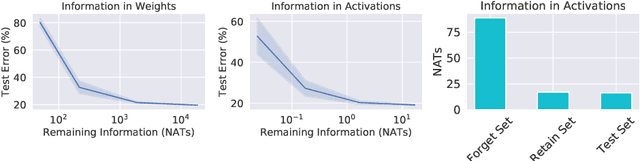
Whatever information a Deep Neural Network has gleaned from past data is encoded in its weights. How this information affects the response of the network to future data is largely an open question. In fact, even how to define and measure information in a network is still not settled. We introduce the notion of Information in the Weights as the optimal trade-off between accuracy of the network and complexity of the weights, relative to a prior. Depending on the prior, the definition reduces to known information measures such as Shannon Mutual Information and Fisher Information, but affords added flexibility that enables us to relate it to generalization, via the PAC-Bayes bound, and to invariance. This relation hinges not only on the architecture of the model, but surprisingly on how it is trained. We then introduce a notion of effective information in the activations, which are deterministic functions of future inputs, resolving inconsistencies in prior work. We relate this to the Information in the Weights, and use this result to show that models of low complexity not only generalize better, but are bound to learn invariant representations of future inputs.
Time Matters in Regularizing Deep Networks: Weight Decay and Data Augmentation Affect Early Learning Dynamics, Matter Little Near Convergence
May 30, 2019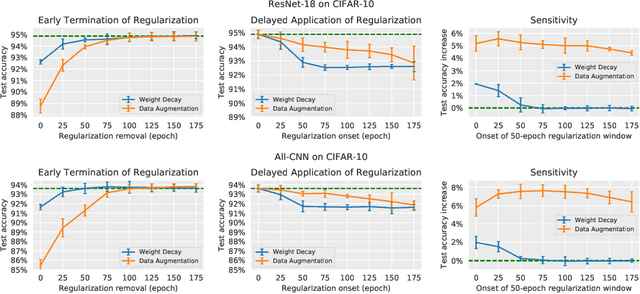
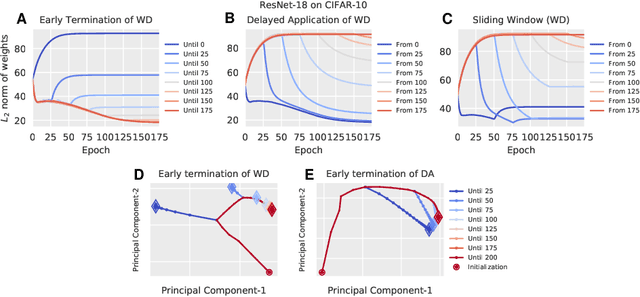
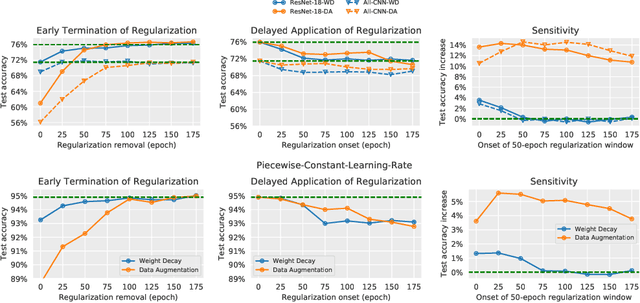
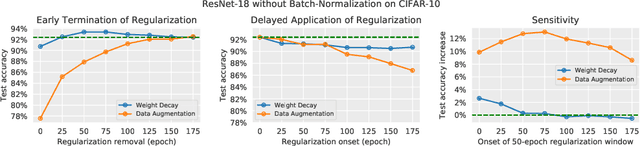
Regularization is typically understood as improving generalization by altering the landscape of local extrema to which the model eventually converges. Deep neural networks (DNNs), however, challenge this view: We show that removing regularization after an initial transient period has little effect on generalization, even if the final loss landscape is the same as if there had been no regularization. In some cases, generalization even improves after interrupting regularization. Conversely, if regularization is applied only after the initial transient, it has no effect on the final solution, whose generalization gap is as bad as if regularization never happened. This suggests that what matters for training deep networks is not just whether or how, but when to regularize. The phenomena we observe are manifest in different datasets (CIFAR-10, CIFAR-100), different architectures (ResNet-18, All-CNN), different regularization methods (weight decay, data augmentation), different learning rate schedules (exponential, piece-wise constant). They collectively suggest that there is a ``critical period'' for regularizing deep networks that is decisive of the final performance. More analysis should, therefore, focus on the transient rather than asymptotic behavior of learning.
The Information Complexity of Learning Tasks, their Structure and their Distance
Apr 05, 2019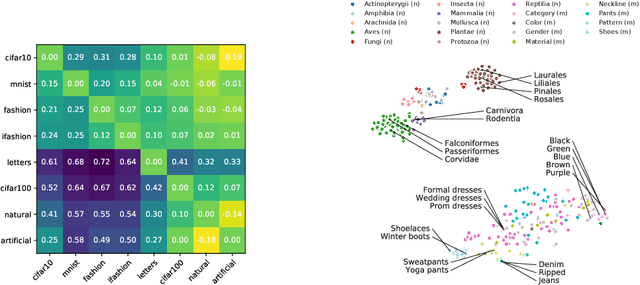
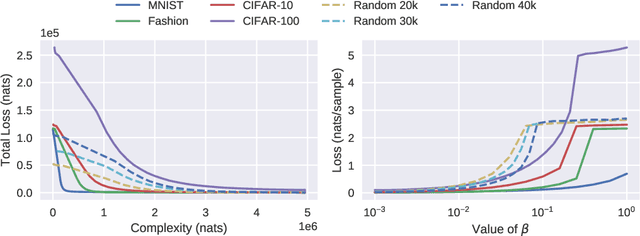
We introduce an asymmetric distance in the space of learning tasks, and a framework to compute their complexity. These concepts are foundational to the practice of transfer learning, ubiquitous in Deep Learning, whereby a parametric model is pre-trained for a task, and then used for another after fine-tuning. The framework we develop is intrinsically non-asymptotic, capturing the finite nature of the training dataset, yet it allows distinguishing learning from memorization. It encompasses, as special cases, classical notions from Kolmogorov complexity, Shannon, and Fisher Information. However, unlike some of those frameworks, it can be applied easily to large-scale models and real-world datasets. It is the first framework to explicitly account for the optimization scheme, which plays a crucial role in Deep Learning, in measuring complexity and information.
Task2Vec: Task Embedding for Meta-Learning
Feb 10, 2019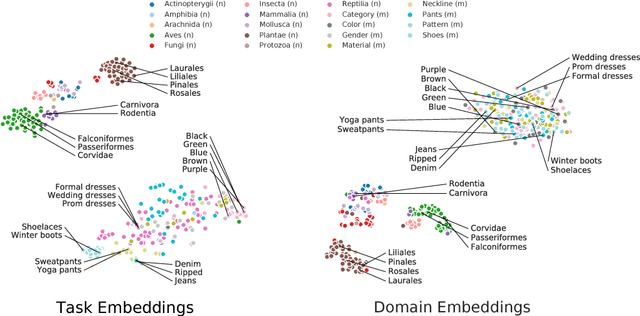
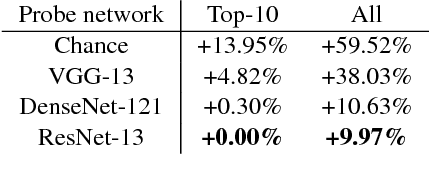
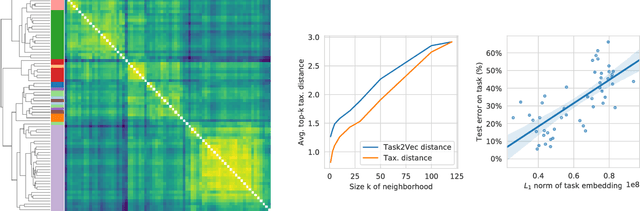

We introduce a method to provide vectorial representations of visual classification tasks which can be used to reason about the nature of those tasks and their relations. Given a dataset with ground-truth labels and a loss function defined over those labels, we process images through a "probe network" and compute an embedding based on estimates of the Fisher information matrix associated with the probe network parameters. This provides a fixed-dimensional embedding of the task that is independent of details such as the number of classes and does not require any understanding of the class label semantics. We demonstrate that this embedding is capable of predicting task similarities that match our intuition about semantic and taxonomic relations between different visual tasks (e.g., tasks based on classifying different types of plants are similar) We also demonstrate the practical value of this framework for the meta-task of selecting a pre-trained feature extractor for a new task. We present a simple meta-learning framework for learning a metric on embeddings that is capable of predicting which feature extractors will perform well. Selecting a feature extractor with task embedding obtains a performance close to the best available feature extractor, while costing substantially less than exhaustively training and evaluating on all available feature extractors.